MongoDB 的聚合框架以数据处理管道(Pipeline)的概念为模型。
Pipeline 简介
MongoDB 的聚合框架以数据处理管道(Pipeline)的概念为模型。
MongoDB 通过 db.collection.aggregate() (opens new window)方法支持聚合操作 。并提供了 aggregate (opens new window)命令来执行 pipeline。
MongoDB Pipeline 由多个阶段(stages (opens new window))组成。每个阶段在 document 通过 pipeline 时都会对其进行转换。pipeline 阶段不需要为每个输入 document 都生成一个输出 document。例如,某些阶段可能会生成新 document 或过滤 document。
同一个阶段可以在 pipeline 中出现多次,但 $out (opens new window)、$merge (opens new window),和 $geoNear (opens new window)阶段除外。所有可用 pipeline 阶段可以参考:Aggregation Pipeline Stages (opens new window)。
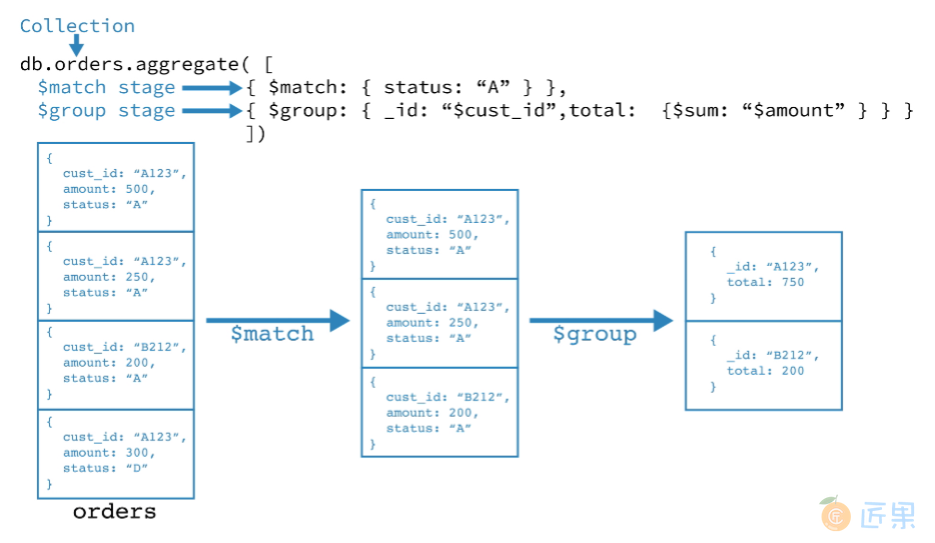
- 第一阶段:
$match(opens new window)阶段按状态字段过滤 document,然后将状态等于“ A”的那些 document 传递到下一阶段。 - 第二阶段:
$group(opens new window)阶段按 cust_id 字段对 document 进行分组,以计算每个唯一 cust_id 的金额总和。
最基本的管道阶段提供过滤器,其操作类似于查询和 document 转换(修改输出 document 形式)。其他管道操作提供了用于按特定字段对 document 进行分组和排序的工具,以及用于汇总数组(包括 document 数组)内容的工具。另外,管道阶段可以将运算符用于诸如计算平均值或连接字符串之类的任务。聚合管道也可以在分片 collection 上操作。
Pipeline 优化
投影优化
Pipeline 可以确定是否仅需要 document 中必填字段即可获得结果。
Pipeline 串行优化
($project、$unset、$addFields、$set) + $match 串行优化
对于包含投影阶段($project (opens new window)或 $unset (opens new window)或 $addFields (opens new window)或 $set (opens new window)),且后续跟随着 $match (opens new window)阶段的 Pipeline ,MongoDB 会将所有 $match (opens new window)阶段中不需要在投影阶段中计算出的值的过滤器,移动一个在投影阶段之前的新 $match (opens new window)阶段。
如果 Pipeline 包含多个投影阶段 和 / 或 $match (opens new window)阶段,则 MongoDB 将为每个 $match (opens new window)阶段执行此优化,将每个 $match (opens new window)过滤器移动到该过滤器不依赖的所有投影阶段之前。
【示例】Pipeline 串行优化示例
优化前:
{ $addFields: {
maxTime: { $max: "$times" },
minTime: { $min: "$times" }
} },
{ $project: {
_id: 1, name: 1, times: 1, maxTime: 1, minTime: 1,
avgTime: { $avg: ["$maxTime", "$minTime"] }
} },
{ $match: {
name: "Joe Schmoe",
maxTime: { $lt: 20 },
minTime: { $gt: 5 },
avgTime: { $gt: 7 }
} }
优化后:
{ $match: { name: "Joe Schmoe" } },
{ $addFields: {
maxTime: { $max: "$times" },
minTime: { $min: "$times" }
} },
{ $match: { maxTime: { $lt: 20 }, minTime: { $gt: 5 } } },
{ $project: {
_id: 1, name: 1, times: 1, maxTime: 1, minTime: 1,
avgTime: { $avg: ["$maxTime", "$minTime"] }
} },
{ $match: { avgTime: { $gt: 7 } } }
说明:
{ name: "Joe Schmoe" } 不需要计算任何投影阶段的值,所以可以放在最前面。
{ avgTime: { $gt: 7 } } 依赖 $project (opens new window)阶段的 avgTime 字段,所以不能移动。
maxTime 和 minTime 字段被 $addFields (opens new window)阶段所依赖,但自身不依赖其他,所以会新建一个 $match (opens new window)阶段,并将其置于 $project (opens new window)阶段之前。
Pipeline 并行优化
如果可能,优化阶段会将 Pipeline 阶段合并到其前身。通常,合并发生在任意序列重新排序优化之后。
$sort + $limit
当 $sort (opens new window)在 $limit (opens new window)之前时,如果没有中间阶段修改文档数量(例如 $unwind (opens new window)、$group (opens new window)),则优化程序可以将 $limit (opens new window)合并到 $sort (opens new window)中。如果有管道阶段更改了 $sort (opens new window)和 $limit (opens new window)阶段之间的文档数,则 MongoDB 不会将 $limit (opens new window)合并到 $sort (opens new window)中。
【示例】$sort + $limit
优化前:
{ $sort : { age : -1 } },
{ $project : { age : 1, status : 1, name : 1 } },
{ $limit: 5 }
优化后:
{
"$sort" : {
"sortKey" : {
"age" : -1
},
"limit" : NumberLong(5)
}
},
{ "$project" : {
"age" : 1,
"status" : 1,
"name" : 1
}
}
$limit + $limit
如果一个 $limit (opens new window)紧随另一个 $limit (opens new window),那么它们可以合并为一。
优化前:
{ $limit: 100 },
{ $limit: 10 }
优化后:
{
$limit: 10
}
$skip + $skip
如果一个 $skip (opens new window)紧随另一个 $skip (opens new window),那么它们可以合并为一。
优化前:
{ $skip: 5 },
{ $skip: 2 }
优化后:
{
$skip: 7
}
$match + $match
如果一个 $skip (opens new window)紧随另一个 $skip (opens new window),那么它们可以通过 $and (opens new window)合并为一。
优化前:
{ $match: { year: 2014 } },
{ $match: { status: "A" } }
优化后:
{
$match: {
$and: [{ year: 2014 }, { status: 'A' }]
}
}
$lookup + $unwind
如果一个 $unwind (opens new window)紧随另一个 $lookup (opens new window),并且 $unwind (opens new window)在 $lookup (opens new window)的 as 字段上运行时,优化程序可以将 $unwind (opens new window)合并到 $lookup (opens new window)阶段。这样可以避免创建较大的中间文档。
优化前:
{
$lookup: {
from: "otherCollection",
as: "resultingArray",
localField: "x",
foreignField: "y"
}
},
{ $unwind: "$resultingArray"}
优化后:
{
$lookup: {
from: "otherCollection",
as: "resultingArray",
localField: "x",
foreignField: "y",
unwinding: { preserveNullAndEmptyArrays: false }
}
}
Pipeline 限制
结果集中的每个文档均受 BSON 文档大小限制(当前为 16 MB)。Pipeline 的内存限制为 100 MB。
下一节:聚合 pipeline 比 map-reduce 提供更好的性能和更一致的接口。