PostgreSQL缓冲区管理器由三层组成,即缓冲表层 ,缓冲区描述符层 和缓冲池层 (图8.3):
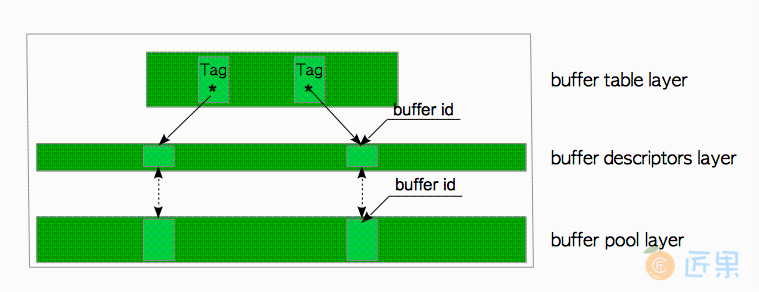
- 缓冲池(buffer pool) 层是一个数组。 每个槽都存储一个数据文件页,数组槽的索引称为
buffer_id。 - 缓冲区描述符(buffer descriptors) 层是一个由缓冲区描述符组成的数组。 每个描述符与缓冲池槽一一对应,并保存着相应槽的元数据。请注意,术语“缓冲区描述符层 ”只是在本章中为方便起见使用的术语。
- 缓冲表(buffer table) 层是一个哈希表,它存储着页面的
buffer_tag与描述符的buffer_id之间的映射关系。
这些层将在以下的节中详细描述。
8.2.1 缓冲表
缓冲表可以在逻辑上分为三个部分:散列函数,散列桶槽,以及数据项(图8.4)。
内置散列函数将buffer_tag映射到哈希桶槽。 即使散列桶槽的数量比缓冲池槽的数量要多,冲突仍然可能会发生。因此缓冲表采用了使用链表的分离链接方法(separate chaining with linked lists) 来解决冲突。 当数据项被映射到至同一个桶槽时,该方法会将这些数据项保存在一个链表中,如图8.4所示。
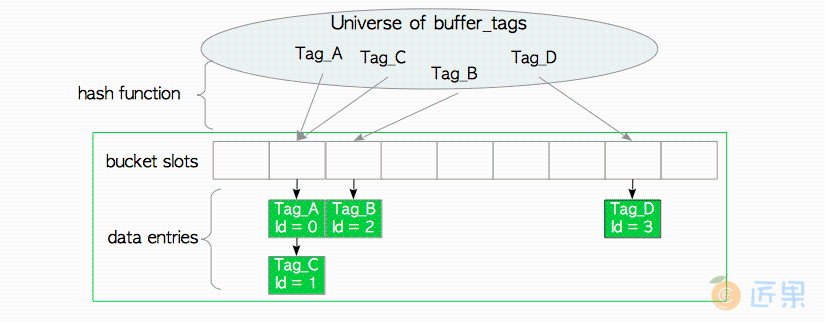
数据项包括两个值:页面的buffer_tag,以及包含页面元数据的描述符的buffer_id。例如数据项Tag_A,id=1 表示,buffer_id=1对应的缓冲区描述符中,存储着页面Tag_A的元数据。
散列函数
这里使用的散列函数是由
calc_bucket()与hash()组合而成。 下面是用伪函数表示的形式。uint32 bucket_slot = calc_bucket(unsigned hash(BufferTag buffer_tag), uint32 bucket_size)
这里还没有对诸如查找、插入、删除数据项的基本操作进行解释。这些常见的操作将在后续小节详细描述。
8.2.2 缓冲区描述符
本节将描述缓冲区描述符的结构, 下一小节 将描述缓冲区描述符层。
缓冲区描述符 保存着页面的元数据,这些与缓冲区描述符相对应的页面保存在缓冲池槽中。缓冲区描述符的结构由BufferDesc结构定义。这个结构有很多字段,主要字段如下所示:
/* src/include/storage/buf_internals.h (before 9.6) */
/* 缓冲区描述符的标记位定义(since 9.6)
* 注意:TAG_VALID实际上意味着缓冲区哈希表中有一条与本tag关联的项目。
*/
#define BM_DIRTY (1 << 0) /* 数据需要写入 */
#define BM_VALID (1 << 1) /* 数据有效 */
#define BM_TAG_VALID (1 << 2) /* 已经分配标签 */
#define BM_IO_IN_PROGRESS (1 << 3) /* 读写进行中 */
#define BM_IO_ERROR (1 << 4) /* 先前的I/O失败 */
#define BM_JUST_DIRTIED (1 << 5) /* 写之前已经脏了 */
#define BM_PIN_COUNT_WAITER (1 << 6) /* 有人等着钉页面 */
#define BM_CHECKPOINT_NEEDED (1 << 7) /* 必需在检查点时写入 */
#define BM_PERMANENT (1 << 8) /* 永久缓冲(不是unlogged) */
/* BufferDesc -- 单个共享缓冲区的共享描述符/共享状态
*
* 注意: 读写tag, flags, usage_count, refcount, wait_backend_pid等字段时必须持有
* buf_hdr_lock锁。buf_id字段在初始化之后再也不会改变,所以不需要锁。freeNext是通过
* buffer_strategy_lock来保护的,而不是buf_hdr_lock。LWLocks字段可以自己管好自己。
* 注意buf_hdr_lock *不是* 用来控制对缓冲区内数据的访问的!
*
* 一个例外是,如果我们固定了(pinned)缓冲区,它的标签除了我们自己之外不会被偷偷修改。
* 所以我们无需锁定自旋锁就可以检视该标签。此外,一次性的标记读取也无需锁定自旋锁,
* 当我们期待测试标记位不会改变时,这种做法很常见。
*
* 如果另一个后端固定了该缓冲区,我们就无法从磁盘页面上物理移除项目了。因此后端需要等待
* 所有其他的钉被移除。移除时它会得到通知,这是通过将它的PID存到wait_backend_pid,
* 并设置BM_PIN_COUNT_WAITER标记为而实现的。就目前而言,每个缓冲区只能有一个等待者。
*
* 对于本地缓冲区,我们也使用同样的首部,不过锁字段就没用了,一些标记位也没用了。
*/
typedef struct sbufdesc
{
BufferTag tag; /* 存储在缓冲区中页面的标识 */
BufFlags flags; /* 标记位 */
uint16 usage_count; /* 时钟扫描要用到的引用计数 */
unsigned refcount; /* 在本缓冲区上持有pin的后端进程数 */
int wait_backend_pid; /* 等着Pin本缓冲区的后端进程PID */
slock_t buf_hdr_lock; /* 用于保护上述字段的锁 */
int buf_id; /* 缓冲的索引编号 (从0开始) */
int freeNext; /* 空闲链表中的链接 */
LWLockId io_in_progress_lock; /* 等待I/O完成的锁 */
LWLockId content_lock; /* 访问缓冲区内容的锁 */
} BufferDesc;
tag保存着目标页面的buffer_tag,该页面存储在相应的缓冲池槽中(缓冲区标签的定义在【8.1.2节】给出)。buffer_id标识了缓冲区描述符(亦相当于对应缓冲池槽的buffer_id)。refcount保存当前访问相应页面的PostgreSQL进程数,也被称为钉数(pin count) 。当PostgreSQL进程访问相应页面时,其引用计数必须自增1(refcount ++)。访问结束后其引用计数必须减1(refcount--)。 当refcount为零,即页面当前并未被访问时,页面将取钉(unpinned) ,否则它会被钉住(pinned) 。usage_count保存着相应页面加载至相应缓冲池槽后的访问次数。usage_count会在页面置换算法中被用到(【第8.4.4节】)。context_lock和 **io_in_progress_lock**是轻量级锁,用于控制对相关页面的访问。【第8.3.2节】将介绍这些字段。flags用于保存相应页面的状态,主要状态如下:- 脏位(
dirty bit) 指明相应页面是否为脏页。 - 有效位(
valid bit) 指明相应页面是否可以被读写(有效)。例如,如果该位被设置为"valid",那就意味着对应的缓冲池槽中存储着一个页面,而该描述符中保存着该页面的元数据,因而可以对该页面进行读写。反之如果有效位被设置为"invalid",那就意味着该描述符中并没有保存任何元数据;即,对应的页面无法读写,缓冲区管理器可能正在将该页面换出。 - IO进行标记位(
io_in_progress) 指明缓冲区管理器是否正在从存储中读/写相应页面。换句话说,该位指示是否有一个进程正持有此描述符上的io_in_pregress_lock。
- 脏位(
freeNext是一个指针,指向下一个描述符,并以此构成一个空闲列表(freelist),细节在 下一小节 中介绍。
结构
BufferDesc定义于src/include/storage/buf_internals.h中。
为了简化后续章节的描述,这里定义三种描述符状态:
- 空(
Empty) :当相应的缓冲池槽不存储页面(即refcount与usage_count都是0),该描述符的状态为空 。 - 钉住(
Pinned) :当相应缓冲池槽中存储着页面,且有PostgreSQL进程正在访问的相应页面(即refcount和usage_count都大于等于1),该缓冲区描述符的状态为钉住 。 - 未钉住(
Unpinned) :当相应的缓冲池槽存储页面,但没有PostgreSQL进程正在访问相应页面时(即usage_count大于或等于1,但refcount为0),则此缓冲区描述符的状态为未钉住 。
每个描述符都处于上述状态之一。描述符的状态会根据特定条件而改变,这将在下一小节中描述。
在下图中,缓冲区描述符的状态用彩色方框表示。
- \({□}\)(白色)空
- \(\color{blue}{█}\)(蓝色)钉住
- \(\color{cyan}{█}\)(青色)未钉住
此外,脏页面会带有“X”的标记。例如一个未固定的脏描述符用 \(\color{cyan}☒\) 表示。
8.2.3 缓冲区描述符层
缓冲区描述符的集合构成了一个数组。本书称该数组为缓冲区描述符层(buffer descriptors layer) 。
当PostgreSQL服务器启动时,所有缓冲区描述符的状态都为空 。在PostgreSQL中,这些描述符构成了一个名为 freelist 的链表,如图8.5所示。
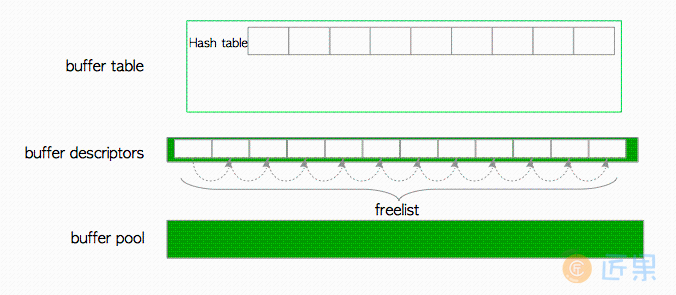
请注意PostgreSQL中的
freelist完全不同于Oracle中freelists的概念。PostgreSQL的freelist只是空缓冲区描述符的链表。PostgreSQL中与Oracle中的freelist相对应的对象是空闲空间映射(FSM)( 第5.3.4节 )。
图8.6展示了第一个页面是如何加载的。
- 从
freelist的头部取一个空描述符,并将其钉住(即,将其refcount和usage_count增加1)。 - 在缓冲表中插入新项,该缓冲表项保存了页面
buffer_tag与所获描述符buffer_id之间的关系。 - 将新页面从存储器加载至相应的缓冲池槽中。
- 将新页面的元数据保存至所获取的描述符中。
第二页,以及后续页面都以类似方式加载,其他细节将在第8.4.2节中介绍。
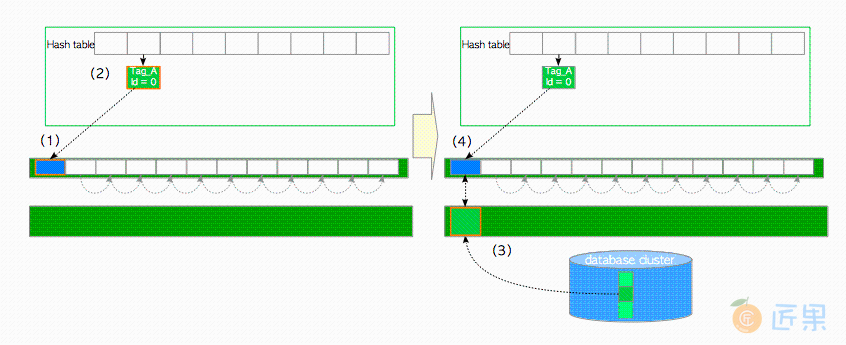
从freelist中摘出的描述符始终保存着页面的元数据。换而言之,仍然在使用的非空描述符不会返还到freelist中。但当下列任一情况出现时,描述符状态将变为“空”,并被重新插入至freelist中:
- 相关表或索引已被删除。
- 相关数据库已被删除。
- 相关表或索引已经被
VACUUM FULL命令清理了。
为什么使用
freelist来维护空描述符?保留
freelist的原因是为了能立即获取到一个描述符。这是内存动态分配的常规做法,详情参阅这里的说明。
缓冲区描述符层 包含着一个32位无符号整型变量 nextVictimBuffer。此变量用于【8.4.4节】将介绍的页面置换算法。
8.2.4 缓冲池
缓冲池只是一个用于存储关系数据文件(例如表或索引)页面的简单数组。缓冲池数组的序号索引也就是buffer_id。
缓冲池槽的大小为8KB,等于页面大小,因而每个槽都能存储整个页面。