PostgreSQL 中支持三种连接(JOIN)操作:嵌套循环连接(Nested Loop Join),归并连接(Merge Join) ,散列连接(Hash Join)。在PostgreSQL中,嵌套循环连接与归并连接有几种变体。
在下文中,我们会假设读者已经对这三种操作的基本行为有了解。PostgreSQL支持一种针对数据倾斜的混合散列连接(hybrid hash join) ,关于这方面的资料不多,因此这里会详细描述该操作。
需要注意的是,这三种连接方法(join method) 都支持PostgreSQL中所有的连接操作,诸如INNER JOIN,LEFT/RIGHT OUTER JOIN,FULL OUTER JOIN等;但是为了简单起见,这里只关注NATURAL INNER JOIN。
3.5.1 嵌套循环连接(Nested Loop Join)
嵌套循环连接 是最为基础的连接操作,任何连接条件(join condition) 都可以使用这种连接方式。PostgreSQL支持嵌套循环连接及其五种变体。
3.5.1.1 嵌套循环连接
嵌套循环连接无需任何启动代价,因此: \( \verb|start-up_cost| = 0\)
运行代价与内外表尺寸的乘积成比例;即\(\verb|runcost|\)是\(O(N_{\verb|outer|}× N_{\verb|inner|})\),这里\(N_{\verb|outer|}\)和\(N_{\verb|inner|}\)分别是外表和内表的元组条数。更准确的说,\(\verb|run_cost|\)的定义如下:这里\(C_{\verb|outer|}\)和\(C_{\verb|inner|}\)分别是内表和外表顺序扫描的代价;
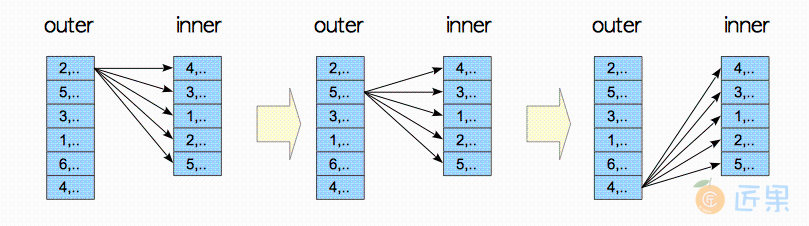
嵌套循环连接的代价总是会被估计,但实际中很少会使用这种连接操作,因为它有几种更高效的变体,下面将会讲到。
3.5.1.2 物化嵌套循环连接
在上面描述的嵌套循环连接中,每当读取一条外表中的元组时,都需要扫描内表中的所有元组。为每条外表元组对内表做全表扫描,这一过程代价高昂,PostgreSQL支持一种物化嵌套循环连接(materialized nested loop join) ,可以减少内表全表扫描的代价。
在运行嵌套循环连接之前,执行器会使用临时元组存储(temporary tuple storage) 模块对内表进行一次扫描,将内表元组加载到工作内存或临时文件中。在处理内表元组时,临时元组存储比缓冲区管理器更为高效,特别是当所有的元组都能放入工作内存中时。
图 3.17说明了物化嵌套循环连接的处理过程。扫描物化元组在内部被称为重扫描(rescan) 。
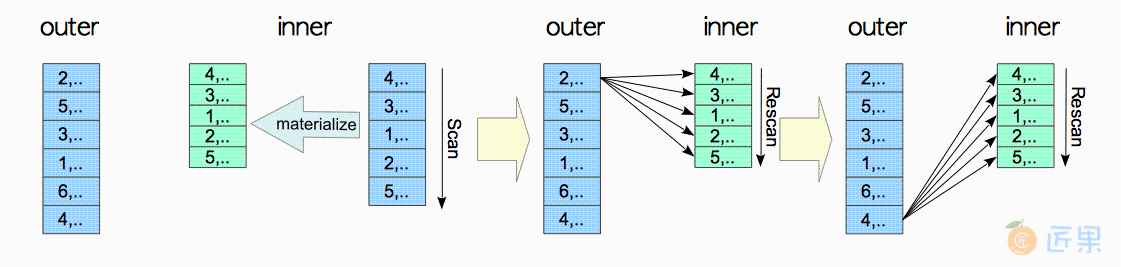
临时元组存储
PostgreSQL内部提供了临时元组存储的模块,可用于各种操作:物化表,创建混合散列连接的批次,等等。该模块包含一系列函数,都在
tuplestore.c中。这些函数用于从工作内存或临时文件读写元组。使用工作内存还是临时文件取决于待存储元组的总数。
下面给出一个具体的例子,并研究一下执行器是如何处理物化嵌套循环连接的计划树并估计其代价的。
testdb=# EXPLAIN SELECT * FROM tbl_a AS a, tbl_b AS b WHERE a.id = b.id;
QUERY PLAN
-----------------------------------------------------------------------
Nested Loop (cost=0.00..750230.50 rows=5000 width=16)
Join Filter: (a.id = b.id)
-> Seq Scan on tbl_a a (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..98.00 rows=5000 width=8)
-> Seq Scan on tbl_b b (cost=0.00..73.00 rows=5000 width=8)
(5 rows)
上面显示了执行器要进行的操作,执行器对这些计划节点的处理过程如下:
- 第7行:执行器使用顺序扫描,物化内部表
tbl_b。 - 第4行:执行器执行嵌套循环连接操作,外表是
tbl_a,内表是物化的tbl_b。
下面来估算“物化”操作(第7行)与“嵌套循环”(第4行)的代价。假设物化的内部表元组都在工作内存中。
物化(Materialize) :
- 物化操作没有启动代价;其运行代价定义如下:\( \verb|run_cost| = 2 × \verb|cpu_operator_cost| × N_{\verb|inner|};\)
- 因此:\( \verb|run_cost|=2× 0.0025× 5000=25.0\)
- 此外,\( \verb|total_cost| = (\verb|start-up_cost|+ \verb|total_cost_of_seq_scan|)+ \verb|run_cost|\)
- 因此,\( \verb|total_cost| = (0.0+73.0)+25.0=98.0\)
(物化)嵌套循环 :
- 嵌套循环没有启动代价,因此:\( \verb|start-up_cost|=0\)
- 在估计运行代价之前,先来看一下重扫描的代价,重扫描的代价定义如下:\( \verb|rescan_cost| = \verb|cpu_operator_cost| × N_{\verb|inner|}\)
- 这本例中:\( \verb|rescan_cost| = (0.0025)× 5000=12.5\)
3.5.1.3 索引嵌套循环连接
如果内表上有索引,且该索引能用于搜索满足连接条件的元组。那么计划器在为外表的每条元组搜索内表中的匹配元组时,会考虑使用索引进行直接搜索,以替代顺序扫描。这种变体叫做索引嵌套循环连接(indexed nested loop join) ,如图3.18所示。尽管这种变体叫做索引"嵌套循环连接",但该算法基本上只需要在在外表上循环一次,因此连接操作执行起来相当高效。
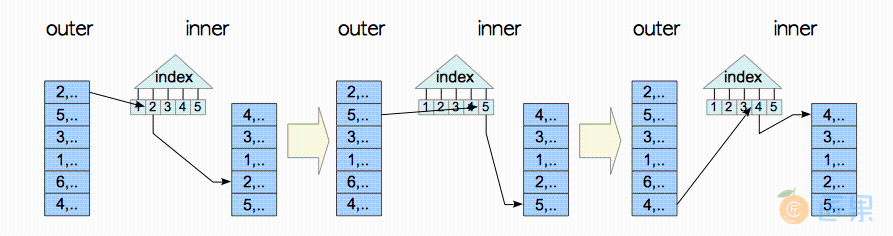
下面是索引嵌套循环连接的一个具体例子。
testdb=# EXPLAIN SELECT * FROM tbl_c AS c, tbl_b AS b WHERE c.id = b.id;
QUERY PLAN
--------------------------------------------------------------------------------
Nested Loop (cost=0.29..1935.50 rows=5000 width=16)
-> Seq Scan on tbl_b b (cost=0.00..73.00 rows=5000 width=8)
-> Index Scan using tbl_c_pkey on tbl_c c (cost=0.29..0.36 rows=1 width=8)
Index Cond: (id = b.id)
(4 rows)
第6行展示了访问内表中元组的代价。即在内表中查找满足第七行连接条件(id = b.id)的元组的代价。
在第7行的索引条件(id = b.id)中,b.id是连接条件中的外表属性的值。每当顺序扫描外表取回一条元组时,就会依第6行所示的索引搜索路径,查找内表中需要与之连接的元组。换而言之,外表元组的值作为参数传入内表的索引扫描中,索引扫描路径会查找满足连接条件的内表元组。这种索引路径被称为参数化(索引)路径(parameterized (index) path) ,细节见PostgreSQ源码:backend/optimizer/README。
- 该嵌套循环连接的启动代价,等于第6行中索引扫描的代价,因此:\( \verb|start-up_cost| = 0.285\)
- 索引嵌套循环扫描的总代价由下列公式所定义:\( \verb|total_cost|= (\verb|cpu_tuple_cost| + C^{\verb|total|}{\verb|inner,parameterized|} )× N {\verb|outer|}+C^{\verb|run|}*{\verb|outer,seqscan|}\)
- 这里\(C^{\verb|total|}* {\verb|inner,parameterized|}\)是参数化内表索引扫描的整体代价,
- 在本例中:\( \verb|total_cost|=(0.01+0.3625)× 5000 + 73.0 = 1935.5\)
- 而运行代价为:\( \verb|run_cost| = 1935.5-0.285=1935.215\)
- 如上所示,索引嵌套扫描的整体代价是\(O(N_{\verb|outer|})\)。
3.5.1.4 其他变体
如果在外表上存在一个与连接条件相关的索引,那么在外表上也可以以索引扫描替代顺序扫描。特别是,当WHERE子句中的访问谓词可以使用该索引时,能缩小外表上的搜索范围,嵌套循环连接的代价可能会急剧减少。
当使用外表索引扫描时,PostgreSQL支持三种嵌套循环连接的变体,如图3.19所示。
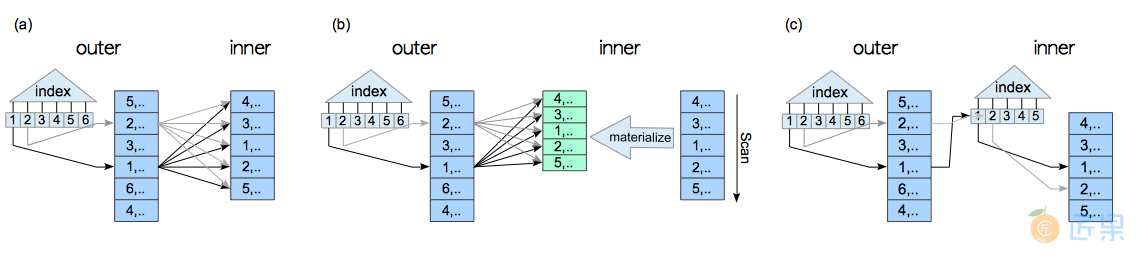
这些连接的EXPLAIN结果如下:
- 使用外表索引扫描的嵌套循环连接
testdb=# SET enable_hashjoin TO off; SET testdb=# SET enable_mergejoin TO off; SET testdb=# EXPLAIN SELECT * FROM tbl_c AS c, tbl_b AS b WHERE c.id = b.id AND c.id = 500; QUERY PLAN ------------------------------------------------------------------------------- Nested Loop (cost=0.29..93.81 rows=1 width=16) -> Index Scan using tbl_c_pkey on tbl_c c (cost=0.29..8.30 rows=1 width=8) Index Cond: (id = 500) -> Seq Scan on tbl_b b (cost=0.00..85.50 rows=1 width=8) Filter: (id = 500) (5 rows) - 使用外表索引扫描的物化嵌套循环连接
testdb=# SET enable_hashjoin TO off; SET testdb=# SET enable_mergejoin TO off; SET testdb=# EXPLAIN SELECT * FROM tbl_c AS c, tbl_b AS b WHERE c.id = b.id AND c.id < 40 AND b.id < 10; QUERY PLAN ------------------------------------------------------------------------------- Nested Loop (cost=0.29..99.76 rows=1 width=16) Join Filter: (c.id = b.id) -> Index Scan using tbl_c_pkey on tbl_c c (cost=0.29..8.97 rows=39 width=8) Index Cond: (id < 40) -> Materialize (cost=0.00..85.55 rows=9 width=8) -> Seq Scan on tbl_b b (cost=0.00..85.50 rows=9 width=8) Filter: (id < 10) (7 rows) - 使用外表索引扫描的索引嵌套循环连接
testdb=# SET enable_hashjoin TO off; SET testdb=# SET enable_mergejoin TO off; SET testdb=# EXPLAIN SELECT * FROM tbl_a AS a, tbl_d AS d WHERE a.id = d.id AND a.id < 40; QUERY PLAN ------------------------------------------------------------------------------- Nested Loop (cost=0.57..173.06 rows=20 width=16) -> Index Scan using tbl_a_pkey on tbl_a a (cost=0.29..8.97 rows=39 width=8) Index Cond: (id < 40) -> Index Scan using tbl_d_pkey on tbl_d d (cost=0.28..4.20 rows=1 width=8) Index Cond: (id = a.id) (5 rows)
3.5.2 归并连接(Merge Join)
与嵌套循环连接不同的是,归并连接(Merge Join) 只能用于自然连接与等值连接。函数initial_cost_mergejoin()和final_cost_mergejoin()用于估计归并连接的代价。
因为精确估计归并连接的代价非常复杂,因此这里略过不提,只会说明归并连接算法的工作流程。归并连接的启动成本是内表与外表排序成本之和,因此其启动成本为:\( O(N_{\verb|outer|} \log_2(N_{\verb|outer|}) + N_{\verb|inner|} \log_2(N_{\verb|inner|}))\)
这里\(N_{\verb|outer|}\)和\(N_{\verb|inner|}\)是分别是外表和内表的元组条数,而运行代价是\(O(N_{\verb|outer|}+N_{\verb|inner|})\)。与嵌套循环连接类似,归并连接在PostgreSQL中有4种变体。
3.5.2.1 归并连接
图3.20是归并连接的概念示意图。
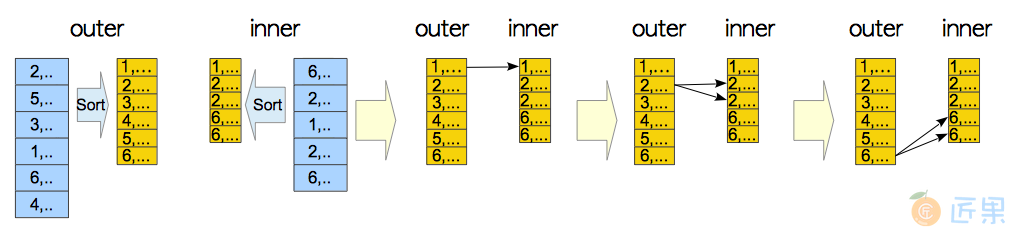
如果所有元组都可以存储在内存中,那么排序操作就能在内存中进行,否则会使用临时文件。下面是一个具体的例子,一个归并连接的EXPLAIN输出如下所示。
# EXPLAIN SELECT * FROM tbl_a AS a, tbl_b AS b WHERE a.id = b.id AND b.id < 1000;
QUERY PLAN
-------------------------------------------------------------------------
Merge Join (cost=944.71..984.71 rows=1000 width=16)
Merge Cond: (a.id = b.id)
-> Sort (cost=809.39..834.39 rows=10000 width=8)
Sort Key: a.id
-> Seq Scan on tbl_a a (cost=0.00..145.00 rows=10000 width=8)
-> Sort (cost=135.33..137.83 rows=1000 width=8)
Sort Key: b.id
-> Seq Scan on tbl_b b (cost=0.00..85.50 rows=1000 width=8)
Filter: (id < 1000)
(9 rows)
- 第9行:执行器对内表
tbl_b进行排序,使用顺序扫描(第11行)。 - 第6行:执行器对外表
tbl_a进行排序,使用顺序扫描(第8行)。 - 第4行:执行器执行归并连接操作,外表是排好序的
tbl_a,内表是排好序的tbl_b。
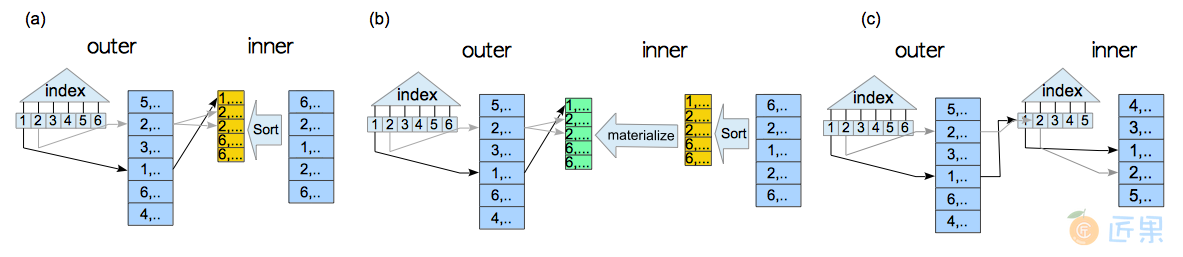
3.5.2.2 物化归并连接
与嵌套循环连接类似,归并连接还支持物化归并连接(Materialized Merge Join) ,物化内表,使内表扫描更为高效。
图3.21 物化归并连接

这里是物化归并连接的EXPLAIN结果,很容易发现,与普通归并连接的差异是第9行:Materialize。
testdb=# EXPLAIN SELECT * FROM tbl_a AS a, tbl_b AS b WHERE a.id = b.id;
QUERY PLAN
---------------------------------------------------------------------------------
Merge Join (cost=10466.08..10578.58 rows=5000 width=2064)
Merge Cond: (a.id = b.id)
-> Sort (cost=6708.39..6733.39 rows=10000 width=1032)
Sort Key: a.id
-> Seq Scan on tbl_a a (cost=0.00..1529.00 rows=10000 width=1032)
-> Materialize (cost=3757.69..3782.69 rows=5000 width=1032)
-> Sort (cost=3757.69..3770.19 rows=5000 width=1032)
Sort Key: b.id
-> Seq Scan on tbl_b b (cost=0.00..1193.00 rows=5000 width=1032)
(9 rows)
- 第10行:执行器对内表
tbl_b进行排序,使用顺序扫描(第12行)。 - 第9行:执行器对
tbl_b排好序的结果进行物化。 - 第6行:执行器对外表
tbl_a进行排序,使用顺序扫描(第8行)。 - 第4行:执行器执行归并连接操作,外表是排好序的
tbl_a,内表是物化的排好序的tbl_b。
3.5.2.3 其他变体
与嵌套循环连接类似,当外表上可以进行索引扫描时,归并连接也存在相应的变体。
这些连接的EXPLAIN结果如下。
- 使用外表索引扫描的归并连接
testdb=# SET enable_hashjoin TO off; SET testdb=# SET enable_nestloop TO off; SET testdb=# EXPLAIN SELECT * FROM tbl_c AS c, tbl_b AS b WHERE c.id = b.id AND b.id < 1000; QUERY PLAN ------------------------------------------------------------------------------ Merge Join (cost=135.61..322.11 rows=1000 width=16) Merge Cond: (c.id = b.id) -> Index Scan using tbl_c_pkey on tbl_c c (cost=0.29..318.29 rows=10000 width=8) -> Sort (cost=135.33..137.83 rows=1000 width=8) Sort Key: b.id -> Seq Scan on tbl_b b (cost=0.00..85.50 rows=1000 width=8) Filter: (id < 1000) (7 rows) - 使用外表索引扫描的物化归并连接
testdb=# SET enable_hashjoin TO off; SET testdb=# SET enable_nestloop TO off; SET testdb=# EXPLAIN SELECT * FROM tbl_c AS c, tbl_b AS b WHERE c.id = b.id AND b.id < 4500; QUERY PLAN ------------------------------------------------------------------------------- Merge Join (cost=421.84..672.09 rows=4500 width=16) Merge Cond: (c.id = b.id) -> Index Scan using tbl_c_pkey on tbl_c c (cost=0.29..318.29 rows=10000 width=8) -> Materialize (cost=421.55..444.05 rows=4500 width=8) -> Sort (cost=421.55..432.80 rows=4500 width=8) Sort Key: b.id -> Seq Scan on tbl_b b (cost=0.00..85.50 rows=4500 width=8) Filter: (id < 4500) (8 rows) - 使用外表索引扫描的索引归并连接
testdb=# SET enable_hashjoin TO off; SET testdb=# SET enable_nestloop TO off; SET testdb=# EXPLAIN SELECT * FROM tbl_c AS c, tbl_d AS d WHERE c.id = d.id AND d.id < 1000; QUERY PLAN ------------------------------------------------------------------------------- Merge Join (cost=0.57..226.07 rows=1000 width=16) Merge Cond: (c.id = d.id) -> Index Scan using tbl_c_pkey on tbl_c c (cost=0.29..318.29 rows=10000 width=8) -> Index Scan using tbl_d_pkey on tbl_d d (cost=0.28..41.78 rows=1000 width=8) Index Cond: (id < 1000) (5 rows)
3.5.3 散列连接(Hash Join)
与归并连接类似,散列连接(Hash Join) 只能用于自然连接与等值连接。
PostgreSQL中的散列连接的行为因表的大小而异。 如果目标表足够小(确切地讲,内表大小不超过工作内存的25%),那么散列连接就是简单的两阶段内存散列连接(two-phase in-memory hash join) ; 否则,将会使用带倾斜批次的混合散列连接(hybrid hash join) 。
本小节将介绍PostgreSQL中这两种散列连接的执行过程。
这里省略了代价估算的部分,因为它很复杂。粗略来说,假设向散列表插入与搜索时没有遇到冲突,那么启动和运行成本复杂度都是\(O(N_{\verb|outer|} + N_{\verb|inner|})\)。
3.5.3.1 内存散列连接
下面将描述内存中的散列连接。
内存中的散列连接是在work_mem中处理的,在PostgreSQL中,散列表区域被称作处理批次(batch) 。 一个处理批次会有多个散列槽(hash slots),内部称其为** 桶(buckets)**,桶的数量由nodeHash.c中定义的ExecChooseHashTableSize()函数所确定。 桶的数量总是2的整数次幂。
内存散列连接有两个阶段:构建(build) 阶段和探测(probe) 阶段。 在构建阶段,内表中的所有元组都会被插入到batch中;在探测阶段,每条外表元组都会与处理批次中的内表元组比较,如果满足连接条件,则将两条元组连接起来。
为了理解该操作的过程,下面是一个具体的例子。 假设该查询中的连接操作使用散列连接。
SELECT * FROM tbl_outer AS outer, tbl_inner AS inner WHERE inner.attr1 = outer.attr2;
散列连接的过程如图3.23和3.24所示。
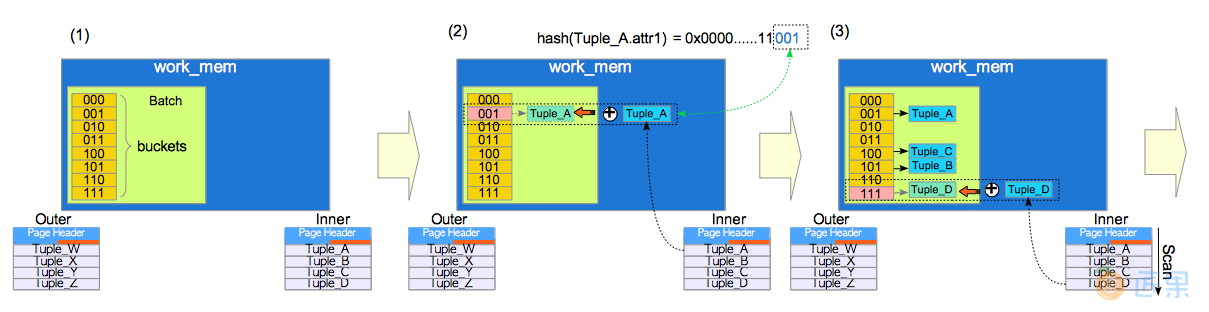
- 在工作内存上创建一个处理批次。 在本例中,处理批次有八个桶;即桶的数量是2的3次方。
- 将内表的第一个元组插入批次的相应的桶中。
具体过程如下:
- 找出元组中涉及连接条件的属性,计算其散列键。
在本例中,因为
WHERE子句是inner.attr1 = outer.attr2,因此内置的散列函数会对第一条元组的属性attr1取散列值,用作散列键。 - 将第一条元组插入散列键相应的桶中。
假设第一条元组的散列键以二进制记法表示为
0x000 ... 001,即其末三位(bit) 为001。 在这种情况下,该元组会被插入到键为001的桶中。 在本文中,构建处理批次的插入操作会用运算符 ⊕ 表示。
- 找出元组中涉及连接条件的属性,计算其散列键。
在本例中,因为
- 插入内表中的其余元组。
图3.24. 内存散列连接的探测阶段
- 依外表的第一条元组进行探测。
详情如下:
- 找出第一条外表元组中涉及连接条件的属性,计算其散列键。
在这个例子中,假设第一条元组的属性
attr2的散列键是0x000 ... 100,即其末三位(bit) 为100。 最后三位是100。 - 将外表中第一条元组与批次中的内表元组进行比较。如果满足连接条件,则连接内外表元组。
因为第一个元组的散列键的末三位为
100,执行器找出键为100的桶中的所有内表元组,并对内外表元组两侧相应的属性进行比较。这些属性由连接条件(在WHERE子句中)所指明。 如果满足连接条件,执行器会连接外表中的第一条元组与内表中的相应元组。如果不满足则执行器不做任何事情。 在本例中,键为100的桶中有Tuple_C。如果Tuple_C的attr1等于第一条元组(Tuple_W)的attr2,则Tuple_C和Tuple_W将被连接,并保存至内存或临时文件中。 在本文中,处理批次的探测操作用运算符 ⊗ 表示。
- 找出第一条外表元组中涉及连接条件的属性,计算其散列键。
在这个例子中,假设第一条元组的属性
- 依次对外表中的其他元组执行探测。
3.5.3.2 带倾斜的混合散列连接
当内表的元组无法全部存储在工作内存中的单个处理批次时,PostgreSQL使用带倾斜批次的混合散列连接算法,该算法是混合散列连接的一种变体。
首先,这里会描述混合散列连接的基本概念。在第一个构建和探测阶段,PostgreSQL准备多个批次。与桶的数目类似,处理批次的数目由函数ExecChooseHashTableSize()决定,也总是2的整数次幂。工作内存中只会分配一个处理批次,而其他批次作都以临时文件的形式创建。属于这些批次的元组将通过临时元组存储功能,被写入到相应的文件中。
图3.25说明了如何将元组存储在四个($ 2 ^ 2 $)处理批次中。在本例中元组散列键的最后五个比特位决定了元组所属的批次与桶,因为处理批次的数量为$ 2^2$,而桶的数量为$ 2^3$,因此需要5个比特位来表示,其中前两位决定了元组所属的批次,而后三位决定了元组在该批次中所属的桶。例如:Batch_0存储着散列键介于$\textcolor{red}{00}000$与$\textcolor{red}{00}111$的元组;而Batch_1存储着散列键介于$\textcolor{red}{01}000$与$\textcolor{red}{01}111$的元组,依此类推。

在混合散列连接中,构建与探测阶段的执行次数与处理批次的数目相同,因为内外表元组都被存至相同数量的处理批次中。在第一轮构建与探测阶段中,除了处理第一个处理批次,还会创建所有的处理批次。另一方面,第二轮及后续的处理批次都需要读写临时文件,这属于代价巨大的操作。因此PostgreSQL还准备了一个名为skew 的特殊处理批次,即倾斜批次,以便在第一轮中高效处理尽可能多的元组。
这个特殊的倾斜批次中的内表元组在连接条件内表一侧属性上的取值,会选用外表连接属性上的高频值(MCV)。因此在第一轮处理中能与外表中尽可能多的元组相连接。这种解释不太好理解,因此下面给出了一个具体的例子。
假设有两个表:客户表customers与购买历史表purchase_history。customers由两个属性组成:name和address; purchase_history由两个属性组成:customer_name和buying_item。customers有10,000行,而purchase_history表有1,000,000行。前10%的客户进行了70%的购买。
理解了这些假设,让我们考虑当执行以下查询时,带倾斜的混合散列连接的第一轮是如何执行的。
SELECT * FROM customers AS c, purchase_history AS h
WHERE c.name = h.customer_name;
如果customers是内表,而purchase_history是外表,则PostgreSQL将使用purchase_history表的高频值值,将前10%的customers元组存储于倾斜批次中。 请注意这里引用的是外表上的高频值,而插入倾斜批次的是内表元组。 在第一轮的探测阶段,外表(purchase_history)中70%的元组将与倾斜批次中存储的元组相连接。 因此,外表分布越是不均匀,第一轮中越是可以处理尽可能多的元组。
接下来会介绍带倾斜批次的混合散列连接的工作原理,如图3.26至3.29所示。
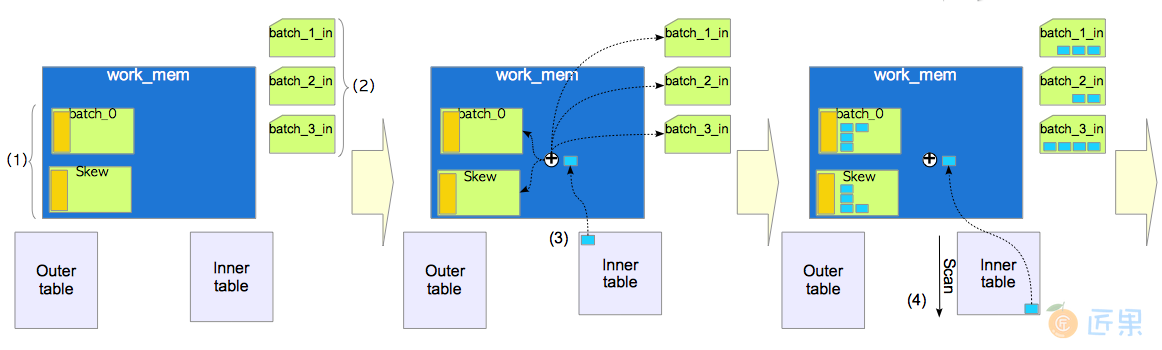
- 在工作内存中创建一个处理批次,以及一个倾斜批次。
- 创建处理批次相应的临时文件,用于存储排好序的内表元组。 在本例中,内表被分割为四个批次,因此创建了三个批次文件。
- 为内表的第一条元组执行构建操作。
细节如下:
- 如果第一条元组应当插入倾斜批次中,则将其插入倾斜批次;否则继续下一步。 在该例中,如果第一条元组属于前10%的客户,则将其插入到倾斜批次中。
- 计算第一条元组的散列键,然后将其插入相应的处理批次。
- 对内表其余元组依次执行构建操作。
图3.27 混合散列连接,探测阶段第一轮
- 创建临时处理批次文件,用于外表排序。
- 为外表的第一条元组执行探测操作,如果外表第一条元组上相应字段取值为MCV,则在倾斜批次上进行探测,否则进行第七步。 在本例中,如果第一条元组是前10%客户的购买数据,则它会与倾斜批次中的内表元组进行比较。
- 为外表的第一条元组执行探测操作。
操作的内容取决于该元组散列键的取值。如果该元组属于
Batch_0则直接完成探测操作;否则将其插入相应的外表处理批次中。 - 为外表的其余元组执行探测操作。
注意在本例中,外表中70%的元组已经在第一轮中的倾斜批次中处理了。
图3.28 构建阶段与探测阶段,第二轮
- 移除倾斜批次与
Batch_0,为下一轮处理批次腾地方。 - 为批次文件
batch_1_in中的内表元组执行构建操作。 - 为批次文件
batch_1_out中的外表元组依次执行探测操作。图3.29 构建阶段与探测阶段,第三轮及后续
- 为批次文件
batch_2_in与batch_2_out执行构建操作与探测操作。 - 为批次文件
batch_3_in与batch_3_out执行构建操作与探测操作。
3.5.4 连接访问路径与连接节点
3.5.4.1 连接访问路径
嵌套循环连接的访问路径由JoinPath结构表示,其他连接访问路径,诸如MergePath与HashPath都基于其实现。
下图列出了所有的连接访问路径,细节略过不提。
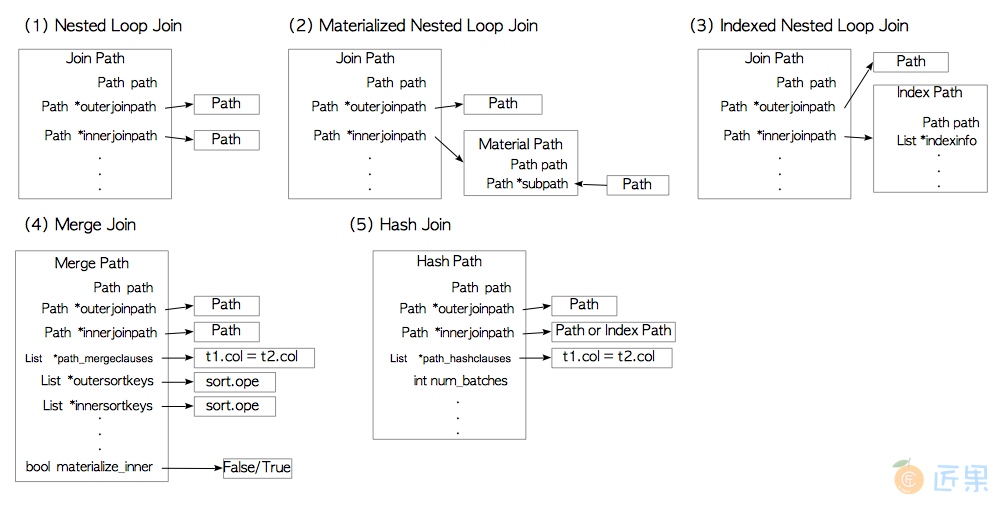
typedef JoinPath NestPath;
typedef enum JoinType
{
/* 根据SQL JOIN语法确定的标准连接种类,解析器只允许输出这几种取值。
* (例如JoinExpr节点) */
JOIN_INNER, /* 仅包含匹配的元组对 */
JOIN_LEFT, /* 匹配元组对 + 未匹配的左表元组 */
JOIN_FULL, /* 匹配元组对 + 未匹配的左右表元组 */
JOIN_RIGHT, /* 匹配元组对 + 未匹配的右表元组 */
/* 关系理论中的半连接(semijoin)与否定半连接(anti-semijoin)并没有用SQL JOIN
* 语法来表示,而是用另一种风格标准来表示(举个例子,EXISTS)。计划器会认出这些情景
* 并将其转换为连接。因此计划器与执行器必须支持这几种取值。注意:对于JOIN_SEMI的
* 输出而言,连接到哪一条右表元组是不确定的。而对于JOIN_ANTI的输出而言,会保证使用
* 空值进行行扩展。*/
JOIN_SEMI, /* 左表元组的一份拷贝,如果该元组有相应匹配 */
JOIN_ANTI, /* 右表元组的一份拷贝,如果该元组有相应匹配 */
/* 这几种代码用于计划器内部,执行器并不支持。(其实大多数时候计划器也不会用) */
JOIN_UNIQUE_OUTER, /* 左表路径必须是UNIQUE的 */
JOIN_UNIQUE_INNER /* 右表路径必须是UNIQUE的 */
} JoinType;
typedef struct JoinPath
{
Path path;
JoinType jointype;
Path *outerjoinpath; /* 连接外表一侧的路径 */
Path *innerjoinpath; /* 连接内表一侧的路径 */
List *joinrestrictinfo; /* 连接所适用的限制信息 */
/* 参考RelOptInfo与ParamPathInfo才能理解为什么JoinPath需要有joinrestrictinfo
* 且不能合并到RelOptInfo中。 */
} JoinPath;
typedef struct MergePath
{
JoinPath jpath;
List *path_mergeclauses; /* 归并所需的连接子句 */
List *outersortkeys; /* 用于外表显式排序的键,如果存在 */
List *innersortkeys; /* 用于内表显式排序的键,如果存在 */
bool materialize_inner; /* 为内表执行物化过程? */
} MergePath;
3.5.4.2 连接节点
本小节列出了三种连接节点:NestedLoopNode,MergeJoinNode 和HashJoinNode,它们都基于JoinNode实现,细节略过不提。
/* ----------------
* 连接节点
*
* jointype: 连接左右子树元组的规则
* joinqual: 来自 JOIN/ON 或 JOIN/USING 的连接限定条件
* (plan.qual 包含了来自WHERE子句的条件)
*
* 当jointype为INNER时,joinqual 与 plan.qual 在语义上可以互换。对于OUTER而言这两者
* 则无法互换;只有joinqual会被用于匹配判定,以及是否需要生成空值扩展的元组。
* (但 plan.qual 仍然会在实际返回一条元组前生效。)
* 对于外连接而言,只有joinquals能被用于归并连接或散列连接的连接条件。
* ----------------
*/
typedef struct Join
{
Plan plan;
JoinType jointype;
List *joinqual; /* 连接条件 (除 plan.qual 外) */
} Join;
/* ----------------
* 嵌套循环连接节点
*
* nestParams的列表标识出了执行器所需的参数,这些参数从外表子计划中的当前行获取,
* 并传入内表子计划中用于执行。当前我们限制这些值为简单的Vars,但也许某一天这一限制
* 会放松。(注意在创建执行计划期间,paramval实际上可能是一个PlaceHolderVar表达式;
* 但当其进入执行器时,它必须转换为varno为OUTER_VAR的Var。)
* ----------------*/
typedef struct NestLoop
{
Join join;
List *nestParams; /* NestLoopParam 节点的列表*/
} NestLoop;
typedef struct NestLoopParam
{
NodeTag type;
int paramno; /* 需要配置的PARAM_EXEC参数数量 */
Var *paramval; /* 需要赋值给Param的外表变量 */
} NestLoopParam;
/* ----------------
* 归并连接节点
*
* 待归并列上期待的顺序是通过一个btree运算符族的OID,一个排序规则的OID,一个方向字段
* (BTLessStrategyNumber 或 * BTGreaterStrategyNumber),以及一个 NULL FIRST
* 标记位描述的。注意归并语句的两侧可能是不同的数据类型,但它们会按照共同的运算符族与排序
* 规则,以同样的方式排序。每个归并子句中的算子必须为相应运算符族中的等值运算。
* ---------------- */
typedef struct MergeJoin
{
Join join;
List *mergeclauses; /* mergeclauses 是一颗表达式树 */
/* 这些字段都是数组,但与mergeclauses列表有着同样的长度: */
Oid *mergeFamilies; /* B树运算符族的OID列表,每条子句一个 */
Oid *mergeCollations; /* 排序规则的OID列表,每条子句一个 */
int *mergeStrategies; /* 顺序(ASC 或 DESC)的列表,每条子句一个 */
bool *mergeNullsFirst; /* 空值顺序,每条子句一个 */
} MergeJoin;
/* ----------------
* 散列连接节点
* ---------------- */
typedef struct HashJoin
{
Join join;
List *hashclauses;
} HashJoin;
下一节:本节将说明多表查询计划树的创建过程。