看了很多版本的解释,发现李开复在《⼈⼯智能》⼀书中讲的是最容易理解的,所以下⾯直接引⽤他的解释:
我们以识别图⽚中的汉字为例。假设深度学习要处理的信息是“⽔流”,⽽处理数据的深度学习⽹络是⼀个由管道和阀⻔组成的巨⼤⽔管⽹络。⽹络的⼊⼝是若⼲管道开⼝,⽹络的出⼝也是若⼲管道开⼝。这个⽔管⽹络有许多层,每⼀层由许多个可以控制⽔流流向与流量的调节阀。根据不同任务的需要,⽔管⽹络的层数、每层的调节阀数量可以有不同的变化组合。对复杂任务来说,调节阀的总数可以成千上万甚⾄更多。⽔管⽹络中,每⼀层的每个调节阀都通过⽔管与下⼀层的所有调节阀连接起来,组成⼀个从前到后,逐层完全连通的⽔流系统。
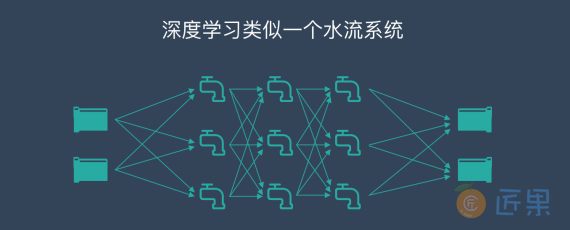
那么,计算机该如何使⽤这个庞⼤的⽔管⽹络来学习识字呢?
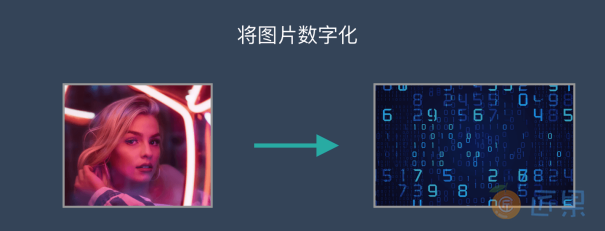
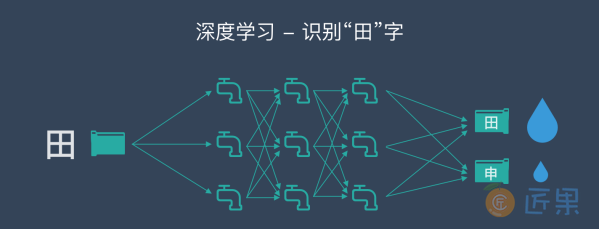
⽐如,当计算机看到⼀张写有“⽥”字的图⽚,就简单将组成这张图⽚的所有数字(在计算机⾥,图⽚的每个颜⾊点都是⽤“0”和“1”组成的数字来表示的)全都变成信息的⽔流,从⼊⼝灌进⽔管⽹络。
我们预先在⽔管⽹络的每个出⼝都插⼀块字牌,对应于每⼀个我们想让计算机认识的汉字。这时,因为输⼊的是“⽥”这个汉字,等⽔流流过整个⽔管⽹络,计算机就会跑到管道出⼝位置去看⼀看,是不是标记由“⽥”字的管道出⼝流出来的⽔流最多。如果是这样,就说明这个管道⽹络符合要求。如果不是这样,就调节⽔管⽹络⾥的每⼀个流量调节阀,让“⽥”字出⼝“流出”的⽔最多。
这下,计算机要忙⼀阵了,要调节那么多阀⻔!好在计算机的速度快,暴⼒的计算加上算法的优化,总是可以很快给出⼀个解决⽅案,调好所有阀⻔,让出⼝处的流量符合要求。
下⼀步,学习“申”字时,我们就⽤类似的⽅法,把每⼀张写有“申”字的图⽚变成⼀⼤堆数字组成的⽔流,灌进⽔管⽹络,看⼀看,是不是写有“申”字的那个管道出⼝流⽔最多,如果不是,我们还得再调整所有的阀⻔。这⼀次,要既保证刚才学过的“⽥”字不受影响,也要保证新的“申”字可以被正确处理。
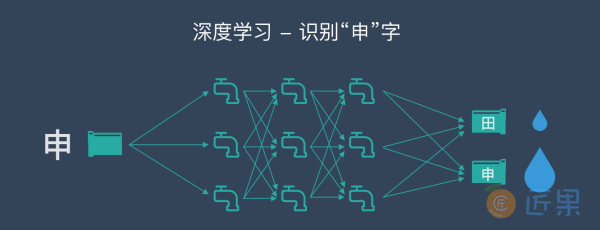
如此反复进⾏,知道所有汉字对应的⽔流都可以按照期望的⽅式流过整个⽔管⽹络。这时,我们就说,这个⽔管⽹络是⼀个训练好的深度学习模型了。当⼤量汉字被这个管道⽹络处理,所有阀⻔都调节到位后,整套⽔管⽹络就可以⽤来识别汉字了。这时,我们可以把调节好的所有阀⻔都“焊死”,静候新的⽔流到来。
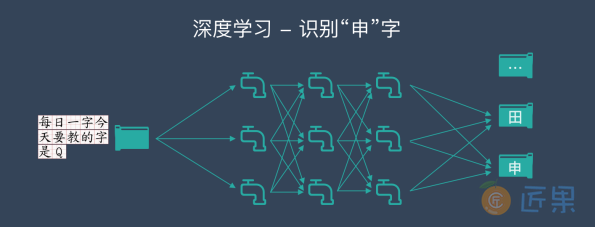
与训练时做的事情类似,未知的图⽚会被计算机转变成数据的⽔流,灌⼊训练好的⽔管⽹络。这时,计算机只要观察⼀下,哪个出⽔⼝流出来的⽔流最多,这张图⽚写的就是哪个字。
深度学习⼤致就是这么⼀个⽤⼈类的数学知识与计算机算法构建起来的整体架构,再结合尽可能多的训练数据以及计算机的⼤规模运算能⼒去调节内部参数,尽可能逼近问题⽬标的半理论、半经验的建模⽅式。