PostgreSQL将XLOG记录写入pg_xlog子目录中的WAL段文件中(版本10之后是pg_wal子目录),当旧的段文件写满时就会切换至新的段文件。WAL文件的数量会根据几个配置参数的变化而变化,一些服务器的行为也会相应变化。此外,在9.5版中,段文件的管理机制也有了一些改善。
9.9.1 WAL段切换
当出现下列任一情况时,WAL段会发生切换:
- WAL段已经被填满。
- 函数
pg_switch_xlog()(10以后为pg_switch_wal())被调用。 - 启用了
archive_mode,且已经超过archive_timeout配置的时间。
被切换的文件通常会被回收(重命名或重用),以供未来之用。但如果不是需要的话,也可能会被移除。
9.9.2 WAL段管理(9.5版及以后)
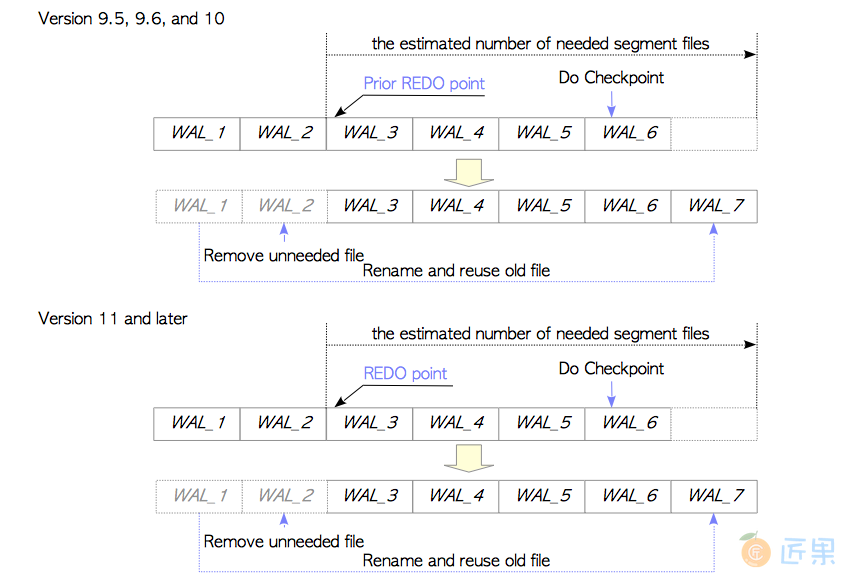
每当检查点过程启动时,PostgreSQL都会估计并准备下一个检查点周期所需的WAL段文件数。这种估计基于前一个检查点周期中消耗的文件数量,即从包含上一个重做点的段文件开始计数,而这个值应当在min_wal_size(默认80MB,5个文件)与max_wal_size之间(默认1GB,64个文件)。如果检查点过程启动,必需的段文件会被保留或回收,而不必要的段文件会被移除。
一个具体的例子如图9.17所示,假设在检查点开始前有六个文件,WAL_3包含了上一个重做点(版本10及以前,版本11后就是当前重做点),PostgreSQL估计会需要五个文件,在这种情况下,WAL_1被重命名为WAL_7回收利用,而WAL_2会被移除。
任何比包含上一个重做点的段文件更老的段文件都可以被移除,因为按照9.8节中描述的恢复机制,这些文件永远不会被用到了。
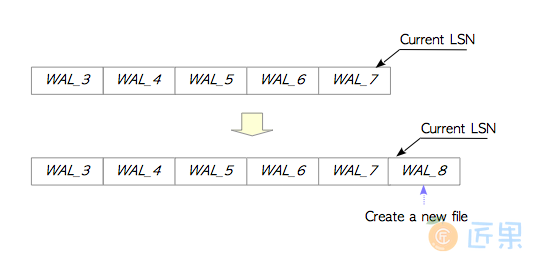
如果出现了WAL活动尖峰,导致需要更多的文件,新的文件会被创建,而WAL文件的总大小是小于max_wal_size的。例如在图9.18中,如果WAL_7被填满,WAL_8就会被新创建出来。
WAL文件的数量会根据服务器活动而自动适配。 如果WAL数据写入量持续增加,则WAL段文件的估计数量以及WAL文件的总大小也会逐渐增加。 在相反的情况下(即WAL数据写入量减少),这些值也会减少。
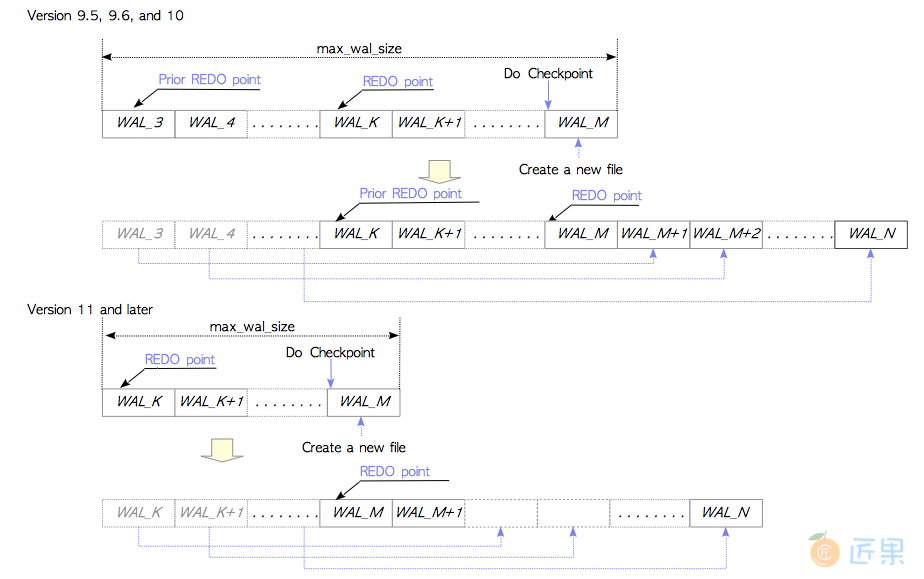
如果WAL文件的总大小超过max_wal_size,则将启动检查点。 图9.19说明了这种情况。 检查点将会创建一个新的重做点,最近的重做点将会变为上一个重做点,不是必需的文件将被回收。通过这种方式,PostgreSQL将始终只保留数据库恢复所必需的WAL段文件。
配置参数wal_keep_segments以及复制槽(Replication Slot) 功能都会影响WAL段文件的数量。
9.9.3 WAL段管理(9.4版及以前)
WAL段文件的数量主要由下列三个参数控制:
checkpoint_segmentscheckpoint_completion_targetwal_keep_segments。
WAL段文件的数量通常会:
- 比 \(((2 + \verb|checkpoint_completion_target|) × \verb|checkpoint_segments| + 1 )\) 要大
- 比\(( \verb|checkpoint_segments| + \verb|wal_keep_segments| + 1)\)要大且不超过\((3×\verb|checkpoint_segments|+1)\)个文件
WAL段文件具体数目的取决于不同的服务器活动,复制槽的存在也会影响WAL文件的数量。
如第9.7节中所提到的,当消耗了超过checkpoint_segments个数量的文件时,就会启动检查点过程。因此可以保证WAL段文件中总是包含至少两个重做点,因为文件的数量始终大于$ 2×\verb|checkpoint_segments|$,对于由超时导致的检查点同样适用。PostgreSQL总是会保留足够用于恢复的WAL段文件(有时候会超出必需的量)。
在版本9.4或更早版本中,调整参数
checkpoint_segments是一个痛苦的问题。 如果设置为较小的值,则检查点会频繁发生,这会导致性能下降;而如果设置为较大的数值,则WAL文件总是需要巨大的磁盘空间,但其中一些空间不是必须的。在9.5版本中,WAL文件的管理策略得到了改善,而
checkpoint_segments参数被弃用,因此上述的权衡问题已经得到解决。