无噪编码就是哈夫曼编码,它的作用在于进一步减少尺度因子和量化后频谱的冗余,即将尺度因子和量化后的频谱信息进行哈夫曼编码。
全局增益编码成一个8位的无符号整数,第一个尺度因子与全局增益值进行差分编码后再使用尺度因子编码表进行哈夫曼编码。后续的各尺度因子都与前一个尺度因子进行差分编码。
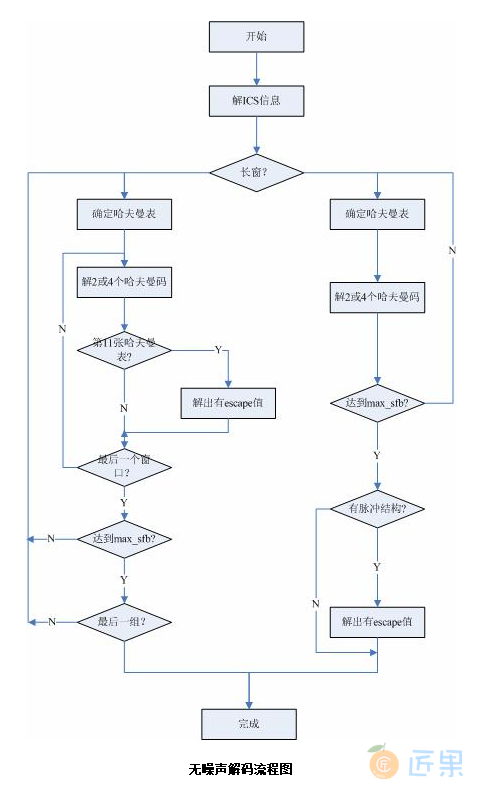
量化频谱的无噪编码有两个频谱系数的划分。其一为4元组和2元组的划分,另一个为节划分。对前一个划分来说,确定了一次哈夫曼表查找出的数值是4个还是2个。对后一个划分来说,确定了应该用哪一个哈夫曼表,一节中含有若干的尺度因子带并且每节只用一个哈夫曼表。
分段
无噪声编码将输入的1024个量化频谱系数分为几个段(section),段内的各点均使用同一个哈夫曼表,考虑到编码效率,每一段的边界最好同尺度因子带的边界重合。所以每一段必段传送信息应该有:段长度,所在的尺度因子带,使用的哈夫曼表。
分组和交替
分组是指忽略频谱系数所在窗,将连续的,具有相同尺度因子带的频谱系数分为一组放在一起,共享一个尺度因子从而得到更好的编码效率。这样做必然会引起交替,即本来是以 c[组][窗][尺度因子带][ 系数索引] 为顺序的系数排列,变为将尺度因子带同的系数放在一起:c[组][尺度因子带][窗][ 系数索引] 这样就引起了相同窗的系数的交替。
大量化值的处理
大量化值在AAC中有两种处理方法:在哈夫曼编码表中使用escape标志或使用脉冲escape方法。前者跟mp3编码方法相似,在许多大量化值出现时采用专门的哈夫曼表,这个表暗示了它的使用将会在哈夫曼编码后面跟跟一对escape值及对值的符号。在用脉冲escape方法时,大数值被减去一个差值变为小数值,然后使用哈夫曼表编码,后面会跟一个脉冲结构来帮助差值的还原。