微服务的特点决定了它会存在较长的调用链路,一个请求一般会跨3个以上的服务(网关->应用聚合层->服务化层)而跟踪它的调用情况是异常定位及性能优化的关键之一。要能跟踪我们势必需要在日志中记录每个请求唯一的跟踪Id,我们可以在HTTP请求或MQ接收时判断消息Header是否存在Trace_Id,如果不存在则认为是新的请求,进而生成一个UUID作为Trace_Id,如果存在则沿用这个Trace_Id,然后在打日志时加上这个Trace_Id。最后通过日志收集工具将这个本地日志收集到一个聚合平台上进行查询。这能解决问题,实际上这也是Google Dapper(《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》)的核心思路,Google Dapper是Google的日志追踪服务。
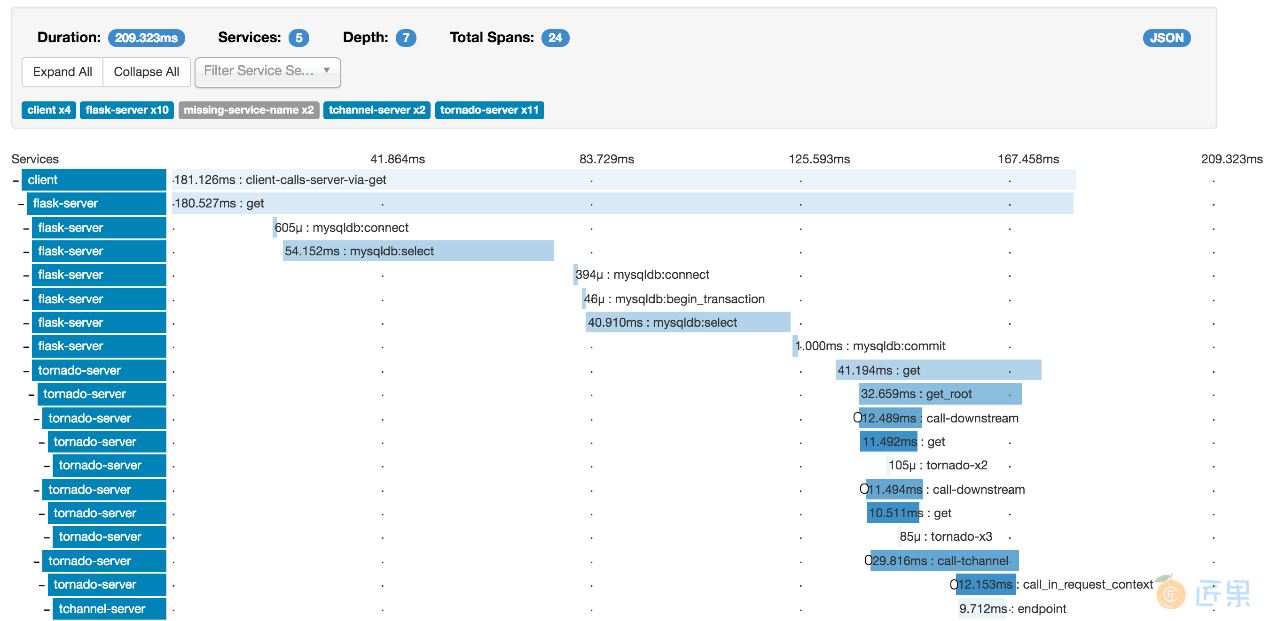
当然如果我们自己实现这些操作会很繁琐,好在我现成的框架可用,其中最著名的当属Zipkin,这是Twitter基于Google Dapper思想实现的开源日志追踪框架,它由采集器、存储、搜索及UI四个组件组成,采集器支持多种语言,官方支持的Java采集器是brave,存储支持Cassandra、MySQL、ES等,下图是它的UI,可以很方便、直观地查看调用情况(在线尝试:http://docssleuth-zipkin-server.cfapps.io/zipkin/ )。
Spring Cloud Sleuth是Spring Cloud体系下的日志追踪服务,也是对Google Dapper的模仿,它实现了Zipkin的采集器,可以与Zipkin配合使用。Sleuth官方有一张图可以很好说明其流程。
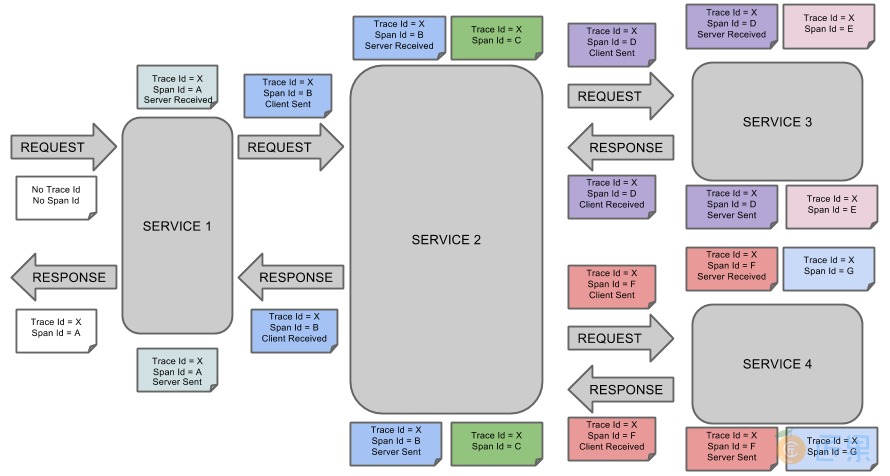
所有Google Dapper思想的日志追踪服务都有Trace与Span,Trace是指一次完整的调用,Tarce_Id在一次调用中唯一,可以通过它观察完整的链路,Span是调用中的每个节点请求,通过它可以观察某次调用各个节点请求的情况,如请求时间、响应时长等。
通过Spring Cloud Sleuth我们可以为项目透明地引入日志追踪功能,它打印的日志示例如下:
service1.log:2016-02-26 11:15:47.561 INFO [service1,2485ec27856c56f4,2485ec27856c56f4,true] 68058 --- [nio-8081-exec-1] i.s.c.sleuth.docs.service1.Application : Hello from service1. Calling service2
service2.log:2016-02-26 11:15:47.710 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Hello from service2. Calling service3 and then service4
service3.log:2016-02-26 11:15:47.895 INFO [service3,2485ec27856c56f4,1210be13194bfe5,true] 68060 --- [nio-8083-exec-1] i.s.c.sleuth.docs.service3.Application : Hello from service3
service2.log:2016-02-26 11:15:47.924 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Got response from service3 [Hello from service3]
service4.log:2016-02-26 11:15:48.134 INFO [service4,2485ec27856c56f4,1b1845262ffba49d,true] 68061 --- [nio-8084-exec-1] i.s.c.sleuth.docs.service4.Application : Hello from service4
service2.log:2016-02-26 11:15:48.156 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Got response from service4 [Hello from service4]
service1.log:2016-02-26 11:15:48.182 INFO [service1,2485ec27856c56f4,2485ec27856c56f4,true] 68058 --- [nio-8081-exec-1] i.s.c.sleuth.docs.service1.Application : Got response from service2 [Hello from service2, response from service3 [Hello from service3] and from service4 [Hello from service4]]
可以看到它会在日志中加入追踪信息:[,, ,]。
日志的收集是指将分散在各个节点的本地日志收集到统一聚合平台以方便行查询排错,这是很有必要的。如果日志不收集,我们需要去各个节点查询,一个服务还会有多个实例,麻烦不说,生产环境下的权限管理也会变得混乱。
追踪日志的收集可以是Zipkin规范,最简单地通过Http发送日志到Zipkin服务,当然这一方案要考虑性能影响,生产中更合理的方案可以考虑使用MQ。
非追踪日志的采集我们常见于ELK套件(ES、Logstash,Kibana),这一方案不多介绍,它问题在于Logstash的性能可能会是瓶颈,往往需要配合Kafka一同使用,当然也可以考虑尝试Fluentd,它用于替换Logstash,性能要优于后者,但笔者没有做过生产尝试。如果使用阿里云方案,那它的Logtail会是不错的选择,性能远高于Logstash,笔者的团队在使用一个服务节点一个Logstash的部署方案下压测Logstash导致的GC非常严重,但同样方案换成Logtail就非常平稳。Logtail唯一的问题在于它不开源,受限于云平台。
考虑到与Service Mesh的兼容,笔者认为jaegertracing 会比Zipkin更有优势,前者是CNCF成员,是对opentracing 规范的实现,并且是Istio官方推荐的实现。后续章节我们会有介绍。
下一节:我们谈了很多微服务改造的点,但已有项目转微服务势必会遇到一个棘手的问题:新系统怎么替换老系统?下面我就讨论下几种主流方案。