1、HTTP与HTTPS有什么区别?
HTTPS是一种通过计算机网络进行安全通信的传输协议。HTTPS经由HTTP进行通信,但利用SSL/TLS来加密数据包。HTTPS开发的主要目的,是提供对网站服务器的身份 认证,保护交换数据的隐私与完整性。
HTPPS和HTTP的概念:
httpS(全称:Hypertext Transfer Protocol over Secure Socket Layer),是以安全为目标的HTTP通道,简单讲是HTTP的安全版。即HTTP下加入SSL层,https的安全基础是SSL,因此加密的详细内容就需要SSL。 它是一个URI scheme(抽象标识符体系),句法类同http:体系。用于安全的HTTP数据传输。https:URL表明它使用了HTTP,但HTTPS存在不同于HTTP的默认端口及一个加密/身份验证层(在HTTP与TCP之间)。这个系统的最初研发由网景公司进行,提供了身份验证与加密通讯方法,现在它被广泛用于万维网上安全敏感的通讯,例如交易支付方面。
超文本传输协议 (HTTP-Hypertext transfer protocol) 是一种详细规定了浏览器和万维网服务器之间互相通信的规则,通过因特网传送万维网文档的数据传送协议。
https协议需要到ca申请证书,一般免费证书很少,需要交费。http是超文本传输协议,信息是明文传输,https 则是具有安全性的ssl加密传输协议http和https使用的是完全不同的连接方式用的端口也不一样,前者是80,后者是443。http的连接很简单,是无状态的HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议 要比http协议安全HTTPS解决的问题:1 . 信任主机的问题. 采用https 的server 必须从CA 申请一个用于证明服务器用途类型的证书. 改证书只有用于对应的server 的时候,客户度才信任次主机2 . 防止通讯过程中的数据的泄密和被窜改
如下图所示,可以很明显的看出两个的区别:
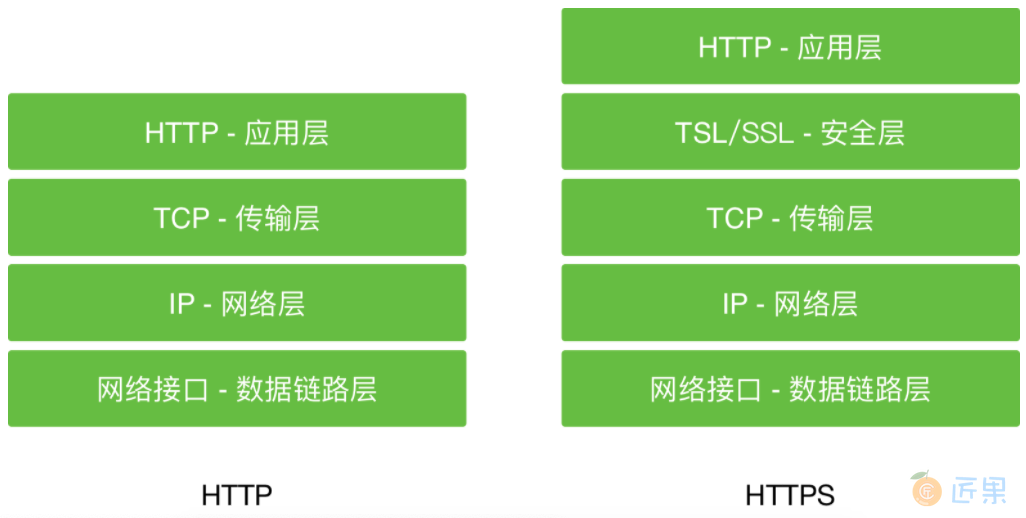
注:TLS是SSL的升级替代版,具体发展历史可以参考传输层安全性协议。
HTTP与HTTPS在写法上的区别也是前缀的不同,客户端处理的方式也不同,具体说来:
如果URL的协议是HTTP,则客户端会打开一条到服务端端口80(默认)的连接,并向其发送老的HTTP请求。 如果URL的协议是HTTPS,则客户端会打开一条到服务端端口443(默认)的连接,然后与服务器握手,以二进制格式与服务器交换一些SSL的安全参数,附上加密的 HTTP请求。 所以你可以看到,HTTPS比HTTP多了一层与SSL的连接,这也就是客户端与服务端SSL握手的过程,整个过程主要完成以下工作:
交换协议版本号 选择一个两端都了解的密码 对两端的身份进行认证 生成临时的会话密钥,以便加密信道。 SSL握手是一个相对比较复杂的过程,更多关于SSL握手的过程细节可以参考TLS/SSL握手过程
SSL/TSL的常见开源实现是OpenSSL,OpenSSL是一个开放源代码的软件库包,应用程序可以使用这个包来进行安全通信,避免窃听,同时确认另一端连接者的身份。这个包广泛被应用在互联网的网页服务器上。 更多源于OpenSSL的技术细节可以参考OpenSSL。
2、Http1.1和Http1.0及2.0的区别?
HTTP1.0和HTTP1.1的一些区别
HTTP1.0最早在网页中使用是在1996年,那个时候只是使用一些较为简单的网页上和网络请求上,而HTTP1.1则在1999年才开始广泛应用于现在的各大浏览器网络请求中,同时HTTP1.1也是当前使用最为广泛的HTTP协议。 主要区别主要体现在:
- 1、缓存处理,在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。
- 2、带宽优化及网络连接的使用,HTTP1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
- 3、错误通知的管理,在HTTP1.1中新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
- 4、Host头处理,在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)。
- 5、长连接,HTTP 1.1支持长连接(PersistentConnection)和请求的流水线(Pipelining)处理,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟,在HTTP1.1中默认开启Connection: keep-alive,一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点。
SPDY
在讲Http1.1和Http2.0的区别之前,还需要说下SPDY,它是HTTP1.x的优化方案:
2012年Google如一声惊雷提出了SPDY的方案,优化了HTTP1.X的请求延迟,解决了HTTP1.X的安全性,具体如下:
- 1、降低延迟,针对HTTP高延迟的问题,SPDY优雅的采取了多路复用(multiplexing)。多路复用通过多个请求stream共享一个tcp连接的方式,解决了HOL blocking的问题,降低了延迟同时提高了带宽的利用率。
- 2、请求优先级(request prioritization)。多路复用带来一个新的问题是,在连接共享的基础之上有可能会导致关键请求被阻塞。SPDY允许给每个request设置优先级,这样重要的请求就会优先得到响应。比如浏览器加载首页,首页的HTML内容应该优先展示,之后才是各种静态资源文件,脚本文件等加载,这样可以保证用户能第一时间看到网页内容。
- 3、header压缩。前面提到HTTP1.x的header很多时候都是重复多余的。选择合适的压缩算法可以减小包的大小和数量。
- 4、基于HTTPS的加密协议传输,大大提高了传输数据的可靠性。
- 5、服务端推送(server push),采用了SPDY的网页,例如我的网页有一个sytle.css的请求,在客户端收到sytle.css数据的同时,服务端会将sytle.js的文件推送给客户端,当客户端再次尝试获取sytle.js时就可以直接从缓存中获取到,不用再发请求了。SPDY构成图:
SPDY位于HTTP之下,TCP和SSL之上,这样可以轻松兼容老版本的HTTP协议(将HTTP1.x的内容封装成一种新的frame格式),同时可以使用已有的SSL功能。
HTTP2.0和HTTP1.X相比的新特性
- 新的二进制格式(Binary Format),HTTP1.x的解析是基于文本。基于文本协议的格式解析存在天然缺陷,文本的表现形式有多样性,要做到健壮性考虑的场景必然很多,二进制则不同,只认0和1的组合。基于这种考虑HTTP2.0的协议解析决定采用二进制格式,实现方便且健壮。
- 多路复用(MultiPlexing),即连接共享,即每一个request都是是用作连接共享机制的。一个request对应一个id,这样一个连接上可以有多个request,每个连接的request可以随机的混杂在一起,接收方可以根据request的 id将request再归属到各自不同的服务端请求里面。
- header压缩,如上文中所言,对前面提到过HTTP1.x的header带有大量信息,而且每次都要重复发送,HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。
- 服务端推送(server push),同SPDY一样,HTTP2.0也具有server push功能。
3、Https 请求慢的解决办法
1、不通过DNS解析,直接访问IP
2、解决连接无法复用
http/1.0协议头里可以设置Connection:Keep-Alive或者Connection:Close,选择是否允许在一定时间内复用连接(时间可由服务器控制)。但是这对App端的请求成效不大,因为App端的请求比较分散且时间跨度相对较大。
方案1.基于tcp的长连接 (主要) 移动端建立一条自己的长链接通道,通道的实现是基于tcp协议。基于tcp的socket编程技术难度相对复杂很多,而且需要自己定制协议。但信息的上报和推送变得更及时,请求量爆发的时间点还能减轻服务器压力(避免频繁创建和销毁连接)
方案2.http long-polling 客户端在初始状态发送一个polling请求到服务器,服务器并不会马上返回业务数据,而是等待有新的业务数据产生的时候再返回,所以链接会一直被保持。一但结束当前连接,马上又会发送一个新的polling请求,如此反复,保证一个连接被保持。 存在问题: 1)增加了服务器的压力 2)网络环境复杂场景下,需要考虑怎么重建健康的连接通道 3)polling的方式稳定性不好 4)polling的response可能被中间代理cache住 ……
方案3.http streaming 和long-polling不同的是,streaming方式通过再server response的头部增加“Transfer Encoding:chuncked”来告诉客户端后续还有新的数据到来 存在问题: 1)有些代理服务器会等待服务器的response结束之后才将结果推送给请求客户端。streaming不会结束response 2)业务数据无法按照请求分割 ……
方案4.web socket 和传统的tcp socket相似,基于tcp协议,提供双向的数据通道。它的优势是提供了message的概念,比基于字节流的tcp socket使用更简单。技术较新,不是所有浏览器都提供了支持。
3、解决head of line blocking
它的原因是队列的第一个数据包(队头)受阻而导致整列数据包受阻
使用**http pipelining** ,确保几乎在同一时间把request发向了服务器
4、Http的request和response的协议组成
1、Request组成
客户端发送一个HTTP请求到服务器的请求消息包括以下格式:
请求行(request line)、请求头部(header)、空行和请求数据四个部分组成。
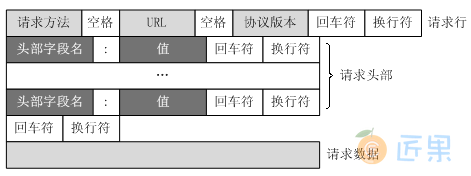
请求行以一个方法符号开头,以空格分开,后面跟着请求的URI和协议的版本。
Get请求例子
GET /562f25980001b1b106000338.jpg HTTP/1.1
Host img.mukewang.com
User-Agent Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36
Accept image/webp,image/*,*/*;q=0.8
Referer http://www.imooc.com/
Accept-Encoding gzip, deflate, sdch
Accept-Language zh-CN,zh;q=0.8
第一部分:请求行,用来说明请求类型,要访问的资源以及所使用的HTTP版本. GET说明请求类型为GET,[/562f25980001b1b106000338.jpg]为要访问的资源,该行的最后一部分说明使用的是HTTP1.1版本。 第二部分:请求头部,紧接着请求行(即第一行)之后的部分,用来说明服务器要使用的附加信息 从第二行起为请求头部,HOST将指出请求的目的地.User-Agent,服务器端和客户端脚本都能访问它,它是浏览器类型检测逻辑的重要基础.该信息由你的浏览器来定义,并且在每个请求中自动发送等等 第三部分:空行,请求头部后面的空行是必须的 即使第四部分的请求数据为空,也必须有空行。 第四部分:请求数据也叫主体,可以添加任意的其他数据。 这个例子的请求数据为空。
POST请求例子
POST / HTTP1.1
Host:www.wrox.com
User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022)
Content-Type:application/x-www-form-urlencoded
Content-Length:40
Connection: Keep-Alive
name=Professional%20Ajax&publisher=Wiley
- 第一部分:请求行,第一行明了是post请求,以及http1.1版本。
- 第二部分:请求头部,第二行至第六行。
- 第三部分:空行,第七行的空行。
- 第四部分:请求数据,第八行。
2、Response组成
一般情况下,服务器接收并处理客户端发过来的请求后会返回一个HTTP的响应消息。
HTTP响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文。

- 第一部分:状态行,由HTTP协议版本号, 状态码, 状态消息 三部分组成。
- 第一行为状态行,(HTTP/1.1)表明HTTP版本为1.1版本,状态码为200,状态消息为(ok)
- 第二部分:消息报头,用来说明客户端要使用的一些附加信息
- 第二行和第三行为消息报头, Date:生成响应的日期和时间;Content-Type:指定了MIME类型的HTML(text/html),编码类型是UTF-8
- 第三部分:空行,消息报头后面的空行是必须的
- 第四部分:响应正文,服务器返回给客户端的文本信息。
空行后面的HTML部分为响应正文。
5、谈谈对http缓存的了解。
HTTP的缓存机制也是依赖于请求和响应header里的参数类实现的,最终响应式从缓存中去,还是从服务端重新拉取,HTTP的缓存机制的流程如下所示:
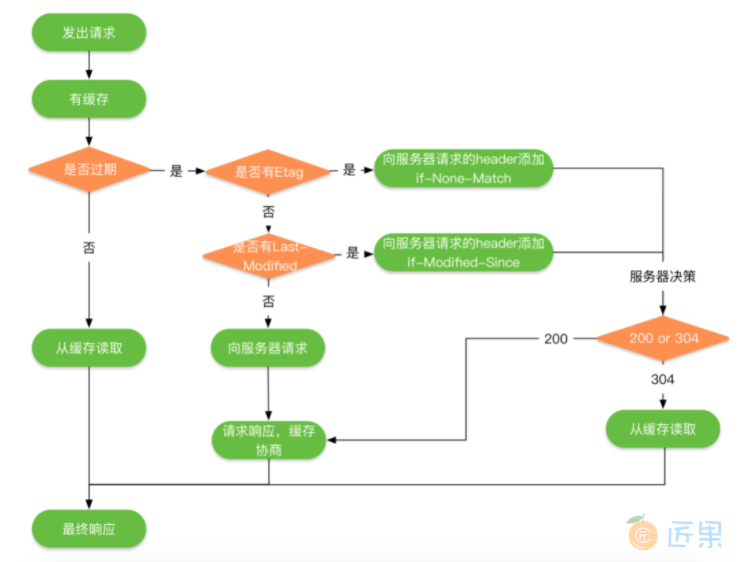
HTTP的缓存可以分为两种:
强制缓存:需要服务端参与判断是否继续使用缓存,当客户端第一次请求数据是,服务端返回了缓存的过期时间(Expires与Cache-Control),没有过期就可以继续使用缓存,否则则不适用,无需再向服务端询问。 对比缓存:需要服务端参与判断是否继续使用缓存,当客户端第一次请求数据时,服务端会将缓存标识(Last-Modified/If-Modified-Since与Etag/If-None-Match)与数据一起返回给客户端,客户端将两者都备份到缓存中 ,再次请求数据时,客户端将上次备份的缓存 标识发送给服务端,服务端根据缓存标识进行判断,如果返回304,则表示通知客户端可以继续使用缓存。 强制缓存优先于对比缓存。
上面提到强制缓存使用的的两个标识:
Expires:Expires的值为服务端返回的到期时间,即下一次请求时,请求时间小于服务端返回的到期时间,直接使用缓存数据。到期时间是服务端生成的,客户端和服务端的时间可能有误差。 Cache-Control:Expires有个时间校验的问题,所有HTTP1.1采用Cache-Control替代Expires。 Cache-Control的取值有以下几种:
private: 客户端可以缓存。 public: 客户端和代理服务器都可缓存。 max-age=xxx: 缓存的内容将在 xxx 秒后失效 no-cache: 需要使用对比缓存来验证缓存数据。 no-store: 所有内容都不会缓存,强制缓存,对比缓存都不会触发。 我们再来看看对比缓存的两个标识:
Last-Modified/If-Modified-Since
Last-Modified 表示资源上次修改的时间。
当客户端发送第一次请求时,服务端返回资源上次修改的时间:
Last-Modified: Tue, 12 Jan 2016 09:31:27 GMT
客户端再次发送,会在header里携带If-Modified-Since。将上次服务端返回的资源时间上传给服务端。
If-Modified-Since: Tue, 12 Jan 2016 09:31:27 GMT
服务端接收到客户端发来的资源修改时间,与自己当前的资源修改时间进行对比,如果自己的资源修改时间大于客户端发来的资源修改时间,则说明资源做过修改, 则返回200表示需要重新请求资源,否则返回304表示资源没有被修改,可以继续使用缓存。
上面是一种时间戳标记资源是否修改的方法,还有一种资源标识码ETag的方式来标记是否修改,如果标识码发生改变,则说明资源已经被修改,ETag优先级高于Last-Modified。
Etag/If-None-Match
ETag是资源文件的一种标识码,当客户端发送第一次请求时,服务端会返回当前资源的标识码:
ETag: "5694c7ef-24dc"
客户端再次发送,会在header里携带上次服务端返回的资源标识码:
If-None-Match:"5694c7ef-24dc" 服务端接收到客户端发来的资源标识码,则会与自己当前的资源吗进行比较,如果不同,则说明资源已经被修改,则返回200,如果相同则说明资源没有被修改,返回 304,客户端可以继续使用缓存。
6、Http长连接。
Http1.0是短连接,HTTP1.1默认是长连接,也就是默认Connection的值就是keep-alive。但是长连接实质是指的TCP连接,而不是HTTP连接。TCP连接是一个双向的通道,它是可以保持一段时间不关闭的,因此TCP连接才有真正的长连接和短连接这一说。
Http1.1为什么要用使用tcp长连接?
长连接是指的TCP连接,也就是说复用的是TCP连接。即长连接情况下,多个HTTP请求可以复用同一个TCP连接,这就节省了很多TCP连接建立和断开的消耗。
此外,长连接并不是永久连接的。如果一段时间内(具体的时间长短,是可以在header当中进行设置的,也就是所谓的超时时间),这个连接没有HTTP请求发出的话,那么这个长连接就会被断掉。
7、Https加密原理。
加密算法的类型基本上分为了两种:
- 对称加密,加密用的密钥和解密用的密钥是同一个,比较有代表性的就是 AES 加密算法;
- 非对称加密,加密用的密钥称为公钥,解密用的密钥称为私钥,经常使用到的 RSA 加密算法就是非对称加密的;
此外,还有Hash加密算法
HASH算法:MD5, SHA1, SHA256
相比较对称加密而言,非对称加密安全性更高,但是加解密耗费的时间更长,速度慢。
HTTPS = HTTP + SSL,HTTPS 的加密就是在 SSL 中完成的。
这就要从 CA 证书讲起了。CA 证书其实就是数字证书,是由 CA 机构颁发的。至于 CA 机构的权威性,那么是毋庸置疑的,所有人都是信任它的。CA 证书内一般会包含以下内容:
- 证书的颁发机构、版本
- 证书的使用者
- 证书的公钥
- 证书的有效时间
- 证书的数字签名 Hash 值和签名 Hash 算法
- ...
客户端如何校验 CA 证书?
CA 证书中的 Hash 值,其实是用证书的私钥进行加密后的值(证书的私钥不在 CA 证书中)。然后客户端得到证书后,利用证书中的公钥去解密该 Hash 值,得到 Hash-a ;然后再利用证书内的签名 Hash 算法去生成一个 Hash-b 。最后比较 Hash-a 和 Hash-b 这两个的值。如果相等,那么证明了该证书是对的,服务端是可以被信任的;如果不相等,那么就说明该证书是错误的,可能被篡改了,浏览器会给出相关提示,无法建立起 HTTPS 连接。除此之外,还会校验 CA 证书的有效时间和域名匹配等。
HTTPS 中的 SSL 握手建立过程
假设现在有客户端 A 和服务器 B :
- 首先,客户端 A 访问服务器 B ,比如我们用浏览器打开一个网页 www.baidu.com ,这时,浏览器就是客户端 A ,百度的服务器就是服务器 B 了。这时候客户端 A 会生成一个随机数1,把随机数1 、自己支持的 SSL 版本号以及加密算法等这些信息告诉服务器 B 。
- 服务器 B 知道这些信息后,然后确认一下双方的加密算法,然后服务端也生成一个随机数 B ,并将随机数 B 和 CA 颁发给自己的证书一同返回给客户端 A 。
- 客户端 A 得到 CA 证书后,会去校验该 CA 证书的有效性,校验方法在上面已经说过了。校验通过后,客户端生成一个随机数3 ,然后用证书中的公钥加密随机数3 并传输给服务端 B 。
- 服务端 B 得到加密后的随机数3,然后利用私钥进行解密,得到真正的随机数3。
- 最后,客户端 A 和服务端 B 都有随机数1、随机数2、随机数3,然后双方利用这三个随机数生成一个对话密钥。之后传输内容就是利用对话密钥来进行加解密了。这时就是利用了对称加密,一般用的都是 AES 算法。
- 客户端 A 通知服务端 B ,指明后面的通讯用对话密钥来完成,同时通知服务器 B 客户端 A 的握手过程结束。
- 服务端 B 通知客户端 A,指明后面的通讯用对话密钥来完成,同时通知客户端 A 服务器 B 的握手过程结束。
- SSL 的握手部分结束,SSL 安全通道的数据通讯开始,客户端 A 和服务器 B 开始使用相同的对话密钥进行数据通讯。
简化如下:
- 客户端和服务端建立 SSL 握手,客户端通过 CA 证书来确认服务端的身份;
- 互相传递三个随机数,之后通过这随机数来生成一个密钥;
- 互相确认密钥,然后握手结束;
- 数据通讯开始,都使用同一个对话密钥来加解密;
可以发现,在 HTTPS 加密原理的过程中把对称加密和非对称加密都利用了起来。即利用了非对称加密安全性高的特点,又利用了对称加密速度快,效率高的好处。
8、HTTPS 如何防范中间人攻击?
什么是中间人攻击?
当数据传输发生在一个设备(PC/手机)和网络服务器之间时,攻击者使用其技能和工具将自己置于两个端点之间并截获数据;尽管交谈的两方认为他们是在与对方交谈,但是实际上他们是在与干坏事的人交流,这便是中间人攻击。
有几种攻击方式?
- 1、嗅探: 嗅探或数据包嗅探是一种用于捕获流进和流出系统/网络的数据包的技术。网络中的数据包嗅探就好像电话中的监听。
- 2、数据包注入: 在这种技术中,攻击者会将恶意数据包注入常规数据中。这样用户便不会注意到文件/恶意软件,因为它们是合法通讯流的一部分。
- 3、会话劫持: 在你登录进你的银行账户和退出登录这一段期间便称为一个会话。这些会话通常都是黑客的攻击目标,因为它们包含潜在的重要信息。在大多数案例中,黑客会潜伏在会话中,并最终控制它。
- 4、SSL剥离: 在SSL剥离攻击中,攻击者使SSL/TLS连接剥落,随之协议便从安全的HTTPS变成了不安全的HTTP。
HTTPS 如何防范中间人攻击:
请见https加密原理。
9、有哪些响应码,分别都代表什么意思?
- 信息,服务器收到请求,需要请求者继续执行操作
- 成功,操作被成功接收并处理
- 重定向,需要进一步的操作以完成请求
- 客户端错误,请求包含语法错误或无法完成请求
- 服务器错误,服务器在处理请求的过程中发生了错误