本节介绍缓冲区管理器的工作原理。当后端进程想要访问所需页面时,它会调用ReadBufferExtended函数。
函数ReadBufferExtended的行为依场景而异,在逻辑上具体可以分为三种情况。每种情况都将用一小节介绍。最后一小节将介绍PostgreSQL中基于时钟扫描(clock-sweep)的页面置换算法。
8.4.1 访问存储在缓冲池中的页面
首先来介绍最简单的情况,即,所需页面已经存储在缓冲池中。在这种情况下,缓冲区管理器会执行以下步骤:
- 创建所需页面的
buffer_tag(在本例中buffer_tag是'Tag_C'),并使用散列函数计算与描述符相对应的散列桶槽。 - 获取相应散列桶槽分区上的
BufMappingLock共享锁(该锁将在步骤(5)中被释放)。 - 查找标签为
"Tag_C"的条目,并从条目中获取buffer_id。本例中buffer_id为2。 - 将
buffer_id=2的缓冲区描述符钉住,即将描述符的refcount和usage_count增加1(8.3.2节描述了钉住)。 - 释放
BufMappingLock。 - 访问
buffer_id=2的缓冲池槽。
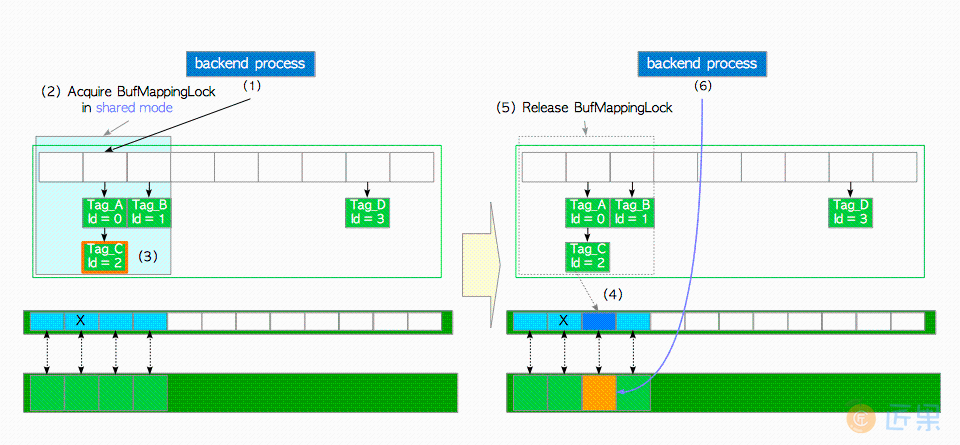
然后,当从缓冲池槽中的页面里读取行时,PostgreSQL进程获取相应缓冲区描述符的共享content_lock。因而缓冲池槽可以同时被多个进程读取。
当向页面插入(及更新、删除)行时,该postgres后端进程获取相应缓冲区描述符的独占content_lock(注意这里必须将相应页面的脏位置位为"1")。
访问完页面后,相应缓冲区描述符的引用计数值减1。
8.4.2 将页面从存储加载至空槽
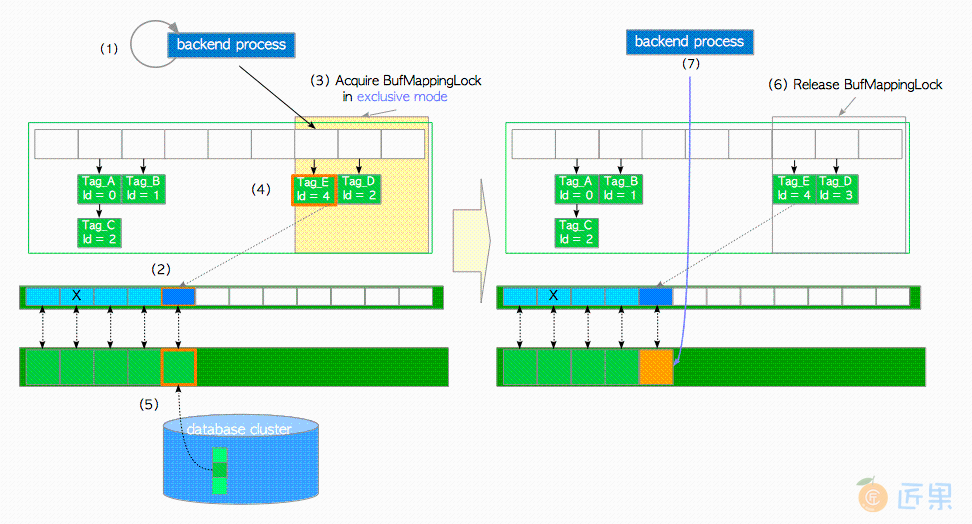
在第二种情况下,假设所需页面不在缓冲池中,且freelist中有空闲元素(空描述符)。在这种情况下,缓冲区管理器将执行以下步骤:
- 查找缓冲区表(本节假设页面不存在,找不到对应页面)。
- 创建所需页面的
buffer_tag(本例中buffer_tag为'Tag_E')并计算其散列桶槽。 - 以共享模式获取相应分区上的
BufMappingLock。 - 查找缓冲区表(根据假设,这里没找到)。
- 释放
BufMappingLock。
- 创建所需页面的
- 从
freelist中获取空缓冲区描述符 ,并将其钉住。在本例中所获的描述符buffer_id=4。 - 以独占 模式获取相应分区的
BufMappingLock(此锁将在步骤(6)中被释放)。 - 创建一条新的缓冲表数据项:
buffer_tag='Tag_E’, buffer_id=4,并将其插入缓冲区表中。 - 将页面数据从存储加载至
buffer_id=4的缓冲池槽中,如下所示:- 以排他模式获取相应描述符的
io_in_progress_lock。 - 将相应描述符的
IO_IN_PROGRESS标记位设置为1,以防其他进程访问。 - 将所需的页面数据从存储加载到缓冲池插槽中。
- 更改相应描述符的状态;将
IO_IN_PROGRESS标记位置位为"0",且VALID标记位被置位为"1"。 - 释放
io_in_progress_lock。
- 以排他模式获取相应描述符的
- 释放相应分区的
BufMappingLock。 - 访问
buffer_id=4的缓冲池槽。
8.4.3 将页面从存储加载至受害者缓冲池槽中
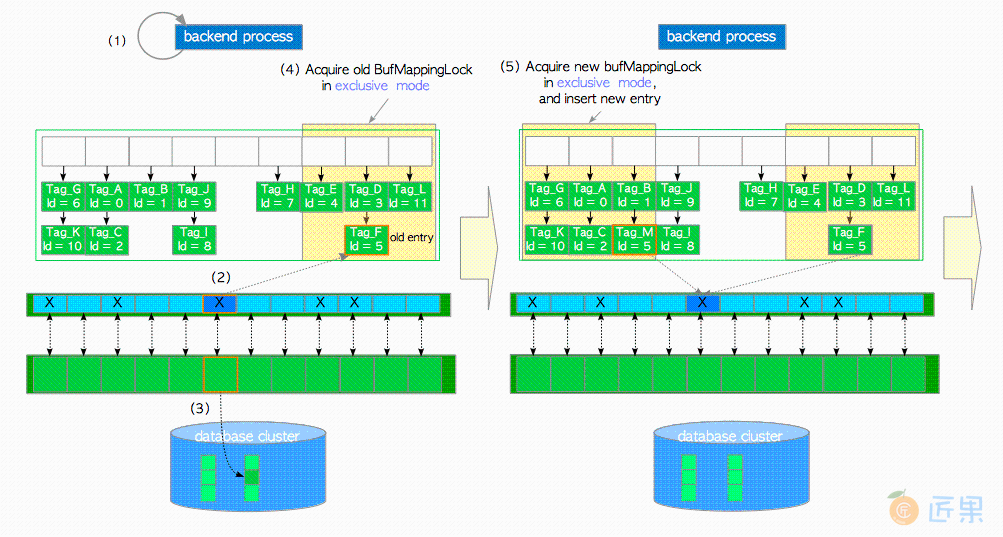
在这种情况下,假设所有缓冲池槽位都被页面占用,且未存储所需的页面。缓冲区管理器将执行以下步骤:
- 创建所需页面的
buffer_tag并查找缓冲表。在本例中假设buffer_tag是'Tag_M'(且相应的页面在缓冲区中找不到)。 - 使用时钟扫描算法选择一个受害者缓冲池槽位,从缓冲表中获取包含着受害者槽位
buffer_id的旧表项,并在缓冲区描述符层将受害者槽位的缓冲区描述符钉住。本例中受害者槽的buffer_id=5,旧表项为Tag_F, id = 5。时钟扫描将在下一节中介绍。 - 如果受害者页面是脏页,将其刷盘(
write & fsync),否则进入步骤(4)。 在使用新数据覆盖脏页之前,必须将脏页写入存储中。脏页的刷盘步骤如下:- 获取
buffer_id=5描述符上的共享content_lock和独占io_in_progress_lock(在步骤6中释放)。 - 更改相应描述符的状态:相应
IO_IN_PROCESS位被设置为"1",JUST_DIRTIED位设置为"0"。 - 根据具体情况,调用
XLogFlush()函数将WAL缓冲区上的WAL数据写入当前WAL段文件(详细信息略,WAL和XLogFlush函数在 第九章 预写式日志——WAL 中介绍)。 - 将受害者页面的数据刷盘至存储中。
- 更改相应描述符的状态;将
IO_IN_PROCESS位设置为"0",将VALID位设置为"1"。 - 释放
io_in_progress_lock和content_lock。
- 获取
- 以排他模式获取缓冲区表中旧表项所在分区上的
BufMappingLock。 - 获取新表项所在分区上的
BufMappingLock,并将新表项插入缓冲表:- 创建由新表项:由
buffer_tag='Tag_M'与受害者的buffer_id组成的新表项。 - 以独占模式获取新表项所在分区上的
BufMappingLock。 - 将新表项插入缓冲区表中。
- 创建由新表项:由
- 从缓冲表中删除旧表项,并释放旧表项所在分区的
BufMappingLock。 - 将目标页面数据从存储加载至受害者槽位。然后用
buffer_id=5更新描述符的标识字段;将脏位设置为0,并按流程初始化其他标记位。 - 释放新表项所在分区上的
BufMappingLock。 - 访问
buffer_id=5对应的缓冲区槽位。图8.11 将页面从存储加载至受害者缓冲池槽(接图8.10)
8.4.4 页面替换算法:时钟扫描
本节的其余部分介绍了时钟扫描(clock-sweep) 算法。该算法是NFU(Not Frequently Used) 算法的变体,开销较小,能高效地选出较少使用的页面。
我们将缓冲区描述符想象为一个循环列表(如图8.12所示)。而nextVictimBuffer是一个32位的无符号整型变量,它总是指向某个缓冲区描述符并按顺时针顺序旋转。该算法的伪代码与算法描述如下:
伪代码:时钟扫描
WHILE true (1) 获取nextVictimBuffer指向的缓冲区描述符 (2) IF 缓冲区描述符没有被钉住 THEN (3) IF 候选缓冲区描述符的 usage_count == 0 THEN BREAK WHILE LOOP /* 该描述符对应的槽就是受害者槽 */ ELSE 将候选描述符的 usage_count - 1 END IF END IF (4) 迭代 nextVictimBuffer,指向下一个缓冲区描述符 END WHILE (5) RETURN 受害者页面的 buffer_id
- 获取
nextVictimBuffer指向的候选缓冲区描述符(candidate buffer descriptor) 。- 如果候选描述符未被钉住(unpinned) ,则进入步骤(3), 否则进入步骤(4)。
- 如果候选描述符的
usage_count为0,则选择该描述符对应的槽作为受害者,并进入步骤(5);否则将此描述符的usage_count减1,并继续执行步骤(4)。- 将
nextVictimBuffer迭代至下一个描述符(如果到末尾则回绕至头部)并返回步骤(1)。重复至找到受害者。- 返回受害者的
buffer_id。
具体的例子如图8.12所示。缓冲区描述符为蓝色或青色的方框,框中的数字显示每个描述符的usage_count。
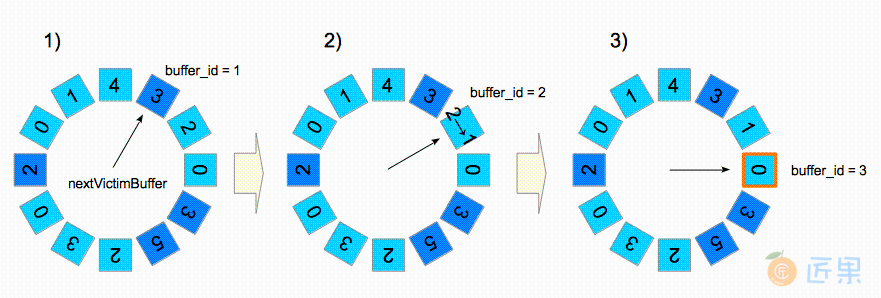
nextVictimBuffer指向第一个描述符(buffer_id = 1);但因为该描述符被钉住了,所以跳过。extVictimBuffer指向第二个描述符(buffer_id = 2)。该描述符未被钉住,但其usage_count为2;因此该描述符的usage_count将减1,而nextVictimBuffer迭代至第三个候选描述符。nextVictimBuffer指向第三个描述符(buffer_id = 3)。该描述符未被钉住,但其usage_count = 0,因而成为本轮的受害者。
当nextVictimBuffer扫过未固定的描述符时,其usage_count会减1。因此只要缓冲池中存在未固定的描述符,该算法总能在旋转若干次nextVictimBuffer后,找到一个usage_count为0的受害者。