缓冲区管理器会出于不同的目的使用各式各样的锁,本节将介绍理解后续部分所必须的一些锁。
注意本节中描述的锁,指的是是缓冲区管理器同步机制的一部分。它们与SQL语句和SQL操作中的锁没有任何关系。
8.3.1 缓冲表锁
BufMappingLock 保护整个缓冲表的数据完整性。它是一种轻量级的锁,有共享模式与独占模式。在缓冲表中查询条目时,后端进程会持有共享的BufMappingLock。插入或删除条目时,后端进程会持有独占的BufMappingLock。
BufMappingLock会被分为多个分区,以减少缓冲表中的争用(默认为128个分区)。每个BufMappingLock分区都保护着一部分相应的散列桶槽。
图8.7给出了一个BufMappingLock分区的典型示例。两个后端进程可以同时持有各自分区的BufMappingLock独占锁以插入新的数据项。如果BufMappingLock是系统级的锁,那么其中一个进程就需要等待另一个进程完成处理。
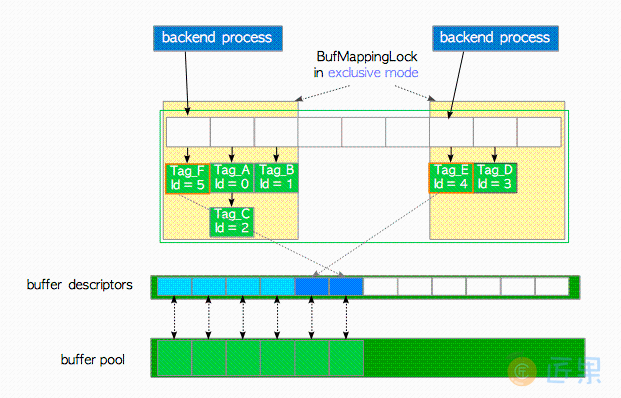
BufMappingLock独占锁,以插入新数据项
缓冲表也需要许多其他锁。例如,在缓冲表内部会使用自旋锁(spin lock) 来删除数据项。不过本章不需要其他这些锁的相关知识,因此这里省略了对其他锁的介绍。
在9.4版本之前,
BufMappingLock在默认情况下被分为16个独立的锁。
8.3.2 缓冲区描述符相关的锁
每个缓冲区描述符都会用到两个轻量级锁 —— content_lock 与 io_in_progress_lock,来控制对相应缓冲池槽页面的访问。当检查或更改描述符本身字段的值时,则会用到自旋锁。
8.3.2.1 内容锁(content_lock)
content_lock是一个典型的强制限制访问的锁。它有两种模式:共享(shared) 与独占(exclusive) 。
当读取页面时,后端进程以共享模式获取页面相应缓冲区描述符中的content_lock。
但执行下列操作之一时,则会获取独占模式的content_lock:
- 将行(即元组)插入页面,或更改页面中元组的
t_xmin/t_xmax字段时(t_xmin和t_xmax在 5.2 元组结构 中介绍,简单地说,这些字段会在相关元组被删除或更新行时发生更改)。 - 物理移除元组,或压紧页面上的空闲空间(由清理过程和HOT执行,分别在 第六章 清理过程(VACUUM) 和 第七章 堆内元组与仅索引扫描 中介绍)。
- 冻结页面中的元组(冻结过程在 第5.10.1节 与 第6.3节 中介绍)。
官方README文件包含更多的细节。
8.3.2.2 IO进行锁(io_in_progress_lock)
io_in_progress_lock用于等待缓冲区上的I/O完成。当PostgreSQL进程加载/写入页面数据时,该进程在访问页面期间,持有对应描述符上独占的io_in_progres_lock。
8.3.2.3 自旋锁(spinlock)
当检查或更改标记字段与其他字段时(例如refcount和usage_count),会用到自旋锁。下面是两个使用自旋锁的具体例子:
- 下面是钉住 缓冲区描述符的例子:
- 获取缓冲区描述符上的自旋锁。
- 将其
refcount和usage_count的值增加1。 - 释放自旋锁。
-
LockBufHdr(bufferdesc); /* 获取自旋锁 */ bufferdesc->refcont++; bufferdesc->usage_count++; UnlockBufHdr(bufferdesc); /* 释放该自旋锁 */
- 下面是将脏位设置为
"1"的例子:- 获取缓冲区描述符上的自旋锁。
- 使用位操作将脏位置位为
"1"。 - 释放自旋锁。
-
其他标记位也是通过同样的方式来设置的。#define BM_DIRTY (1 << 0) /* 数据需要写回 */ #define BM_VALID (1 << 1) /* 数据有效 */ #define BM_TAG_VALID (1 << 2) /* 已经分配了TAG */ #define BM_IO_IN_PROGRESS (1 << 3) /* 正在进行读写 */ #define BM_JUST_DIRTIED (1 << 5) /* 开始写之后刚写脏 */ LockBufHdr(bufferdesc); bufferdesc->flags |= BM_DIRTY; UnlockBufHdr(bufferdesc);
用原子操作替换缓冲区管理器的自旋锁
在9.6版本中,缓冲区管理器的自旋锁被替换为原子操作,可以参考这个提交日志的内容。如果想进一步了解详情,可以参阅这里的讨论。
附,9.6版本中缓冲区描述符的数据结构定义。
/* src/include/storage/buf_internals.h (since 9.6, 移除了一些字段) */ /* 缓冲区描述符的标记位定义(since 9.6) * 注意:TAG_VALID实际上意味着缓冲区哈希表中有一条与本tag关联的项目。 */ #define BM_LOCKED (1U << 22) /* 缓冲区首部被锁定 */ #define BM_DIRTY (1U << 23) /* 数据需要写入 */ #define BM_VALID (1U << 24) /* 数据有效 */ #define BM_TAG_VALID (1U << 25) /* 标签有效,已经分配 */ #define BM_IO_IN_PROGRESS (1U << 26) /* 读写进行中 */ #define BM_IO_ERROR (1U << 27) /* 先前的I/O失败 */ #define BM_JUST_DIRTIED (1U << 28) /* 写之前已经脏了 */ #define BM_PIN_COUNT_WAITER (1U << 29) /* 有人等着钉页面 */ #define BM_CHECKPOINT_NEEDED (1U << 30) /* 必需在检查点时写入 */ #define BM_PERMANENT (1U << 31) /* 永久缓冲 */ /* BufferDesc -- 单个共享缓冲区的共享描述符/共享状态 * * 注意: 读写tag, state, wait_backend_pid 等字段时必须持有缓冲区首部锁(BM_LOCKED标记位) * 简单地说,refcount, usagecount,标记位组合起来被放入一个原子变量state中,而缓冲区首部锁 * 实际上是嵌入标记位中的一个bit。 这种设计允许我们使用单个原子操作,而不是获取/释放自旋锁 * 来实现一些操作。举个例子,refcount的增减。buf_id字段在初始化之后再也不会改变,所以不需要锁。 * freeNext是通过buffer_strategy_lock而非buf_hdr_lock来保护的。LWLocks字段可以自己管好自 * 己。注意buf_hdr_lock *不是* 用来控制对缓冲区内数据的访问的! * * 我们假设当持有首部锁时,没人会修改state字段。因此持有缓冲区首部锁的人可以在一次写入中 * 中对state变量进行很复杂的更新,包括更新完的同时释放锁(清理BM_LOCKED标记位)。此外,不持有 * 缓冲区首部锁而对state进行更新仅限于CAS操作,它能确保操作时BM_LOCKED标记位没有被置位。 * 不允许使用原子自增/自减,OR/AND等操作。 * * 一个例外是,如果我们固定了(pinned)该缓冲区,它的标签除了我们自己之外不会被偷偷修改。 * 所以我们无需锁定自旋锁就可以检视该标签。此外,一次性的标记读取也无需锁定自旋锁, * 当我们期待测试标记位不会改变时,这种做法很常见。 * * 如果另一个后端固定了该缓冲区,我们就无法从磁盘页面上物理移除项目了。因此后端需要等待 * 所有其他的钉被移除。移除时它会得到通知,这是通过将它的PID存到wait_backend_pid,并设置 * BM_PIN_COUNT_WAITER标记为而实现的。目前而言,每个缓冲区只能有一个等待者。 * * 对于本地缓冲区,我们也使用同样的首部,不过锁字段就没用了,一些标记位也没用了。为了避免不必要 * 的额外开销,对state字段的操作不需要用实际的原子操作(即pg_atomic_read_u32, * pg_atomic_unlocked_write_u32) * * 增加该结构的尺寸,增减,重排该结构的成员时需要特别小心。保证该结构体小于64字节对于性能 * 至关重要(最常见的CPU缓存线尺寸)。 */ typedef struct BufferDesc { BufferTag tag; /* 存储在缓冲区中页面的标识 */ int buf_id; /* 缓冲区的索引编号 (从0开始) */ /* 标记的状态,包含标记位,引用计数,使用计数 */ /* 9.6使用原子操作替换了很多字段的功能 */ pg_atomic_uint32 state; int wait_backend_pid; /* 等待钉页计数的后端进程PID */ int freeNext; /* 空闲链表中的链接 */ LWLock content_lock; /* 访问缓冲内容的锁 */ } BufferDesc;
下一节:本节介绍缓冲区管理器的工作原理。当后端进程想要访问所需页面时,它会调用ReadBufferExtended函数。
函数ReadBufferExtended的行为依场景而异,在逻辑上具体可以分为三种情况。每种情况都将用一小节介绍。最后一小节将介绍PostgreSQL中基于时钟扫描(clock-sweep)的页面置换算法。