深克隆和浅克隆,考察的是Java基础知识的理解。
背景知识详解
先了解下浅克隆和深克隆的定义:
- 浅克隆 :被复制对象的所有变量都含有与原来的对象相同的值,而所有的对其他对象的引用仍然指向原来的对象。
- 深克隆 :除去那些引用其他对象的变量,被复制对象的所有变量都含有与原来的对象相同的值。那些引用其他对象的变量将指向被复制过的新对象,而不再是原有的那些被引用的对象。换言之,深复制把要复制的对象所引用的对象都复制了一遍。
如何实现克隆
我么先不管深克隆、还是浅克隆。首先,要先了解如何实现克隆,实现克隆需要满足以下三个步骤
- 对象的类实现Cloneable接口;
- 覆盖Object类的clone()方法(覆盖clone()方法,访问修饰符设为public,默认是protected,但是如果所有类都在同一个包下protected是可以访问的 );
- 在clone()方法中调用super.clone();
实现一个克隆
先定义一个score类,表示分数信息。
public class Score {
private String category;
private double fraction;
public Score() {
}
public Score(String category, double fraction) {
this.category = category;
this.fraction = fraction;
}
//getter/setter省略
@Override
public String toString() {
return "Score{" +
"category='" + category + '\'' +
", fraction=" + fraction +
'}';
}
}
定义一个Person,其中包含Score属性,来表示这个人的考试分数。
需要注意,Person类是实现了Cloneable接口的,并且重写了clone()这个方法。
public class Person implements Cloneable{
private String name;
private int age;
private List<Score> score;
public Person() {
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
克隆代码测试,代码逻辑不复杂,就是初始化一个对象mic,然后基于mic使用clone方法克隆出一个对象dylan。
接着通过修改被克隆对象mic的成员属性,打印出这两个对象的状态信息。
public class CloneMain {
public static void main(String[] args) throws CloneNotSupportedException {
Person mic=new Person();
Score s1=new Score();
s1.setCategory("语文");
s1.setFraction(90);
Score s2=new Score();
s2.setCategory("数学");
s2.setFraction(100);
mic.setAge(18);
mic.setName("Mic");
mic.setScore(Arrays.asList(s1,s2));
System.out.println("person对象初始化状态:"+mic);
Person dylan=(Person)mic.clone(); //克隆一个对象
System.out.println("打印克隆对象:dylan:"+dylan);
mic.setAge(20);
mic.getScore().get(0).setFraction(70); //修改mic语文分数为70
System.out.println("打印mic:"+mic);
System.out.println("打印dylan:"+dylan);
}
}
执行结果如下:
person对象初始化状态:Person{name='Mic', age=18, score=[Score{category='语文', fraction=90.0}, Score{category='数学', fraction=100.0}]}
打印克隆对象:dylan:Person{name='Mic', age=18, score=[Score{category='语文', fraction=90.0}, Score{category='数学', fraction=100.0}]}
打印mic:Person{name='Mic', age=20, score=[Score{category='语文', fraction=70.0}, Score{category='数学', fraction=100.0}]}
打印dylan:Person{name='Mic', age=18, score=[Score{category='语文', fraction=70.0}, Score{category='数学', fraction=100.0}]}
从结果中可以发现:
- 修改
mic对象本身的普通属性age,发现该属性的修改只影响到mic对象本身的实例。 - 当修改
mic对象的语文成绩时,dylan对象的语文成绩也发生了变化。
为什么会导致这个现象?回过头看一下浅克隆的定义:
浅克隆:创建一个新对象,新对象的属性和原来对象完全相同,对于非基本类型属性,仍指向原有属性所指向的对象的内存地址
需要特别强调
非基本类型,对于非基本类型,传递的是值,所以新的dylan对象会对该属性创建一个副本。同样,对于final修饰的属性,由于它的不可变性,在浅克隆时,也会在内存中创建副本。
如图所示,dylan对象从mic对象克隆过来后,dylan对象的内存地址指向的是同一个。因此当mic这个对象中的属性发生变化时,dylan对象的属性也会发生变化。
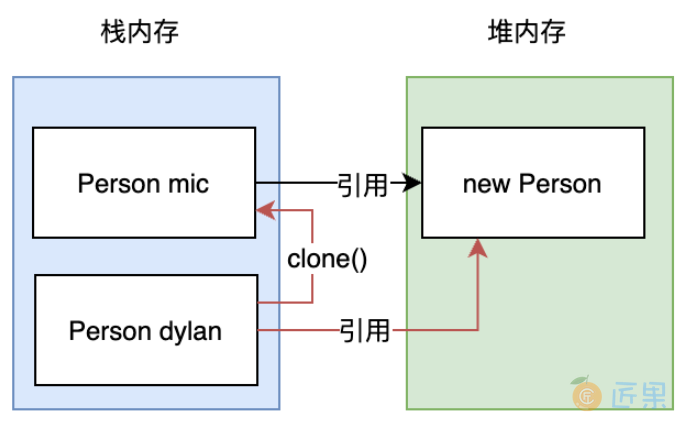
clone方法的源码分析
经过上述案例演示可以发现,如果对象实现Cloneable并重写clone方法不进行任何操作时,调用clone是进行的浅克隆,那clone方法是如何实现的呢?它默认情况下做了什么?
clone方法是Object中默认提供的,它的源码定义如下
protected native Object clone() throws CloneNotSupportedException;
从源码中我们可以看到几个关键点:
- clone方法是native方法,native方法的效率远高于非native方法,因此如果我们需要拷贝一个对象,建议使用clone,而不是new。
- 该方法被protected修饰。这就意味着想要使用,则必须重写该方法,并且设置成public。
- 返回值是一个Object对象,因此通过
clone方法克隆一个对象,需要强制转换。 - 如果在没有实现Cloneable接口的实例上调用Object的clone()方法,则会导致抛出CloneNotSupporteddException;
再来看一下Object.clone方法上的注释,注释的内容有点长。
/**
* Creates and returns a copy of this object. The precise meaning
* of "copy" may depend on the class of the object. The general
* intent is that, for any object {@code x}, the expression:
* <blockquote>
* <pre>
* x.clone() != x</pre></blockquote>
* will be true, and that the expression:
* <blockquote>
* <pre>
* x.clone().getClass() == x.getClass()</pre></blockquote>
* will be {@code true}, but these are not absolute requirements.
* While it is typically the case that:
* <blockquote>
* <pre>
* x.clone().equals(x)</pre></blockquote>
* will be {@code true}, this is not an absolute requirement.
* <p>
* By convention, the returned object should be obtained by calling
* {@code super.clone}. If a class and all of its superclasses (except
* {@code Object}) obey this convention, it will be the case that
* {@code x.clone().getClass() == x.getClass()}.
* <p>
* By convention, the object returned by this method should be independent
* of this object (which is being cloned). To achieve this independence,
* it may be necessary to modify one or more fields of the object returned
* by {@code super.clone} before returning it. Typically, this means
* copying any mutable objects that comprise the internal "deep structure"
* of the object being cloned and replacing the references to these
* objects with references to the copies. If a class contains only
* primitive fields or references to immutable objects, then it is usually
* the case that no fields in the object returned by {@code super.clone}
* need to be modified.
* <p>
* The method {@code clone} for class {@code Object} performs a
* specific cloning operation. First, if the class of this object does
* not implement the interface {@code Cloneable}, then a
* {@code CloneNotSupportedException} is thrown. Note that all arrays
* are considered to implement the interface {@code Cloneable} and that
* the return type of the {@code clone} method of an array type {@code T[]}
* is {@code T[]} where T is any reference or primitive type.
* Otherwise, this method creates a new instance of the class of this
* object and initializes all its fields with exactly the contents of
* the corresponding fields of this object, as if by assignment; the
* contents of the fields are not themselves cloned. Thus, this method
* performs a "shallow copy" of this object, not a "deep copy" operation.
* <p>
* The class {@code Object} does not itself implement the interface
* {@code Cloneable}, so calling the {@code clone} method on an object
* whose class is {@code Object} will result in throwing an
* exception at run time.
*
* @return a clone of this instance.
* @throws CloneNotSupportedException if the object's class does not
* support the {@code Cloneable} interface. Subclasses
* that override the {@code clone} method can also
* throw this exception to indicate that an instance cannot
* be cloned.
* @see java.lang.Cloneable
*/
protected native Object clone() throws CloneNotSupportedException;
上述方法中的注释描述中,对于clone方法关于复制描述,提出了三个规则,也就是说,”复制“的确切定义取决于对象本身,它可以满足以下任意一条规则:
- 对于所有对象,x.clone () !=x 应当返回 true,因为克隆对象与原对象不是同一个对象。
- 对于所有对象,x.clone ().getClass () == x.getClass () 应当返回 true,因为克隆对象与原对象的类型是一样的。
- 对于所有对象,x.clone ().equals (x) 应当返回 true,因为使用 equals 比较时,它们的值都是相同的。
因此,从clone方法的源码中可以得到一个结论,clone方法是深克隆还是浅克隆,取决于实现克隆方法对象的本身实现。
深克隆
理解了浅克隆,我们就不难猜测到,所谓深克隆的本质,应该是如下图所示。
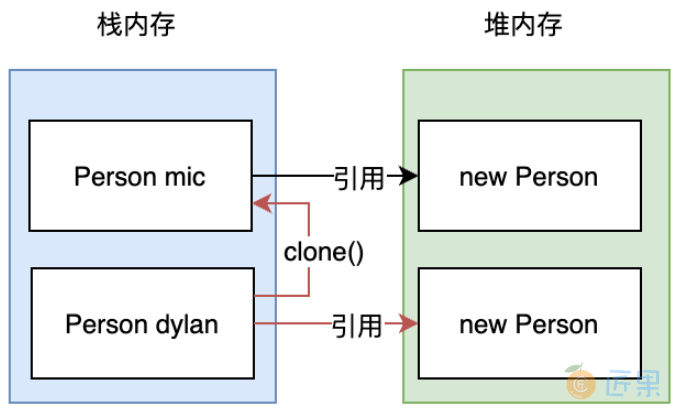
dylan这个对象实例从mic对象克隆之后,应该要分配一块新的内存地址,从而实现在内存地址上的隔离。
深拷贝实现的是对所有可变(没有被final修饰的引用变量)引用类型的成员变量都开辟独立的内存空间,使得拷贝对象和被拷贝对象之间彼此独立,因此一般深拷贝对于浅拷贝来说是比较耗费时间和内存开销的。
深克隆实现
修改Person类中的clone()方法,代码如下。
@Override
protected Object clone() throws CloneNotSupportedException {
Person p=(Person)super.clone(); //可以直接使用clone方法克隆,因为String类型中的属性是final修饰,而int是基本类型,都会创建副本
if(this.score!=null&&this.score.size()>0){ //如果score不为空时,才做深度克隆
//由于`score`是引用类型,所以需要重新分配内存空间
List<Score> ls=new ArrayList<>();
this.score.stream().forEach(score->{
Score s=new Score();
s.setFraction(score.getFraction());
s.setCategory(score.getCategory());
ls.add(s);
});
p.setScore(ls);
}
return p;
}
再次执行,运行结果如下
person对象初始化状态:Person{name='Mic', age=18, score=[Score{category='语文', fraction=90.0}, Score{category='数学', fraction=100.0}]}
打印克隆对象:dylan:Person{name='Mic', age=18, score=[Score{category='语文', fraction=90.0}, Score{category='数学', fraction=100.0}]}
打印mic:Person{name='Mic', age=20, score=[Score{category='语文', fraction=70.0}, Score{category='数学', fraction=100.0}]}
打印dylan:Person{name='Mic', age=18, score=[Score{category='语文', fraction=90.0}, Score{category='数学', fraction=100.0}]}
Process finished with exit code 0
从结果可以看到,这两个对象之间并没有相互影响,因为我们在clone方法中,对于Person这个类的成员属性Score使用new创建了一个新的对象,这样就使得两个对象分别指向不同的内存地址。
创建一个新对象,属性中引用的其他对象也会被克隆,不再指向原有对象地址。总之深浅克隆都会在堆中新分配一块区域,区别在于对象属性引用的对象是否需要进行克隆(递归性的)
深克隆的其他实现方式
深克隆的实现方式很多,总的来说有以下几种:
- 所有对象都实现克隆方法。
- 通过构造方法实现深克隆。
- 使用 JDK 自带的字节流。
- 使用第三方工具实现,比如:Apache Commons Lang。
- 使用 JSON 工具类实现,比如:Gson,FastJSON 等等。
其实,深克隆既然是在内存中创建新的对象,那么任何能够创建新实例对象的方式都能完成这个动作,因此不局限于这些方法。
所有对象都实现克隆方法
由于浅克隆本质上是因为引用对象指向同一块内存地址,如果每个对象都实现克隆方法,意味着每个对象的最基本单位是基本数据类型或者封装类型,而这些类型在克隆时会创建副本,从而避免了指向同一块内存地址的问题。修改代码如下。
public class Person implements Cloneable {
private String name;
private int age;
private List<Score> score;
public Person() {
}
@Override
protected Object clone() throws CloneNotSupportedException {
Person p=(Person)super.clone();
if(this.score!=null&&this.score.size()>0){ //如果score不为空时,才做深度克隆
//由于`score`是引用类型,所以需要重新分配内存空间
List<Score> ls=new ArrayList<>();
this.score.stream().forEach(score->{
try {
ls.add((Score)score.clone()); //这里用了克隆方法
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
});
p.setScore(ls);
}
return p;
}
}
修改Score对象
public class Score implements Cloneable {
private String category;
private double fraction;
public Score() {
}
public Score(String category, double fraction) {
this.category = category;
this.fraction = fraction;
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
Person dylan=(Person)mic.clone(); //克隆一个对象
运行结果如下
person对象初始化状态:Person{name='Mic', age=18, score=[Score{category='语文', fraction=90.0}, Score{category='数学', fraction=100.0}]}
打印克隆对象:dylan:Person{name='Mic', age=18, score=[Score{category='语文', fraction=90.0}, Score{category='数学', fraction=100.0}]}
打印mic:Person{name='Mic', age=20, score=[Score{category='语文', fraction=70.0}, Score{category='数学', fraction=100.0}]}
打印dylan:Person{name='Mic', age=18, score=[Score{category='语文', fraction=90.0}, Score{category='数学', fraction=100.0}]}
通过构造方法实现深克隆。
构造方法实现深克隆,其实是我们经常使用的方法,就是使用new关键字来实例化一个新的对象,然后通过构造参数传值来实现数据拷贝。
public class Person implements Cloneable {
private String name;
private int age;
private List<Score> score;
public Person() {
}
public Person(String name, int age, List<Score> score) {
this.name = name;
this.age = age;
this.score = score;
}
}
克隆的时候,我们这么做
Person dylan=new Person(mic.getName(),mic.getAge(),mic.getScore()); //克隆一个对象
基于ObjectStream实现深克隆
在Java中,对象流也可以实现深克隆,大家可能对对象流这个名词有点陌生,它的定义如下:
- ObjectOutputStream, 对象输出流,把一个对象转换为二进制格式数据
- ObjectInputStream,对象输入流,把一个二进制数据转换为对象。
这两个对象,在Java中通常用来实现对象的序列化。
创建一个工具类,使用ObjectStream来实现对象的克隆,代码实现逻辑不难:
- 使用ObjectOutputStream,把一个对象转换为数据流存储到对象ByteArrayOutputStream中。
- 再从内存中读取该数据流,使用ObjectInputStream,把该数据流转换为目标对象。
public class ObjectStreamClone {
public static <T extends Serializable> T clone(T t){
T cloneObj = null;
try {
// bo,存储对象输出流,写入到内存
ByteArrayOutputStream bo = new ByteArrayOutputStream();
//对象输出流,把对象转换为数据流
ObjectOutputStream oos = new ObjectOutputStream(bo);
oos.writeObject(t);
oos.close();
// 分配内存,写入原始对象,生成新对象
ByteArrayInputStream bi = new ByteArrayInputStream(bo.toByteArray());
ObjectInputStream oi = new ObjectInputStream(bi);
// 返回生成的新对象
cloneObj = (T) oi.readObject();
oi.close();
} catch (Exception e) {
e.printStackTrace();
}
return cloneObj;
}
}
Person对象和Score对象均需要实现Serializable接口,
public class Person implements Serializable {
}
public class Score implements Serializable {}
修改测试类的克隆方法.
Person dylan=(Person)ObjectStreamClone.clone(mic); //克隆一个对象
运行结果如下:
person对象初始化状态:Person{name='Mic', age=18, score=[Score{category='语文', fraction=90.0}, Score{category='数学', fraction=100.0}]}
打印克隆对象:dylan:Person{name='Mic', age=18, score=[Score{category='语文', fraction=90.0}, Score{category='数学', fraction=100.0}]}
打印mic:Person{name='Mic', age=20, score=[Score{category='语文', fraction=70.0}, Score{category='数学', fraction=100.0}]}
打印dylan:Person{name='Mic', age=18, score=[Score{category='语文', fraction=90.0}, Score{category='数学', fraction=100.0}]}
通过对象流能够实现深克隆,其根本原因还是在于对象的序列化之后,已经脱离了JVM内存对象的范畴,毕竟一个对象序列化之后,是可以通过文件、或者网络跨JVM传输的,因此对象在反序列化时,必然需要基于该数据流重新反射生成新的对象。
问题解答
问题:深克隆和浅克隆的实现方式
回答:
- 浅克隆是指被复制对象中属于引用类型的成员变量的内存地址和被克隆对象的内存地址相同,也就是克隆对象只实现了对被克隆对象基本类型的副本克隆。 浅克隆的实现方式,可以实现Cloneable接口,并重写clone方法,即可完成浅克隆。 浅克隆的好处是,避免了引用对象的内存分配和回收,提高对象的复制效率。
- 深克隆时指实现对于基本类型和引用类型的完整克隆,克隆对象和被克隆对象中的引用对象的内存地址完全隔离。
深克隆的实现方式:
- 基于Cloneable接口重写clone方法,但是我们需要在clone方法中,针对应用类型的成员变量,使用
new关键字分配独立的内存空间。 - 基于Java中对象流的方式实现
- 基于构造方法实现深度克隆
- 被克隆的对象中所有涉及到引用类型变量的对象,全部实现克隆方法,并且在被克隆对象的clone方法中,需要调用所有成员对象的clone方法实现对象克隆
- 基于Cloneable接口重写clone方法,但是我们需要在clone方法中,针对应用类型的成员变量,使用
问题总结
深克隆的本质,其实是保证被克隆对象中所有应用对象以及引用所嵌套的引用对象,全部分配一块独立的内存空间,避免克隆对象和被克隆对象指向同一块内存地址,造成数据错误等问题。
所以,深克隆,表示对象拷贝的深度,因为在Java中对象的嵌套是非常常见的。理解了这个知识点,才能避免在开发过程中遇到一些奇奇怪怪的问题。
下一节:了解面试者对JVM的理解,属于面试八股文系列。