因为per-segment search机制,索引和搜索一个文档之间是有延迟的。新的文档会在几分钟内可以搜索,但是这依然不够快。磁盘是瓶颈。提交一个新的段到磁盘需要fsync操作,确保段被物理地写入磁盘,即时电源失效也不会丢失数据。但是fsync是昂贵的,它不能在每个文档被索引的时就触发。所以需要一种更轻量级的方式使新的文档可以被搜索,这意味这移除fsync。
位于Elasticsearch和磁盘间的是文件系统缓存。如前所说,在内存索引缓存中的文档(图1)被写入新的段(图2),但是新的段首先写入文件系统缓存,这代价很低,之后会被同步到磁盘,这个代价很大。但是一旦一个文件被缓存,它也可以被打开和读取,就像其他文件一样。
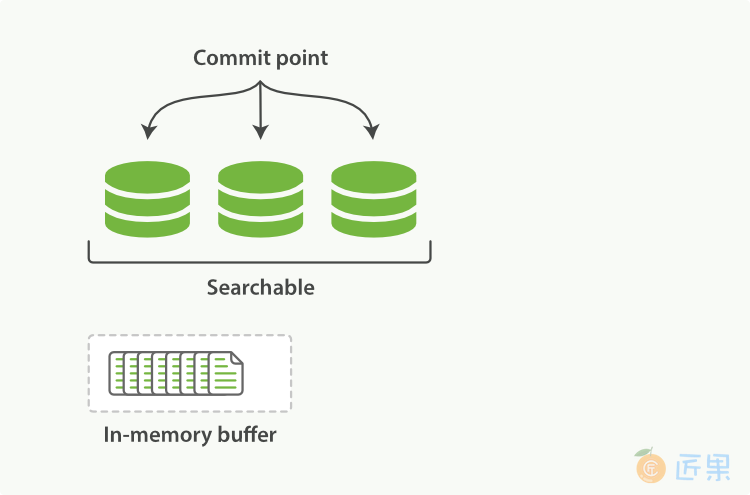
Lucene允许新段写入打开,好让它们包括的文档可搜索,而不用执行一次全量提交。这是比提交更轻量的过程,可以经常操作,而不会影响性能。

refeash API
在Elesticsearch中,这种写入打开一个新段的轻量级过程,叫做refresh。默认情况下,每个分片每秒自动刷新一次。这就是为什么说Elasticsearch是近实时的搜索了:文档的改动不会立即被搜索,但是会在一秒内可见。
这会困扰新用户:他们索引了个文档,尝试搜索它,但是搜不到。解决办法就是执行一次手动刷新,通过API:
POST /_refresh <1>
POST /blogs/_refresh <2>
- <1> refresh所有索引
- <2> 只refresh 索引
blogs
虽然刷新比提交更轻量,但是它依然有消耗。人工刷新在测试写的时有用,但是不要在生产环境中每写一次就执行刷新,这会影响性能。相反,你的应用需要意识到ES近实时搜索的本质,并且容忍它。
不是所有的用户都需要每秒刷新一次。也许你使用ES索引百万日志文件,你更想要优化索引的速度,而不是进实时搜索。你可以通过修改配置项refresh_interval减少刷新的频率:
PUT /my_logs
{
"settings": {
"refresh_interval": "30s" <1>
}
}
- <1> 每30s refresh一次
my_logs
refresh_interval可以在存在的索引上动态更新。你在创建大索引的时候可以关闭自动刷新,在要使用索引的时候再打开它。
PUT /my_logs/_settings
{ "refresh_interval": -1 } <1>
PUT /my_logs/_settings
{ "refresh_interval": "1s" } <2>
- <1> 禁用所有自动refresh
- <2> 每秒自动refresh