当SELECT语句的所有的目标列都在索引键中时,为了减少I/O代价,仅索引扫描(Index-Only Scan)(又叫仅索引访问)会直接使用索引中的键值。所有商业关系型数据库中都提供这个技术,比如DB2和Oracle。PostgreSQL在9.2版本中引入这个特性。
接下来我们会基于一个特殊的例子,介绍PostgreSQL中仅索引扫描的工作过程。首先是关于这个例子的假设:
- 表定义
我们有一个
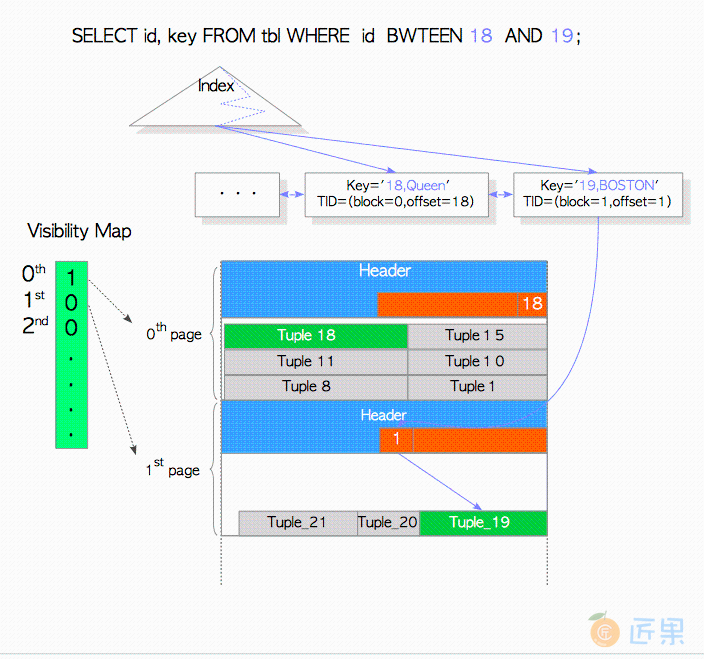
tbl表,其定义如下所示:testdb=# \d tbl Table "public.tbl" Column | Type | Modifiers --------+---------+----------- id | integer | name | text | data | text | Indexes: "tbl_idx" btree (id, name) - 索引
表
tbl有一个索引tbl_idx,包含两列:id和name。 - 元组
tbl已经插入了一些元组。id=18, name = 'Queen'的Tuple_18存储在0号数据页中。id=19, name='BOSTON'的Tuple_19存储在1号数据页中。 - 可见性 所有在0号页面中的元组永远可见;1号页面中的元组并不总是可见的。注意每个页的可见性信息都存储在相应的可见性映射(visibility map) 中,关于可见性映射的描述可以参考 6.2 可见性映射 。
我们来研究一下,当下面的SELECT语句执行时,PostgreSQL是如何读取元组的。
testdb=# SELECT id, name FROM tbl WHERE id BETWEEN 18 and 19;
id | name
----+--------
18 | Queen
19 | Boston
(2 rows)
查询需要从表中读取两列:id和name,然而索引tbl_idx包含了这些列。因此在使用索引扫描时,第一眼看上去好像访问表的页面是没有必要的,因为索引中已经包含了必要的数据。然而原则上,PostgreSQL有必要需要检查这些元组的可见性,然而索引元组中并没有任何关于堆元组的事务相关信息,比如t_xmin和t_xmax,详细参考 第五章 并发控制 。因此,PostgreSQL需要访问表数据来检查索引元组中数据的可见性,这就有点本末倒置了。
面对这种困境,PostgreSQL使用目标数据表对应的可见性映射表来解决此问题。如果某一页中存储所有的元组都是可见的,PostgreSQL就会使用索引元组,而不去访问索引元组指向的数据页去检查可见性;否则,PostgreSQL读取索引元组指向的数据元组并检查元组可见性,而这个就跟原来设想的一样。
在这个例子中,因为的0号页面被标记为可见,因此0号页面中存储的包括Tuple_18在内的所有元组都是可见的,所以就无需再去访问Tuple_18了。相应的,因为1号页面并没有被标记为可见,此时为了检查并发控制的可见性,需要访问Tuple_19。
下一节:这是PostgreSQL官方文档中关于HOT的介绍。