当前,几乎所有互联网上的内容都采用HTTP 1.1作为通信协议。人们在该协议上投入了大量精力,因此基于该协议的基础架构得以日臻完善。得益于此,在现有的HTTP协议之上构建新的方案会比从底层建立新的协议要容易得多。
2.1 HTTP 1.1过于庞大
HTTP刚诞生的时候被看作一个相对简单直观的协议,但时间证明了早期的设计并不尽人意。于1996年发布的、描述HTTP 1.0规范的RFC 1945只有60页,但仅仅3年之后,描述HTTP 1.1规范的RFC 2616就骤增至176页。当我们在IETF小组对该规范进行更新时,更是被拆分成了总页数更多的六个文档(这就是RFC 7230及其文件族的由来与诞生)。总而言之,HTTP 1.1包含了太多细节和可选内容,这让它变得过于庞大。
2.2 过多的可选项
HTTP 1.1不仅包含了非常多的细枝末节,也为未来的扩展预留了很多选项。这种事无巨细的风格导致在现有的软件生态中,几乎没有任何实际场景真正实现了协议中提及的所有细节,甚至要弄清楚“所有细节”到底包括哪些内容都非常困难。这也导致了很多最初不常用的功能在后来的实现中得到很少支持,而有些最初实现了的功能,却又很少被使用。
随着时间推移,当客户端和服务器开始增加对于这些功能的使用时,互用性(interoperability)问题就暴露了出来。HTTP管线化(HTTP Pipelining)就是一个非常好的例子。
2.3 未能被充分利用的TCP
HTTP 1.1很难完全使用出TCP协议能提供的所有强大能力。HTTP客户端和浏览器必须要另辟蹊径,去寻找新的解决方案来降低页面载入时间。
与此同时,人们也尝试使用新的协议来替代TCP,但结果证明这也非常困难。无奈之下,我们只能尝试同时改进TCP协议本身和基于TCP的上层协议。
简单来说,我们可以通过更好的利用TCP来减少传输过程中的中断,并充分挖掘利用那些本可以用于发送/接受更多数据的时间。下面几段我们将会着重讨论这些问题。
2.4 传输大小和资源数量
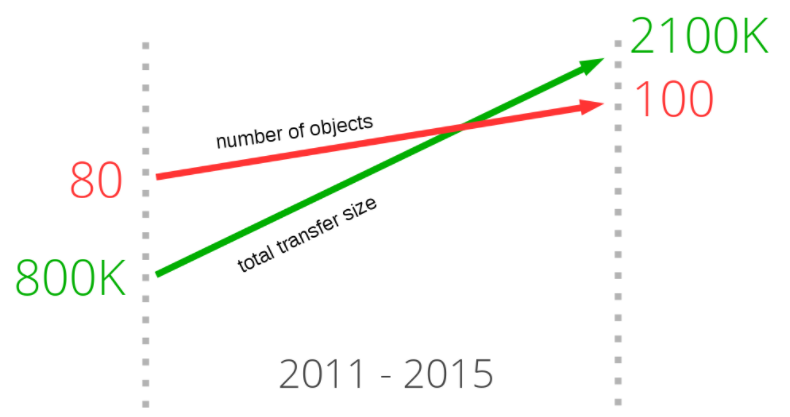
如果仔细观察那些最流行的网站首页所需要下载的资源,会发现一个非常明显的趋势。近年来加载网站首页接受的数据量在逐渐增加,并已经超过了1.9MB。但更重要的是:平均每个页面为了完成渲染需要加载超过100个独立资源。
正如下图所示,这种趋势已经持续了很长一段时间,并且没有减缓的迹象。该图表中绿色直线展示了传输数据大小的增长,红色直线展示了平均请求资源数量的增长。
2.5 恼人的延迟
HTTP 1.1对网络延迟非常敏感。部分原因是HTTP Pipelining还存有很多问题,所以对大部分用户来说这项技术是被默认关闭的。
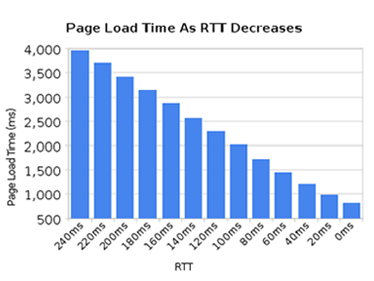
虽然近几年来网络带宽增长非常快,然而我们却并没有看到网络延迟有对应程度的降低。在高延迟的网络环境中(比如移动设备),即使拥有高连接速率,也很难获得优质快速的网络体验。
另外一个需要低延迟的场景是某些视频服务,如视频会议、游戏和其它类似无法预先发送资源请求的情况。
2.6 线头阻塞(Head of line blocking)
HTTP Pipelining是这样一种技术:在等待上一个请求响应的同时,发送下一个请求。(译者注:作者这个解释并不完全正确,HTTP Pipelining其实是把多个HTTP请求放到一个TCP连接中一一发送,而在发送过程中不需要等待服务器对前一个请求的响应;只不过,客户端还是要按照发送请求的顺序来接收响应。)但就像在超市收银台或者银行柜台排队时一样,你并不知道前面的顾客是干脆利索的还是会跟收银员/柜员磨蹭到世界末日(译者注:不管怎么说,服务器(即收银员/柜员)是要按照顺序处理请求的,如果前一个请求非常耗时(顾客磨蹭),那么后续请求都会受到影响),这就是所谓的线头阻塞(Head of line blocking)。
当然,你可以在选择队伍时就做足准备,去排一个你认为最快的队伍,或者甚至另起一个新的队伍(译者注:即新建一个TCP连接)。但不管怎么样,你总归得先选择一个队伍,而且一旦选定之后,就不能更换队伍。
但是,另起新队伍会导致资源耗费和性能损失(译者注:新建 TCP 连接的开销非常大)。这种另起新队伍的方式只在新队伍数量很少的情况下有作用,因此它并不具备可扩展性。(译者注:这段话意思是说,靠大量新建连接是不能有效解决延迟问题的,即HTTP Pipelining并不能彻底解决Head of line blocking问题。)所以针对此问题并没有完美的解决方案。
这就是为什么,即使在2015年的今天,大部分桌面浏览器仍然会选择默认关闭HTTP pipelining这一功能的原因。关于这个问题的更多细节,可以参阅Firefox的 bugzilla #264354。