- 提到了组件生命周期、服务注册的实现
- 提到了公共层定义组件服务、base层定义通用资源
- 提到了 implementation 与 runtimeOnly 的代码 / 资源隔离效果;
- 提到了 JIMU 插件的调试切换、智能配置功能;
- 提到了 2 种调用组件声明周期的方法: javassist 和反射;
- 提到了有序初始化组件的解决方案:StartUp、DAU
4.1 Android彻底组件化demo发布
得到Android组件化方案已经开源,参见Android组件化方案开源。方案的解读文章是一个小的系列,这是系列的第二篇文章: 1、Android彻底组件化方案实践 2、Android彻底组件化demo发布 3、Android彻底组件化-代码和资源隔离 4、Android彻底组件化—UI跳转升级改造 5、Android彻底组件化—如何使用Arouter
今年6月份开始,我开始负责对“得到app”的Android代码进行组件化拆分,在动手之前我查阅了很多组件化或者模块化的文章,虽然有一些收获,但是很少有文章能够给出一个整体且有效的方案,大部分文章都只停留在组件单独调试的层面上,涉及组件之间的交互就很少了,更不用说组件生命周期、集成调试和代码边界这些最棘手的问题了。有感于此,我觉得很有必要设计一套完整的组件化方案,经过几周的思考,反复的推倒重建,终于形成了一个完整的思路,整理在我的第一篇文章中Android彻底组件化方案实践。这两个月以来,得到的Android团队按照这个方案开始了组件化的拆分,经过两个开发周期的努力,目前已经拆分五个大的业务组件以及数个底层lib库,并对之前的方案进行了一些完善。从使用效果上来看,这套方案完全可以达到了我们之前对组件化的预期,并且架构简单,学习成本低,对于一个急需快速组件化拆分的项目是很适合的。现在将这套方案开源出来,欢迎大家共同完善。代码地址:https://github.com/mqzhangw/JIMU
4.1.1 JIMU使用指南
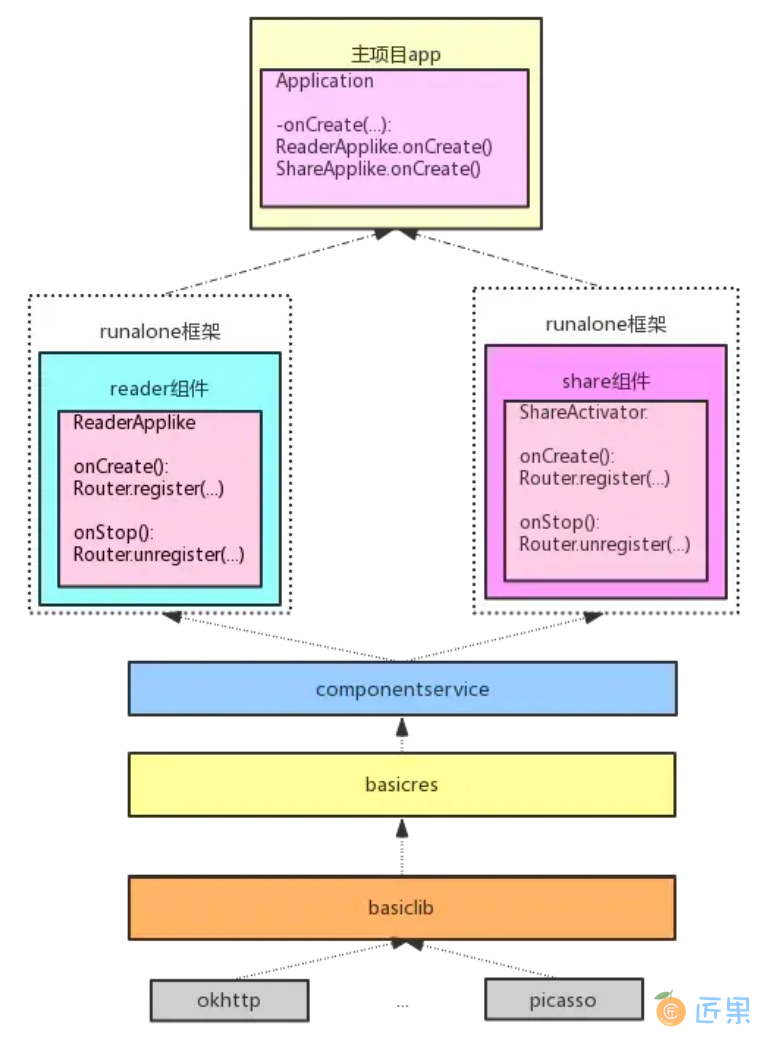
首先我们看一下demo的代码结构,然后根据这个结构图再次从单独调试(发布)、组件交互、UI跳转、集成调试、代码边界和生命周期等六个方面深入分析,之所以说“再次”,是因为上一篇文章我们已经讲了这六个方面的原理,这篇文章更侧重其具体实现。

代码中的各个module基本和图中对应,从上到下依次是:
- app是主项目,负责集成众多组件,控制组件的生命周期
- reader和share是我们拆分的两个组件
- componentservice中定义了所有的组件提供的服务
- basicres定义了全局通用的theme和color等公共资源
- basiclib中是公共的基础库,一些第三方的库(okhttp等)也统一交给basiclib来引入
图中没有体现的module有两个,一个是componentlib,这个是我们组件化的基础库,像Router/UIRouter等都定义在这里;另一个是build-gradle,这个是我们组件化编译的gradle插件,也是整个组件化方案的核心。
我们在demo中要实现的场景是:主项目app集成reader和share两个组件,其中reader提供一个读书的fragment给app调用(组件交互),share提供一个activity来给reader来调用(UI跳转)。主项目app可以动态的添加和卸载 share组件(生命周期)。而集成调试和代码边界是通过build-gradle插件来实现的。
1 单独调试和发布
单独调试的配置与上篇文章基本一致,通过在组件工程下的gradle.properties文件中设置一个isRunAlone的变量来区分不同的场景,唯一的不同点是在组件的build.gradle中不需要写下面的样板代码:
if(isRunAlone.toBoolean()){
apply plugin: 'com.android.application'
}else{
apply plugin: 'com.android.library'
}
而只需要引入一个插件com.dd.comgradle(源码就在build-gradle),在这个插件中会自动判断apply com.android.library还是com.android.application。实际上这个插件还能做更“智能”的事情,这个在集成调试章节中会详细阐述。
单独调试所必须的AndroidManifest.xml、application、入口activity等类定义在src/main/runalone下面,这个比较简单就不赘述了。
如果组件开发并测试完成,需要发布一个release版本的aar文件到中央仓库,只需要把isRunAlone修改为false,然后运行module:assembleRelease命令就可以了。这里简单起见没有进行版本管理,大家如果需要自己加上就好了。
值得注意的是,发布组件是唯一需要修改isRunAlone=false的情况,即使后面将组件集成到app中,也不需要修改 isRunAlone的值,既保持isRunAlone=true即可。所以实际上在Androidstudio中,是可以看到三个application工程的,随便点击一个都是可以独立运行的,并且可以根据配置引入其他需要依赖的组件。这背后的工作都由 com.dd.comgradle插件来默默完成。
2 组件交互
在这里组件的交互专指组件之间的数据传输,在我们的方案中使用的是接口+实现的方式,组件之间完全面向接口编程。在demo中我们让reader提供一个fragment给app使用来说明。首先reader组件在componentservice中定义自己的服务
public interface ReadBookService {
Fragment getReadBookFragment();
}
然后在自己的组件工程中,提供具体的实现类ReadBookServiceImpl:
public class ReadBookServiceImpl implements ReadBookService {
@Override
public Fragment getReadBookFragment() {
return new ReaderFragment();
}
}
提供了具体的实现类之后,需要在组件加载的时候把实现类注册到Router中,具体的代码在ReaderAppLike中,ReaderAppLike相当于组件的application类,这里定义了onCreate和onStop两个生命周期方法,对应组件的加载和卸载。
public class ReaderAppLike implements IApplicationLike {
Router router = Router.getInstance();
@Override
public void onCreate() {
router.addService(ReadBookService.class.getSimpleName(), new ReadBookServiceImpl());
}
@Override
public void onStop() {
router.removeService(ReadBookService.class.getSimpleName());
}
}
在app中如何使用如reader组件提供的ReaderFragment呢?注意此处app是看不到组件的任何实现类的,它只能看``到componentservice中定义的ReadBookService,所以只能面向ReadBookService来编程。具体的实例代码如下:
Router router = Router.getInstance();
if (router.getService(ReadBookService.class.getSimpleName()) != null) {
ReadBookService service = (ReadBookService)
router.getService(ReadBookService.class.getSimpleName());
fragment = service.getReadBookFragment();
ft = getSupportFragmentManager().beginTransaction();
ft.add(R.id.tab_content, fragment).commitAllowingStateLoss();
}
这里需要注意的是由于组件是可以动态加载和卸载的,因此在使用ReadBookService的需要进行判空处理。我们看到数据的传输是通过一个中央路由Router来实现的,这个Router的实现其实很简单,其本质就是一个HashMap,具体代码大家参见源码。
通过上面几个步骤就可以轻松实现组件之间的交互,由于是面向接口,所以组件之间是完全解耦的。至于如何让组件之间在编译阶段不不可见,是通过上文所说的com.dd.comgradle实现的,这个在第一篇文章中已经讲到,后面会贴出具体的代码。
3 UI跳转
页面(activity)的跳转也是通过一个中央路由UIRouter来实现,不同的是这里增加了一个优先级的概念。具体的实现就不在这里赘述了,代码还是很清晰的。具体的功能介绍和使用规范,请大家参见文章: Android彻底组件化—UI跳转升级改造
4 集成调试
集成调试可以认为由app或者其他组件充当host的角色,引入其他相关的组件一起参与编译,从而测试整个交互流程。在demo中app和reader都可以充当host的角色。在这里我们以app为例。
首先我们需要在根项目的gradle.properties中增加一个变量mainmodulename,其值就是工程中的主项目,这里是app。设置为mainmodulename的module,其isRunAlone永远是true。然后在app项目的gradle.properties文件中增加两个变量:
debugComponent=readercomponent,com.mrzhang.share:sharecomponent
compileComponent=readercomponent,sharecomponent
其中debugComponent是运行debug的时候引入的组件,compileComponent是release模式下引入的组件。我们可以看到debugComponent引入的两个组件写法是不同的,这是因为组件引入支持两种语法,module或者 modulePackage:module,前者直接引用module工程,后者使用componentrelease中已经发布的aar。
注意在集成调试中,要引入的reader和share组件是不需要把自己的isRunAlone修改为false的。我们知道一个application工程是不能直接引用(compile)另一个application工程的,所以如果app和组件都是isRunAlone=true 的话在正常情况下是编译不过的。秘密就在于com.dd.comgradle会自动识别当前要调试的具体是哪个组件,然后把其他组件默默的修改为library工程,这个修改只在当次编译生效。
如何判断当前要运行的是app还是哪个组件呢?这个是通过task来判断的,判断的规则如下:
- assembleRelease → app
- app:assembleRelease或者 :app:assembleRelease → app
- sharecomponent:assembleRelease 或者:sharecomponent:assembleRelease→ sharecomponent
上面的内容要实现的目的就是每个组件可以直接在Androidstudio中run,也可以使用命令进行打包,这期间不需要修改任何配置,却可以自动引入依赖的组件。这在开发中可以极大加快工作效率。
5 代码边界
至于依赖的组件是如何集成到host中的,其本质还是直接使用compile project(...)或者compile modulePackage:module@aar。那么为啥不直接在build.gradle中直接引入呢,而要经过com.dd.comgradle这个插件来进行诸多复杂的操作?原因在第一篇文章中也讲到了,那就是组件之间的完全隔离,也可以称之为代码边界。如果我们直接compile组件,那么组件的所有实现类就完全暴露出来了,使用方就可以直接引入实现类来编程,从而绕过了面向接口编程的约束。这样就完全失去了解耦的效果了,可谓前功尽弃。
那么如何解决这个问题呢?我们的解决方式还是从分析task入手,只有在assemble任务的时候才进行compile引入。这样在代码的开发期间,组件是完全不可见的,因此就杜绝了犯错误的机会。具体的代码如下:
/**
* 自动添加依赖,只在运行assemble任务的才会添加依赖,因此在开发期间组件之间是完全感知不到的,这是做到完全隔离
* 的关键
* 支持两种语法:module或者modulePackage:module,前者之间引用module工程,后者使用componentrelease中已
* 经发布的aar
*
* @param assembleTask
* @param project
*/
private void compileComponents(AssembleTask assembleTask, Project project) {
String components;
if (assembleTask.isDebug) {
components = (String) project.properties.get("debugComponent")
} else {
components = (String) project.properties.get("compileComponent")
}
if (components == null || components.length() == 0) {
return;
}
String[] compileComponents = components.split(",")
if (compileComponents == null || compileComponents.length == 0) {
return;
}
for (String str : compileComponents) {
if (str.contains(":")) {
File file = project.file("../componentrelease/" + str.split(":")[1] + "-
release.aar")
if (file.exists()) {
project.dependencies.add("compile", str + "-release@aar")
} else {
throw new RuntimeException(str + " not found ! maybe you should generate a
new one ")
}
} else {
project.dependencies.add("compile", project.project(':' + str))
}
}
}
6 生命周期
在上一篇文章中我们就讲过,组件化和插件化的唯一区别是组件化不能动态的添加和修改组件,但是对于已经参与编译的组件是可以动态的加载和卸载的,甚至是降维的。
首先我们看组件的加载,使用章节5中的集成调试,可以在打包的时候把依赖的组件参与编译,此时你反编译apk的代码会看到各个组件的代码和资源都已经包含在包里面。但是由于每个组件的唯一入口ApplicationLike还没有执行 oncreate()方法,所以组件并没有把自己的服务注册到中央路由,因此组件实际上是不可达的。
在什么时机加载组件以及如何加载组件?目前com.dd.comgradle提供了两种方式,字节码插入和反射调用。字节码插入模式是在dex生成之前,扫描所有的ApplicationLike类(其有一个共同的父类),然后通过javassist 在主项目的Application.onCreate()中插入调用ApplicationLike.onCreate()的代码。这样就相当于每个组件在application启动的时候就加载起来了。
反射调用的方式是手动在Application.onCreate()中或者在其他合适的时机手动通过反射的方式来调用ApplicationLike.onCreate()。之所以提供这种方式原因有两个:对代码进行扫描和插入会增加编译的时间,特别在debug的时候会影响效率,并且这种模式对Instant Run支持不好;另一个原因是可以更灵活的控制加载或者卸载时机。
这两种模式的配置是通过配置com.dd.comgradle的Extension来实现的,下面是字节码插入的模式下的配置格式,添加applicationName的目的是加快定位Application的速度。
combuild {
applicationName = 'com.mrzhang.component.application.AppApplication'
isRegisterCompoAuto = true
}
demo中也给出了通过反射来加载和卸载组件的实例,在APP的首页有两个按钮,一个是加载分享组件,另一个是卸载分享组件,在运行时可以任意的点击按钮从而加载或卸载组件,具体效果大家可以运行demo查看。
4.1.2 组件化拆分的感悟
在最近两个月的组件化拆分中,终于体会到了做到剥丝抽茧是多么艰难的事情。确定一个方案固然重要,更重要的是克服重重困难坚定的实施下去。在拆分中,组件化方案也不断的微调,到现在终于可以欣慰的说,这个方案是经历过考验的,第一它学习成本比较低,组内同事可以快速的入手,第二它效果明显,得到本来run一次需要8到10分钟时间(不过后面换了顶配mac,速度提升了很多),现在单个组件可以做到1分钟左右。最主要的是代码结构清晰了很多,这位后期的并行开发和插件化奠定了坚实的基础。
总之,如果你面前也是一个庞大的工程,建议你使用该方案,以最小的代价尽快开始实施组件化。如果你现在负责的是一个开发初期的项目,代码量还不大,那么也建议尽快进行组件化的规划,不要给未来的自己增加徒劳的工作量。
4.2 Android彻底组件化—代码和资源隔离
得到Android组件化方案已经开源,参见Android组件化方案开源。方案的解读文章是一个小的系列,这是系列的第三篇文章: 1、Android彻底组件化方案实践 2、Android彻底组件化demo发布 3、Android彻底组件化-代码和资源隔离 4、Android彻底组件化—UI跳转升级改造 5、Android彻底组件化—如何使用Arouter最近Google正式推出AS3.0版本,同时gradle插件也升级为3.0.0,目前各大开源库都在做gradle3.0.0的兼容,我也把得到开源的组件化方案JIMU进行了升级,结论是:JIMU在gradle3.0上是没有兼容问题的,可以直接使用。关于如何迁移到gradle3.0.0,请参见官方迁移指南。
虽然没有兼容问题,但在升级的过程中也收获了意外之喜,那就是发现gradle3.0.0对代码隔离的支持越来越好。为什么对“代码隔离”这么关注呢?大家可以回顾前两篇文章Android彻底组件化方案实践和Android彻底组件化demo发布,在这两篇文章中提到的JIMU组件化方案,被我冠以“彻底”二字,虽然有些说大话,但主要是为了强调JIMU与之前其他组件化方案的不同之处就在于,JIMU实现了组件之间的绝对隔离,不同组件之间在代码开发阶段是完全不可见的,是一种彻底解耦的思想。为了实现这种隔离,我人为在编译和运行期做了一次判断和区分,既在编译期间(开发期间)组件之间没有任何依赖关系,但在打包和运行时,再偷偷添加依赖。具体可以参见前两篇文章和GitHub源码。
不得不说,当时这种实现是迫不得已,我本来想直接使用gradle提供的功能来做这种隔离,其实gradle也的确提供一个类似的功能,那就是apk依赖语法,其作用就是保证依赖库只在运行期间对外可见,但在编译期间是不可见的。按说这已经满足我的要求了,但是遇到了一个坑:在gradle2.+版本,apk依赖只能是jar,不能是aar,但是我们的组件因为含有各种资源,输出产物就是aar!所以最终选择了放弃apk这种语法。
而在最新的gradle3.0.0上,apk被替换为runtimeOnly语法,其作用还是一样的,但是我发现runtimeOnly可以添加aar依赖!这的确让我很兴奋,这不就是我梦寐以求的功能吗?有了这个尚方宝剑,组件化的方案就可以做的更薄了啊。于是我对在得到app上进行了实验,结论是:runtimeOnly的确可以解决一些问题,但是还不够。下面我从代码隔离、资源隔离和调试切换(单独和集成)三个方便仔细阐述,也顺便再讲一下JIMU所能实现的功能。
4.2.1 代码隔离
在讲代码隔离之前,先大致看一下gradle3.0.0对添加依赖的语法变化。
首先compile被废弃了,而是分成了两个:implementation和API,其中API与之前的compile功能基本一致,不再赘述;implementation就比较高级了,其作用就是,使用implementation添加的依赖不会再编译期间被其他组件引用到,但在运行期间是完全可见的。这也是一种代码隔离。举个例子:
组件A依赖lib1,既A implementation lib1
组件B依赖组件A,既B api A
在gradle3.0.0之前,B是完全可以引用到lib1里面的类的,但是现在B在编译期间就做不到了,只能在运行期可以。这种思想有点类似于“下属的下属不是你的下属”的思想。但是这种隔离在组件之间是不起作用的,在上面的例子中A的所有类对B还是完全可见的,也就是没有做任何隔离的。不过implementation的确是一种有效减少编译时间的方式,还是上面的例子,lib1发生了变化,现在只需要编译A就可以了,而在之前B有可能也使用到了lib1,所以需要同时编译B和A。按照官方建议,大部分情况下都应该使用implementation来进行添加依赖。
此外还有两种变化,原来的apk语法被runtimeOnly取代,provided被compileOnly取代,其作用还是没变。上文也讲了,runtimeOnly有个极大的改动就是可以支持aar了,但是compileOnly还是只能支持jar!
先做一个小结,目前gradle3.0.0的四种语法的功能和代码隔离效果见下图:

四种语法的功能和代码隔离效果从上图可以看出,在代码隔离效果上,runtimeOnly的效果是最好的!但是就可以直接使用了吗,答案是否定的。
4.2.2 资源隔离
在前面的文章中,一直在强调代码隔离,其实组件之间的完全隔离还有一层就是资源隔离,否则还是容易造成组件之间的耦合。这个在文章的“单独调试”章节中提到了一句,就是每个组件都需要指定一个资源前缀resourcePrefix,以避免集成后资源名冲突的问题。也就是说,一个彻底的组件化不仅要做到代码不能直接引用,资源也是不能引用的!
但是runtimeOnly目前还做到资源隔离,我在JIMU的开源库上做了试验,app通过runtimeOnly引用sharecomponent组件,虽然sharecomponent的代码是不可见了,但是资源还是可以被app直接使用的并能成功运行。
从这一点上看,直接替换成runtimeOnly是不行的,为了达到这种效果,目前还是需要像JIMU一样,人为的加一层控制,所以从组件化方案的角度上看并没有变的更薄,不过幸好JIMU已经很简单了,有一定的gradle基础的人可以比较容易的理解。
4.2.3 调试切换
除了上面说的资源隔离导致不能直接用runtimeOnly之外,还有一个使用上的问题需要解决,这也是JIMU中compbuild插件提供的一个功能:自动切换单独调试和集成调试。在单独调试时,组件是一个application工程,其输出产物是apk文件,而在集成调试时,被依赖的组件是一个library工程,其输出产物是aar文件。对于runtimeOnly来说,对aar和jar是支持的,但是不能支持apk,所以如果想在单独调试和集成调试之间切换的话,需要人工修改 runalone配置并修改build.gradle配置文件,然后还需要sync之后才能生效,这种修改是相当繁琐的。
在JIMU中,这个问题的解决是通过“智能”识别当前要调试的组件来解决的,对于要调试的组件将其设置为application工程,而将其依赖的其他组件默默修改为library工程,这种修改是即时生效的,对开发者是完全透明的。开发者直接点击AS的run功能区就可以随意的调试任意组件。AS的run功能区的图如下:
4.2.4 总结
综上所述,我们对JIMU和gradle3.0.0做几点总结: (1)升级到gradle3.0.0之后,可以继续使用JIMU,不需要专门做兼容 (2)gradle3.0.0提供了implementation和runtimeOnly两种语法,它们都能实现一定程度的代码隔离效果,建议大家在今后优先使用 (3)implementation和runtimeOnly目前在资源隔离和调试切换上还不能满足组件化的要求,所以还是需要使用JIMU提供的完全隔离和随意切换功能。
在JIMU的源码中我增加了gradle3.0.0分支,依赖语法做了相应的替换源码地址:DDComponent
4.3 组件化:代码隔离也难不倒组件的按序初始化
4.3.1 前言
时至今日,Android项目中的组件化大家都已经非常熟悉了,但在各个细节方面还是有一些门门道道的内容,如果没有趁手的中间件支持,推行组件化的过程中还是会遇到阻碍。继2017年逻辑思维得到项目团队开源其组件化方案思路和核心gradle构建插件后,笔者一直投身其中并致力于插件的功能升级和中间件生态完善。
其实在2018年就有部分同学提出了“增加按序初始化组件”的需求,限于个人精力以及需求的优先级,当时被搁置了,这个需求一拖也就拖了两年了。这次终于抽出时间完成了这个中间件,特此写了一篇博客,介绍其中的一些知识点和这个中间件Maat。
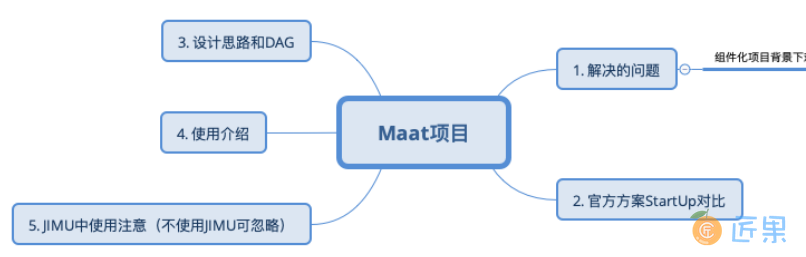
方便阅读,导图附上。
注:即使你没有使用上面提到的得到组件化方案(DDComponentForAndroid)或者我们后续维护的JIMU,也不影响本篇文章的理解。
4.3.2 问题的根源
这里我们再花一点时间来了解下问题的根源:组件化的基础是模块化,在做到模块化的同时,模块与模块在编写、编译期间也就达成了完全代码隔离,组件间的交互依靠 底层接口+服务发现(或者服务注册) 或者更加抽象为 “基于协议、隐藏实现”。这带来了编写、编译期间激增的代码耦合(注:此处语境遗漏,在达成编写、编译期间完全代码隔离的条件下,想要用比较原始的、直面问题的方式解决组件按序初始化问题,例如使用反射+无分支遗漏的逻辑涵盖所有组件组合情况,会导致耦合激增。2020年10月20日补)。
我知道这样说实在是太晦涩了,一点也不接地气,我们以一个简单的例子来配合说明。
interface IComponent {
fun onCreate()
fun onDestroy()
}
我们定义这样的接口来代表一个组件模型。案例设定为:一个宿主H+两个互无关联的组件A、B 那么有:
class A : IComponent {
override fun onCreate() {
// A初始化逻辑
}
override fun onDestroy() {
}
}
class B : IComponent {
override fun onCreate() {
// B初始化逻辑
}
override fun onDestroy() {
}
}
另有
class H :Application {
override fun onCreate() {
A().onCreate()
B().onCreate()
}
}
我们以最简单的代码演示组件的加载和初始化环节。这里隐藏了一个问题:如果是手工编码,那么是存在代码边界的,编写、编译期间H无法直接访问A和B,我们只能通过反射去实现(否则编译不通过)。当然,也可以通过字节码技术实现如果我们要让B先于A初始化,那么就调整其顺序,这对于手工编码方式而言,可能就是将编码变为:
XXX.loadComponent("Bpackage.B") //"Bpackage.B"为B的类路径
XXX.loadComponent("Apackage.A")
而利用字节码技术的,则需要增加排序功能或者读取全量配置功能。
- 案例2: 此时A组件依赖于B,必须等B组件初始化成功并得到结果后才能初始化。
- 思路1:先加载和初始化B,利用代码同步的特性,再初始化A
- 思路2:先加载和初始化B,修改组件模型,增加callback作为入参,异步初始化A
思路1存在很大的限制,比如其初始化需要参与网络通信或者数据库操作;思路2对于手工编码来说,会产生回调地狱,而对于字节码技术实现而言,就是一个噩梦而且,JIMU已经投入使用挺长一段时间了,如果不是毫无选择,对于基类或者接口做无法版本兼容的操作都不应该被采纳
思路2的改进版:增加上下文,使得回调嵌套扁平化。既然我们决定增加一个上下文,那么将初始化的管理工作进行封装就成了顺理成章的事情
4.3.3 为什么不使用官方StartUp而选择造轮子
在思考这个问题时,我们必须要清楚Startup的设计意图
Startup 中文介绍 可在应用启动时简单、高效地初始化组件。
借助 App Startup 库,可在应用启动时简单、高效地初始化组件。库开发者和应用开发者都可以使用 App Startup 来简化启动序列并显式设置初始化顺序。
我们知道,在Startup发布之前,各大SDK采用的初始化方式一般为两种:
- 显式API调用,需要Application实例
- 内部提供一个ContentProvider,并在其中获取Application实例。因为其特性,会在应用启动时被自动加载,而不再需要使用者显式的API调用
一般为了方便开发者,在manifest文件中写入SDK参数配置并利用Context(为了不造成泄漏,使用Application是最好的选择)读取配置的做法更受推荐。所以第二种方式的使用越来越多。
这就带来了一个问题:引入越多的SDK就会引入更多的ContentProvider,他们并不会随着初始化工作完成而消亡,而且加重了应用启动时AMS的负担。
业内存在一个著名的编程范式:约定优于配置,既然使用ContentProvider作为初始化入口已经被广泛接受,那么Google作为生态维护者提供一个官方库,使用统一的初始化入口,使用者只需要按照约定暴露初始化逻辑,并且提供了前置依赖使得任务可排序的功能。
到这里我们就可以明白这样几件事情:
- StartUp中使用异步和其排序加载之间存在“矛盾”
- StartUp不提供依赖有向无环图校验
因为StartUp更主要的是面向SDK,提供统一标准。SDK库之间出现“存在性上的先后关系”的场景本身就非常小,如果有“依赖”,SDK生产者在库内部都处理好了,一般也不会出现代码边界。
所以,Maat并不是一个和StartUp一较长短的功能库,而是为了解决特定问题而编写的功能库。这些问题又恰恰是StartUp所不涉及的
4.3.4 设计思路
相信大家对“同步”和“异步”都有比较深的理解,我们先提出三个参与初始化的角色:
- 任务: 初始化工作的最小单元,清晰的知道自己的所依赖的任务,只有依赖的任务都执行完毕后才能执行,我们以 Task=Name[dependency1,dependency2,...] 来表示任务,例如 B[] ==> 无前置依赖的任务B, A[B] ==> 任务A、依赖任务B
- 任务集:所有任务的集合,可分析任务的所有前置依赖并判断是否存在循环依赖,对任务进行排序,记为 TaskGroup={Task1,Task2,...}
- 任务调度器:从任务集中取出任务派发执行的调度器
回顾我们最开始给出的例子,组件之前有存在性先后关系,必须要让依赖的组件完成初始化后才能开始加载。 那么任务调度器的工作方式是“同步”的,在“被依赖的任务”执行完毕前,依赖他的任务都必须阻塞等待。
但是思考一个问题:两个互相独立的任务,必须阻塞等待吗?答案显然,不是必须的。这里举一些例子:
有任务集: {A[],B[],C[A,B]} ,A和B是无依赖的,C依赖任务A和B,那么任务调度器可以按照A、B、C的顺序进行调度,也可以按照B、A、C的顺序进行调度每个任务执行中,任务调度器都阻塞等待,也可以让AB两个任务并发(需要分配到不同线程)阻塞等待AB均完成后调度C。在第一个版本设计中,我还没有采用这个方案,目前让库保持足够轻量。当存在多组初始化路径时,其复杂程度远大于本处的例子
4.3.5 有向无环图(DAG)
接下来我们适当花一些篇幅来讨论DAG。在我们上面提到的任务集这一角色中,我们使用了DAG来处理拓扑排序和依赖无环校验。我们将任务看做是图中的顶点,任务的依赖关系看做是边,方向和依赖方向相反,即 A[B] 意味着有从B到A的边。将所有的任务合并起来后我们将得到一份有向图,显然,成环的依赖是不被允许的。
为了更好的理解,我们人为的添加一个虚拟的顶点Start,作为初始化任务集的第一个任务,将所有无依赖的任务人为添加一个前置依赖:Start。
一个合法的任务集,必然没有成环的依赖,所以一定不是强连通图,在我们添加了虚拟顶点start后,其基图一定是连通图,故而合法的任务集(包含虚拟Start节点)是一个弱连通图
4.3.6 环校验
我们采用DFS方式递归遍历,受益于我们制定的虚拟顶点Start,我们可以直接从这个顶点开始。定义深度集合 deepPathList,选定起始顶点S, 定义回环顶点列表 loopbackList, 定义路径列表 pathList 直接上代码 getEdgeContainsPoint(startPoint, Type.X) 代表取出所有以startPoint为起始点的边
fun recursive(startPoint: T, pathList: MutableList<T>) {
if (pathList.contains(startPoint)) {
loopbackList.add("${debugPathInfo(pathList)}->${startPoint.let(nameOf)}")
return
}
pathList.add(startPoint)
val edgesFromStartPoint = getEdgeContainsPoint(startPoint, Type.X)
if (edgesFromStartPoint.isEmpty()) {
val descList: ArrayList<T> = ArrayList(pathList.size)
pathList.forEach { path -> descList.add(path) }
deepPathList.add(descList)
}
edgesFromStartPoint.forEach {
recursive(it.to, pathList)
}
pathList.remove(startPoint)
}
如果loopbackList不为空,则代表存在回环,回环的信息就存放在loopbackList中
4.3.7 契合需求的排序方式
上面我们已经提到了深度优先遍历(DFS),但是这种方式作出的拓扑排序不适合我们的需求,他适合寻找最优或者最差路径。而广度优先遍历(BFS)才契合需求。直接给出代码:
private fun DAG<JOB>.bfs(): JobChunk {
val zeroDeque = ArrayDeque<JOB>()
val inDegrees = HashMap<JOB, Int>().apply {
putAll(this@bfs.inDegreeCache)
}
inDegrees.forEach { (v, d) ->
if (d == 0)
zeroDeque.offer(v)
}
val head = JobChunk.head()
var currentChunk = head
val tmpDeque = ArrayDeque<JOB>()
while (zeroDeque.isNotEmpty() || tmpDeque.isNotEmpty()) {
if (zeroDeque.isEmpty()) {
currentChunk = currentChunk.append()
zeroDeque.addAll(tmpDeque)
tmpDeque.clear()
}
zeroDeque.poll()?.let { vertex ->
currentChunk.addJob(vertex)
this.getEdgeContainsPoint(vertex, Type.X).forEach { edge ->
inDegrees[edge.to] = (inDegrees[edge.to] ?: 0).minus(edge.weight).apply {
if (this == 0)
tmpDeque.offer(edge.to)
}
}
}
}
return head
}
其中JubChunk是一组无关联的Job 即前文提到的初始化任务,前面提到目前没有让任务的执行可并发,JobChunk是为了可支持并发做准备的关于DAG的部分我们就不再花篇幅介绍了,有兴趣的同学可以自行查阅相关资料
4.3.8 任务的描述
先上代码:
abstract class JOB {
abstract val uniqueKey: String
abstract val dependsOn: List<String>
abstract val dispatcher: CoroutineDispatcher
internal fun runInit(maat: Maat) {
MainScope().launch {
flow {
init(maat)
emit(true)
}
.flowOn(dispatcher)
.catch {
maat.onJobFailed(this@JOB,it)
}.flowOn(Dispatchers.Main)
.collect {
maat.onJobSuccess(this@JOB)
}
}
}
abstract fun init(maat: Maat)
}
考虑到kotlin已经被官方推荐很长时间了,并且在去年Retrofit已经开始支持协程,姑且认为大部分项目中都已经开始使用协程了。所以很偷懒的直接使用了协程和Flow
- uniqueKey 是当前任务名,需要人为确保唯一性
- dependsOn 是当前任务所依赖的任务的uniqueKey的集合,虽然使用了List,但是顺序无关。
- dispatcher 指定任务执行被分配到的线程类型
- fun init(maat: Maat) 实际初始化逻辑,注意:按需求分析初始化代码块是否需要 “同步、阻塞”,如果部分代码是“异步、基于回调”且无法更改,这个实际场景(必须要异步获取结果,且该结果被另一个组件使用)想来很少见,第一个版本中我没有考虑,下个版本我会加上
示例代码模拟了4个初始化任务,有点长,具体的使用可以看一下Demo
val maat = Maat.init(application = this, printChunkMax = 6,
logger = object : Maat.Logger() {
override val enable: Boolean = true
override fun log(msg: String, throws: Throwable?) {
Log.d("maat", msg, throws)
}
}, callback = Maat.Callback(onSuccess = {}, onFailure = { maat, job, throwable ->
})
)
maat.append(object : JOB() {
override val uniqueKey: String = "a"
override val dependsOn: List<String> = emptyList()
override val dispatcher: CoroutineDispatcher = Dispatchers.IO
override fun init(maat: Maat) {
Log.e(
"maat",
"run:" + uniqueKey + " isMain:" + (Looper.getMainLooper() == Looper.myLooper())
)
//test exception
// throw NullPointerException("just a test")
}
override fun toString(): String {
return uniqueKey
}
}).append(object : JOB() {
override val uniqueKey: String = "b"
override val dependsOn: List<String> = arrayListOf("a")
override val dispatcher: CoroutineDispatcher = Dispatchers.Main /* + Job()*/
override fun init(maat: Maat) {
Log.e(
"maat",
"run:" + uniqueKey + " isMain:" + (Looper.getMainLooper() == Looper.myLooper())
)
}
override fun toString(): String {
return uniqueKey
}
}).append(object : JOB() {
override val uniqueKey: String = "c"
override val dependsOn: List<String> = arrayListOf("a")
override val dispatcher: CoroutineDispatcher = Dispatchers.IO /* + Job()*/
override fun init(maat: Maat) {
Log.e(
"maat",
"run:" + uniqueKey + " isMain:" + (Looper.getMainLooper() == Looper.myLooper())
)
}
override fun toString(): String {
return uniqueKey
}
}).append(object : JOB() {
override val uniqueKey: String = "d"
override val dependsOn: List<String> = arrayListOf("a", "b", "c")
override val dispatcher: CoroutineDispatcher = Dispatchers.Main
override fun init(maat: Maat) {
Log.e(
"maat",
"run:" + uniqueKey + " isMain:" + (Looper.getMainLooper() == Looper.myLooper())
)
}
override fun toString(): String {
return uniqueKey
}
}).start()
4.3.9 在JIMU中使用
JIMU是一种很彻底的组件化方案,意味着编写代码时存在代码边界,即使是空壳宿主和业务组件之间也存在。前面也提到了,JIMU是使用字节码技术织入的组件加载代码(设置为自动加载组件时),而织入的代码是在 Application 的onCreate最后执行。
这一前提下,如果通过javasist实现Maat的任务设置部分,他的可维护性将很差。所以我建议将任务设置部分放在组件的初始化入口处,这样可读性和可维护性都相对好一点。以原先的分享业务组件为例:
public class ShareApplike implements IApplicationLike {
UIRouter uiRouter = UIRouter.getInstance();
@Override
public void onCreate() {
uiRouter.registerUI("share");
Log.e("share","share on create");
Maat.Companion.getDefault().append(new JOB() {
@NotNull
@Override
public String getUniqueKey() {
return "share";
}
@NotNull
@Override
public List<String> getDependsOn() {
return Collections.singletonList("reader");
}
@NotNull
@Override
public CoroutineDispatcher getDispatcher() {
return Dispatchers.getMain();
}
@Override
public void init(@NotNull Maat maat) {
Log.d("share", "模拟初始化share,context:" +
maat.getApplication().getClass().getName());
}
@Override
public String toString() {
return getUniqueKey();
}
});
}
@Override
public void onStop() {
uiRouter.unregisterUI("share");
}
}
当然,务必不要忘记在Application的onCreate()中先初始化Maat:
Maat.Companion.init(this, 8, new Maat.Logger() {
@Override
public boolean getEnable() {
return true;
}
@Override
public void log(@NotNull String s, @Nullable Throwable throwable) {
if (throwable != null) {
Log.e("maat",s,throwable);
} else {
Log.d("maat",s);
}
}
}, new Maat.Callback(new Function1<Maat, Unit>() {
@Override
public Unit invoke(Maat maat) {
Maat.Companion.release();
return null;
}
}, new Function3<Maat, JOB, Throwable, Unit>() {
@Override
public Unit invoke(Maat maat, JOB job, Throwable throwable) {
return null;
}
}));
而Maat的启动API调用,自然由javasist织入了。配合最新的gradle插件 build-gradle:1.3.4方可使用,启用开关为:
combuild {
useMaat = true/false
}
4.3.10 重要事项
请务必分析项目的组件初始化场景,在Maat适用你的应用场景时再使用。