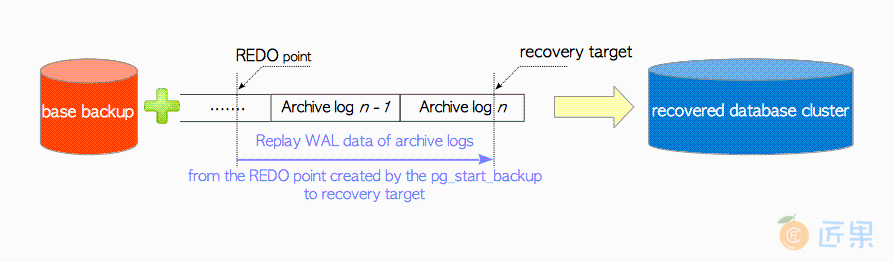
图10.2展示了PITR的基本概念。 PITR模式下的PostgreSQL会在基础备份上重放归档日志中的WAL数据,从pg_start_backup创建的重做点开始,恢复至你想要的位置为止。在PostgreSQL中,要恢复到的位置,被称为恢复目标(recovery target) 。
PITR是这样工作的。假设你在GMT时间2018-07-16 12:05:00搞出了错误。那你应该删掉当前的数据库集簇,并使用之前制作的基础备份恢复一个新的出来。然后,创建一个recovery.conf文件,并在其中将参数recovery_target_time参数配置为你犯错误的时间点(在本例中,也就是12:05 GMT) 。recovery.conf文件如下所示:
# Place archive logs under /mnt/server/archivedir directory.
restore_command = 'cp /mnt/server/archivedir/%f %p'
recovery_target_time = "2018-7-16 12:05 GMT"
当PostgreSQL启动的时候,如果数据库集簇中存在recovery.conf和backup_label文件,它就会进入恢复模式。
PITR过程几乎与 第九章 预写式日志——WAL 中描述的常规恢复过程一模一样,唯一的区别只有以下两点:
- 从哪里读取WAL段/归档日志?
- 正常恢复模式 —— 来自基础目录下的
pg_xlog子目录(10或更新版本,pg_wal子目录)。 - PITR模式 —— 来自配置参数
archive_command中设置的归档目录。
- 正常恢复模式 —— 来自基础目录下的
- 从哪里读取检查点位置?
- 正常恢复模式 —— 来自
pg_control文件。 - PITR模式 —— 来自
backup_label文件。
- 正常恢复模式 —— 来自
PITR流程概述如下:
- 为了找到重做点,PostgreSQL使用内部函数
read_backup_label从backup_label文件中读取CHECKPOINT LOCATION的值。 - PostgreSQL从
recovery.conf中读取一些参数值;在此示例中为restore_command和recovery_target_time。 - PostgreSQL开始从重做点重放WAL数据,重做点的位置可以简单地从
CHECKPOINT LOCATION的值中获得。 PostgreSQL执行参数restore_command中配置的命令,将归档日志从归档区域拷贝到临时区域,并从中读取WAL数据(复制到临时区域中的日志文件会在使用后删除)。 在本例中,PostgreSQL从重做点读取并重放WAL数据,直到时间戳2018-7-16 12:05:00为止,因为参数recovery_target_time被设置为该时间戳。如果recovery.conf中没有配置恢复目标,则PostgreSQL将重放至归档日志的末尾。 - 当恢复过程完成时,会在
pg_xlog子目录(10或更高版本为pg_wal子目录)中创建时间线历史文件,例如00000002.history;如果启用了日志归档功能,则还会在归档目录中创建相同的命名文件。以下各节介绍了此文件的内容和作用。
提交和中止操作的记录包含每个操作完成时的时间戳(两个操作的XLOG数据部分分别在xl_xact_commit和xl_xact_abort中定义)。因此,如果将目标时间设置为参数recovery_target_time,只要PostgreSQL重放提交或中止操作的XLOG记录,它可以选择是否继续恢复。当重放每个动作的XLOG记录时,PostgreSQL会比较目标时间和记录中写入的每个时间戳;如果时间戳超过目标时间,PITR过程将完成。
typedef struct xl_xact_commit
{
TimestampTz xact_time; /* 提交时间 */
uint32 xinfo; /* 信息标记位 */
int nrels; /* RelFileNodes的数量 */
int nsubxacts; /* 子事务XIDs的数量 */
int nmsgs; /* 共享失效消息的数量 */
Oid dbId; /* MyDatabaseId, 数据库Oid */
Oid tsId; /* MyDatabaseTableSpace, 表空间Oid */
/* 在提交时需要丢弃的RelFileNode(s)数组 */
RelFileNode xnodes[1]; /* 变长数组 */
/* 紧接着已提交的子事务XIDs数组 */
/* 紧接着共享失效消息的数组 */
} xl_xact_commit;
typedef struct xl_xact_abort
{
TimestampTz xact_time; /* 中止时间 */
int nrels; /* RelFileNodes的数量 */
int nsubxacts; /* 子事务XIDs的数量 */
/* 在中止时需要丢弃的RelFileNode(s)数组 */
RelFileNode xnodes[1]; /* 变长数组 */
/* 紧接着已提交的子事务XIDs数组 */
} xl_xact_abort;
函数
read_backup_label定义于src/backend/access/transam/xlog.c中。 结构xl_xact_commit和xl_xact_abort定义于src/backend/access/transam/xlog.c。为什么可以用一般归档工具做基础备份?
尽管数据库集簇可能是不一致的,但恢复过程是使数据库集簇达成一致状态的过程。由于PITR是基于恢复过程的,所以即使基础备份是一堆不一致的文件,它也可以恢复数据库集簇。因此我们可以在没有文件系统快照功能,或其他特殊工具的情况下,使用一般归档工具做基础备份。
下一节:PostgreSQL中的时间线用于区分原始数据库集簇和恢复生成的数据库集簇,它是PITR的核心概念。在本节中,描述了与时间线相关的两件事:时间线标识(TimelineID),以及时间线历史文件(Timeline History Files)。