本节的最后一部分,我们回过头来探讨开篇提出的问题:Kubernetes 是如何撮合 Pod 与 Node 的,这其实也是最困难的一个问题。调度是为新创建出来的 Pod 寻找到一个最恰当的宿主机节点去运行它,这句话里就包含有“运行”和“恰当”两个调度中关键过程,它们具体是指:
- 运行 :从集群所有节点中找出一批剩余资源可以满足该 Pod 运行的节点。为此,Kubernetes 调度器设计了一组名为 Predicate 的筛选算法。
- 恰当 :从符合运行要求的节点中找出一个最适合的节点完成调度。为此,Kubernetes 调度器设计了一组名为 Priority 的评价算法。
这两个算法的具体内容稍后笔者会详细解释,这里要先说明白一点:在几个、十几个节点的集群里进行调度,调度器怎么实现都不会太困难,但是对于数千个乃至更多节点的大规模集群,要实现高效的调度就绝不简单。请你想象一下,若一个由数千节点组成的集群,每次 Pod 的创建都必须依据各节点的实时资源状态来确定调度的目标节点,然而各节点的资源是随着程序运行无时无刻都在变动的,资源状况只有它本身才清楚,如果每次调度都要发生数千次的远程访问来获取这些信息的话,那压力与耗时都难压降下来。结果不仅会令调度器成为集群管理的性能瓶颈,还会出现因耗时过长,某些节点上资源状况已发生变化,调度器的资源信息过时而导致调度结果不准确的等问题。
Scheduler
Clusters and their workloads keep growing, and since the scheduler’s workload is roughly proportional to the cluster size, the scheduler is at risk of becoming a scalability bottleneck.
由于调度器的工作负载与集群规模大致成正比,随着集群和它们的工作负载不断增长,调度器很有可能会成为扩展性瓶颈所在。
—— Omega: Flexible, Scalable Schedulers for Large Compute Clusters,Google
针对以上问题,Google 在论文《Omega: Flexible, Scalable Schedulers for Large Compute Clusters》里总结了自身的经验,并参考了当时Apache Mesos和Hadoop on Demand(HOD)的实现,提出了一种共享状态(Shared State)的双循环调度机制。这种调度机制后来不仅应用在 Google 的 Omega 系统(Borg 的下一代集群管理系统)中,也同样被 Kubernetes 继承了下来,它整体的工作流程如图 14-1 所示:
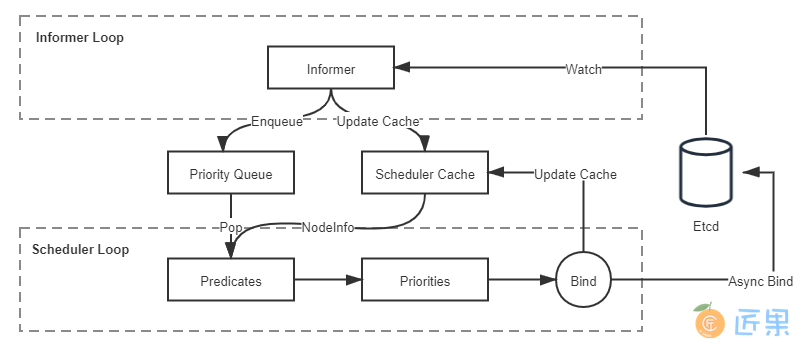
状态共享的双循环”中第一个控制循环可被称为“Informer Loop”,它是一系列Informer的集合,这些 Informer 持续监视 Etcd 中与调度相关资源(主要是 Pod 和 Node)的变化情况,一旦 Pod、Node 等资源出现变动,就会触发对应 Informer 的 Handler。Informer Loop 的职责是根据 Etcd 中的资源变化去更新调度队列(Priority Queue)和调度缓存(Scheduler Cache)中的信息,譬如当有新 Pod 生成,就将其入队(Enqueue)到调度队列中,如有必要,还会根据优先级触发上一节提到的插队和抢占操作。又譬如有新的节点加入集群,或者已有节点资源信息发生变动,Informer 也会将这些信息更新同步到调度缓存之中。
另一个控制循环可被称为“Scheduler Loop”,它的核心逻辑是不停地将调度队列中的 Pod 出队(Pop),然后使用 Predicate 算法进行节点选择。Predicate 本质上是一组节点过滤器(Filter),它根据预设的过滤策略来筛选节点,Kubernetes 中默认有三种过滤策略,分别是:
- 通用过滤策略 :最基础的调度过滤策略,用来检查节点是否能满足 Pod 声明中需要的资源。譬如处理器、内存资源是否满足,主机端口与声明的 NodePort 是否存在冲突,Pod 的选择器或者nodeAffinity指定的节点是否与目标相匹配,等等。
- 卷过滤策略 :与存储相关的过滤策略,用来检查节点挂载的 Volume 是否存在冲突(譬如将一个块设备挂载到两个节点上),或者 Volume 的 客户端负载均衡 是否与目标节点冲突,等等。在“ Kubernetes 存储设计 ”中提到的 Local PersistentVolume 的调度检查,便是在这里处理的。
- 节点过滤策略 :与宿主机相关的过滤策略,最典型的是 Kubernetes 的污点与容忍度机制(Taints and Tolerations),譬如默认情况下 Kubernetes 会设置 Master 节点不允许被调度,这就是通过在 Master 中施加污点来避免的。之前提到的控制节点处于驱逐状态,或者在驱逐后一段时间不允许调度,也是在这个策略里实现的。
Predicate 算法所使用的一切数据均来自于调度缓存,绝对不会去远程访问节点本身。只有 Informer Loop 与 Etcd 的监视操作才会涉及到远程调用,Scheduler Loop 中除了最后的异步绑定要发起一次远程的 Etcd 写入外,其余全部都是进程内访问,这一点是调度器执行效率的重要保证。
调度缓存就是两个控制循环的共享状态(Shared State),这样的设计避免了每次调度时主动去轮询所有集群节点,保证了调度器的执行效率。但是并不能完全避免因节点信息同步不及时而导致调度过程中实际资源发生变化的情况,譬如节点的某个端口在获取调度信息后、发生实际调度前被意外占用了。为此,当调度结果出来以后,kubelet 真正创建 Pod 以前,还必须执行一次 Admit 操作,在该节点上重新做一遍 Predicate 来进行二次确认。
经过 Predicate 算法筛选出来符合要求的节点集,会交给 Priorities 算法来打分(0-10 分)排序,以便挑选出“最恰当”的一个。“恰当”是带有主观色彩的词语,Kubernetes 也提供了不同的打分规则来满足不同的主观需求,譬如最常用的 LeastRequestedPriority 规则,它的计算公式是:
score = (cpu((capacity-sum(requested))×10/capacity) + memory((capacity-sum(requested))×10/capacity))/2
从公式上很容易看出这就是在选择处理器和内存空闲资源最多的节点,因为这些资源剩余越多,得分就越高。经常与它一起工作的是 BalancedResourceAllocation 规则,它的公式是:
score = 10 - variance(cpuFraction,memoryFraction,volumeFraction)×10
此公式中 cpuFraction、memoryFraction、volumeFraction 的含义分别是 Pod 请求的处理器、内存和存储资源占该节点上对应可用资源的比例,variance 函数的作用是计算资源之间的差距,差距越大,函数值越大。由此可知 BalancedResourceAllocation 规则的意图是希望调度完成后,所有节点里各种资源分配尽量均衡,避免节点上出现诸如处理器资源被大量分配、而内存大量剩余的尴尬状况。Kubernetes 内置的其他的评分规则还有 ImageLocalityPriority、NodeAffinityPriority、TaintTolerationPriority 等等,有兴趣的话可以阅读 Kubernetes 的源码,笔者就不再逐一解释了。
经过 Predicate 的筛选、Priorities 的评分之后,调度器已经选出了调度的最终目标节点,最后一步是通知目标节点的 kubelet 可以去创建 Pod 了。调度器并不会直接与 kubelet 通讯来创建 Pod,它只需要把待调度的 Pod 的nodeName字段更新为目标节点的名字即可,kubelet 本身会监视该值的变化来接手后续工作。不过,从调度器在 Etcd 中更新nodeName,到 kubelet 从 Etcd 中检测到变化,再执行 Admit 操作二次确认调度可行性,最后到 Pod 开始实际创建,这个过程可能会持续一段不短的时间,如果一直等待这些工作都完成了才宣告调度最终完成,那势必也会显著影响调度器的效率。实际上 Kubernetes 调度器采用了乐观绑定(Optimistic Binding)的策略来解决此问题,它会同步地更新调度缓存中 Pod 的nodeName字段,并异步地更新 Etcd 中 Pod 的nodeName字段,这个操作被称为绑定(Binding)。如果最终调度成功了,那 Etcd 与调度缓存中的信息最终必定会保持一致,否则,如果调度失败了,那将会由 Informer 来根据 Pod 的变动,将调度成功却没有创建成功的 Pod 清空nodeName字段,重新同步回调度缓存中,以便促使另外一次调度的开始。
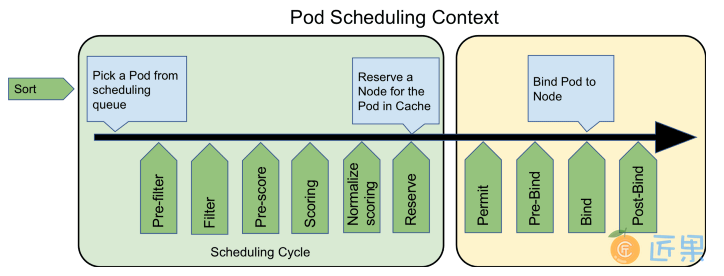
最后,请注意笔者在这一个部分的小标题用的是“默认 调度器”,这是强调以上行为仅是 Kubernetes 默认的行为。对调度过程的大部分行为,你都可以通过 Scheduler Framework 暴露的接口来进行扩展和自定义,如下图所示,绿色的部分就是 Scheduler Framework 暴露的扩展点。由于 Scheduler Framework 属于 Kubernetes 内部的扩展机制(通过 Golang 的 Plugin 机制来实现的,需静态编译),通用性与本章提到的其他扩展机制(CRI、CNI、CSI 那些)无法相提并论,属于较为高级的 Kubernetes 管理技能了,这里笔者仅在这里简单地提一下,就不多做介绍了。