本节将说明多表查询计划树的创建过程。
3.6.1 预处理
预处理由planner.c中定义的subquery_planner()函数执行。第3.3.1节已经描述了单表查询的预处理。本节将描述多表查询的预处理;尽管这块内容很多,但这里只会挑其中一部分来讲。
- 对CTE进行计划与转换
如果存在
WITH列表,计划器就会通过SS_process_ctes()函数对每个WITH查询进行处理。 - 上拉子查询
如果
FROM子句带有一个子查询,且该子查询没用用到GROUP BY,HAVING,ORDER BY,LIMIT和DISTINCT,INTERSECT或EXCEPT,那么计划器会使用pull_up_subqueries()函数将其转换为连接形式。例如下面一个FROM子句含子查询的查询就可以被转换为自然连接查询。自不必说,这种转换是在查询树上进行的。# SELECT * FROM tbl_a AS a, (SELECT * FROM tbl_b) as b WHERE a.id = b.id; ↓ # SELECT * FROM tbl_a AS a, tbl_b as b WHERE a.id = b.id; - 将外连接转为内连接
如果可能的话,计划器会将
OUTER JOIN查询转换为INNER JOIN查询。
3.6.2 获取代价最小的路径
为了获取最佳计划树,计划器必须考虑各个索引与各种连接方法之间的所有可能组合。 如果表的数量超过某个水平,该过程的代价就会因为组合爆炸而变得非常昂贵,以至于根本不可行。
幸运的是,如果表的数量小于12张,计划器可以使用动态规划来获取最佳计划; 否则计划器会使用遗传算法。详情如下:
基因查询优化器
当执行一个多表连接查询时,大量时间耗费在了优化查询计划上。 为了应对这种情况,PostgreSQL实现了一个有趣的功能:基因查询优化器。 这种近似算法能在合理时间内确定一个合理的计划。 因此在查询优化阶段,如果参与连接的表数量超过参数
geqo_threshold指定的阈值(默认值为12),PostgreSQL将使用遗传算法来生成查询计划。
使用动态规划确定最佳计划树的过程,其步骤如下:
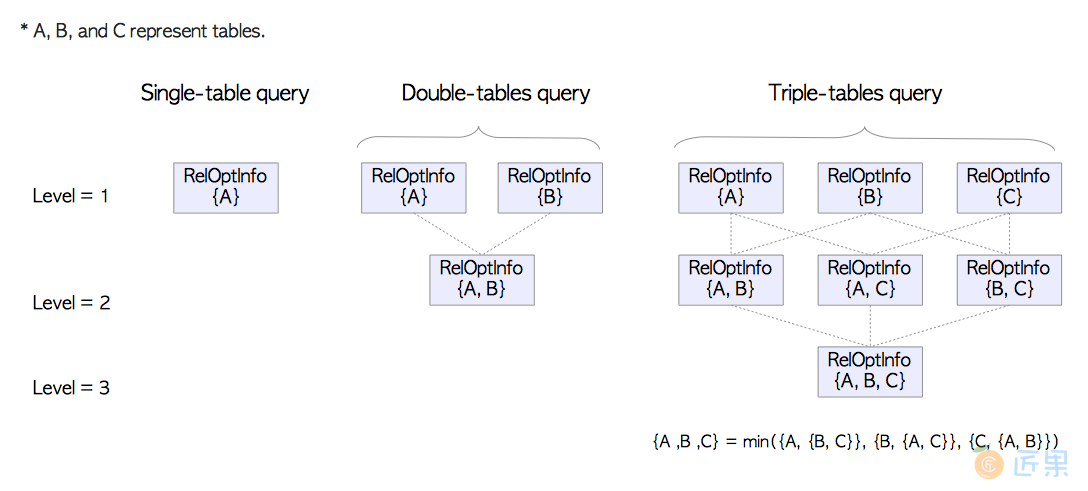
- 第一层
获得每张表上代价最小的路径,代价最小的路径存储在表相应的
RelOptInfo结构中。 - 第二层
从所有表中选择两个表,为每种组合找出代价最低的路径。
举个例子,如果总共有两张表,表
A与表B,则表A和B表连接的各种路径中,代价最小的那条即为最终想要的答案。在下文中,两个表的RelOptInfo记做${A,B}$。 如果有三个表,则需要获取${A,B}, {A,C},{B,C}$三种组合里各自代价最小的路径。 - 第三层及其后 继续进行同样的处理,直到层级等于表数量。
通过这种方式,在每个层级都能解决最小代价问题的一部分,且其结果能被更高层级的计算复用,从而使代价最小的计划树能够被高效地计算出来。
接下来会针对下面的查询,解释计划器是如何获取代价最小的计划的。
testdb=# \d tbl_a
Table "public.tbl_a"
Column | Type | Modifiers
--------+---------+-----------
id | integer | not null
data | integer |
Indexes:
"tbl_a_pkey" PRIMARY KEY, btree (id)
testdb=# \d tbl_b
Table "public.tbl_b"
Column | Type | Modifiers
--------+---------+-----------
id | integer |
data | integer |
testdb=# SELECT * FROM tbl_a AS a, tbl_b AS b WHERE a.id = b.id AND b.data < 400;
3.6.2.1 第一层的处理
在第一层中,计划器会为查询中涉及的关系创建相应的RelOptInfo结构,并估计每个关系上的最小代价。 在这一步中,RelOptInfo结构会被添加至该查询对应PlannerInfo的simple_rel_arrey数组字段中。
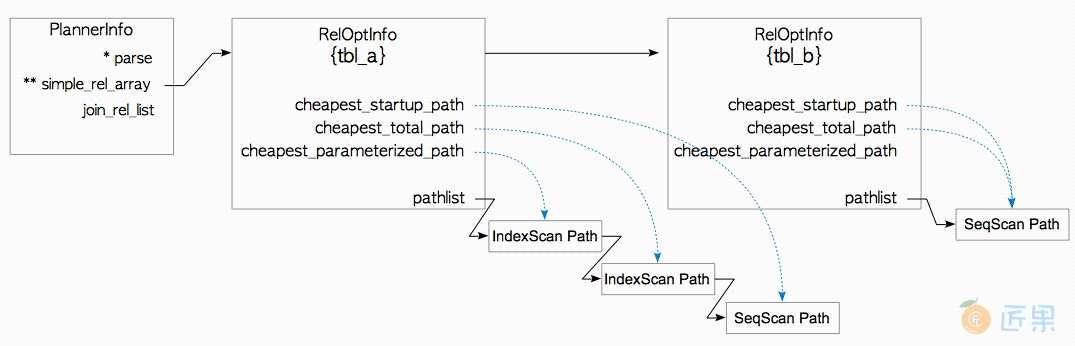
PlannerInfo与RelOptInfo
表tbl_a的RelOptInfo有三条访问路径,它们被添加至RelOptInfo的路径列表中。这三条路径分别被三个指针所链接,即三个指向代价最小路径的指针:启动代价最小的路径,总代价最小的路径,参数化代价最小的路径。 启动代价最小的路径与总代价最小的路径涵义显而易见,因此,这里只会说一下参数化索引扫描代价最小的路径(cheapest parameterized index scan path) 。
如3.5.1.3节所述,计划器会考虑为索引嵌套循环连接使用参数化路径(parameterized path) (极少数情况下也会用于带外表索引扫描的索引化归并连接)。参数化索引扫描代价最小的路径,就是所有参数化路径中代价最小的那个。
表tbl_b的RelOptInfo仅有顺序扫描访问路径,因为tbl_b上没有相关索引。
3.6.2.2 第二层的处理
在第二层中,计划器会在PlannerInfo的join_rel_list字段中创建一个RelOptInfo结构。 然后估计所有可能连接路径的代价,并且选择代价最小的那条访问路径。 RelOptInfo会将最佳访问路径作为总代价最小的路径, 如图3.33所示。
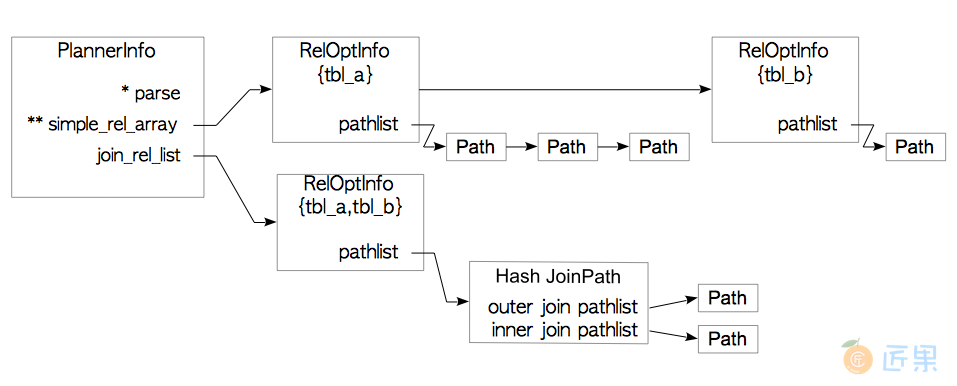
PlannerInfo和RelOptInfo
表3.1展示了本例中连接访问路径的所有组合。本例中查询的连接类型为等值连接(equi-join) ,因而对全部三种连接算法进行评估。 为方便起见,这里引入了一些有关访问路径的符号:
SeqScanPath(table)表示表table上的顺序扫描路径。Materialized -> SeqScanPath(table)表示表table上的物化顺序扫描路径。IndexScanPath(table,attribute)表示按表table中属性attribute上的索引扫描路径。ParameterizedIndexScanPath(table,attribute1,attribute2)表示表table中属性attribute1上的参数化索引路径,并使用外表上的属性attribute2参数化。
表 3.1 此示例中的所有连接访问路径组合
嵌套循环连接
| 外表路径 | 内表路径 | 备注 |
|---|---|---|
SeqScanPath(tbl_a) |
SeqScanPath(tbl_b) |
|
SeqScanPath(tbl_a) |
Materialized -> SeqScanPath(tbl_b) |
物化嵌套循环链接 |
IndexScanPath(tbl_a,id) |
SeqScanPath(tbl_b) |
嵌套循环连接,走外表索引 |
IndexScanPath(tbl_a,id) |
Materialized -> SeqScanPath(tbl_b) |
物化嵌套循环连接,走外表索引 |
SeqScanPath(tbl_b) |
SeqScanPath(tbl_a) |
|
SeqScanPath(tbl_b) |
Materialized -> SeqScanPath(tbl_a) |
物化嵌套循环连接 |
SeqScanPath(tbl_b) |
ParametalizedIndexScanPath(tbl_a, id, tbl_b.id) |
索引嵌套循环连接 |
归并连接
| 外表路径 | 内表路径 | 备注 |
|---|---|---|
SeqScanPath(tbl_a) |
SeqScanPath(tbl_b) |
|
IndexScanPath(tbl_a,id) |
SeqScanPath(tbl_b) |
用外表索引做归并连接 |
SeqScanPath(tbl_b) |
SeqScanPath(tbl_a) |
哈希连接
| 外表路径 | 内表路径 | 备注 |
|---|---|---|
SeqScanPath(tbl_a) |
SeqScanPath(tbl_b) |
|
SeqScanPath(tbl_b) |
SeqScanPath(tbl_a) |
例如在嵌套循环连接的部分总共评估了七条连接路径。 第一条表示在外表tbl_a和内表tbl_b上都使用顺序扫描路径;第二条表示在外表tbl_a上使用路径顺序扫描路径,而在内表tbl_b上使用物化顺序扫描路径,诸如此类。
计划器最终从估计的连接访问路径中选择代价最小的那条,并且将其添加至RelOptInfo{tbl_a,tbl_b}的路径列表中,如图3.33所示。
在本例中,如下面EXPLAIN的结果所示,计划器选择了在内表tbl_b和外表tbl_c上进行散列连接。
testdb=# EXPLAIN SELECT * FROM tbl_b AS b, tbl_c AS c WHERE c.id = b.id AND b.data < 400;
QUERY PLAN
----------------------------------------------------------------------
Hash Join (cost=90.50..277.00 rows=400 width=16)
Hash Cond: (c.id = b.id)
-> Seq Scan on tbl_c c (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=85.50..85.50 rows=400 width=8)
-> Seq Scan on tbl_b b (cost=0.00..85.50 rows=400 width=8)
Filter: (data < 400)
(6 rows)
3.6.3 获取三表查询代价最小的路径
涉及三个表的查询,其代价最小的路径的获取过程如下所示:
testdb=# \d tbl_a
Table "public.tbl_a"
Column | Type | Modifiers
--------+---------+-----------
id | integer |
data | integer |
testdb=# \d tbl_b
Table "public.tbl_b"
Column | Type | Modifiers
--------+---------+-----------
id | integer |
data | integer |
testdb=# \d tbl_c
Table "public.tbl_c"
Column | Type | Modifiers
--------+---------+-----------
id | integer | not null
data | integer |
Indexes:
"tbl_c_pkey" PRIMARY KEY, btree (id)
testdb=# SELECT * FROM tbl_a AS a, tbl_b AS b, tbl_c AS c
testdb-# WHERE a.id = b.id AND b.id = c.id AND a.data < 40;
- 第一层:
计划器估计所有表上各自开销最小的路径,并将该信息存储在表相应的
RelOptInfos结构{tbl_a},{tbl_b},{tbl_c}中。 - 第二层:
计划器从三个表中选出两个,列出所有组合,分别评估每种组合里代价最小的路径。然后,规划器将信息存储在组合相应的
RelOptInfos结构中:{tbl_a,tbl_b},{tbl_b,tbl_c}和{tbl_a,tbl_c}中。 - 第三层:
计划器根据所有已获取的
RelOptInfos,选择代价最小的路径。更确切地说,计划器会考虑三种RelOptInfos组合:{tbl_a,{tbl_b,tbl_c}},{tbl_b,{tbl_a,tbl_c}}和{tbl_c,{tbl_a,tbl_b}},而{tbl_a,tbl_b,tbl_c}计划器会估算这里面所有可能连接路径的代价。
在处理{tbl_c,{tbl_a,tbl_b}}对应的RelOptInfo时,计划器会估计tbl_c和{tbl_a,tbl_b}连接代价最小的路径。本例中{tbl_a,tbl_b}已经选定为内表为tbl_a且外表为tbl_b的散列连接。如先前小节所述,在估计时三种连接算法及其变体都会被评估,即嵌套循环连接及其变体,归并连接及其变体,散列连接及其变体。
计划器以同样的方式处理{tbl_a,{tbl_b,tbl_c}}与{tbl_b,{tbl_a,tbl_c}}对应的RelOptInfo,并最终从所有估好的路径中选择代价最小的访问路径。
该查询的EXPLAIN命令结果如下所示:

最外层的连接是索引嵌套循环连接(第5行),第13行显示了内表上的参数化索引扫描,外表则是一个散列连接的结果该散列连接的内表是tbl_a,外表是tbl_b(第7-12行)。 因此,执行程序首先执行tbl_a和tbl_b上的散列连接,再执行索引嵌套循环连接。
下一节:2003年,SQL标准中添加了一个访问远程数据的规范,称为SQL外部数据管理(SQL/MED)。PostgreSQL在9.1版本开发出了FDW,实现了一部分SQL/MED中的特性。