我喜欢重构的那种感觉 —— 把一坨烂代码,驯服成更易于阅读的代码。
准备知识:坏味道的模式
软件开发是一种团队活动,当组织缺乏强有力的 新鲜血液时,代码便会以相同的模式编写。该组织设计出来的架构,也从某种意义上出现了大量的趋同 —— 创新反而可能不好。在这种统一的模式之下,组织的代码也会呈现相似的坏味道。代码中的坏味道的模式也往往极为相似。
也因此,我们能快速地通过一小部分代码,了解整个项目的情况。
为此,我们只需要根据《重构:改善既有代码的设计》一书提出的 23 种代码坏味道,整理出系统中的常见坏味道。
| 集合类型 | 坏味道 |
|---|---|
| 代码臃肿 | 过长函数,过大的类,基本类型偏执,过长参数列,数据泥团 |
| 滥用面向对象 | Switch 声明,临时字段,被拒绝的遗赠,异曲同工的类 |
| 变革的障碍 | 发散式变化,霰弹式修改,平行继承体系 |
| 非必要的 | 冗余类,纯稚的数据类,重复代码,夸夸其谈的未来性,注释 |
| 耦合 | 不完美的类库,依恋情结,狎昵关系,消息链,中间人 |
随后,我们便能有针对性地对代码进行重构。
C4 模型
C4 Model 是一个非常不错的架构可视化工具,它从系统 System、容器 Container、组件 Component 和代码 Code 四个层次,由顶至底来介绍系统的架构:
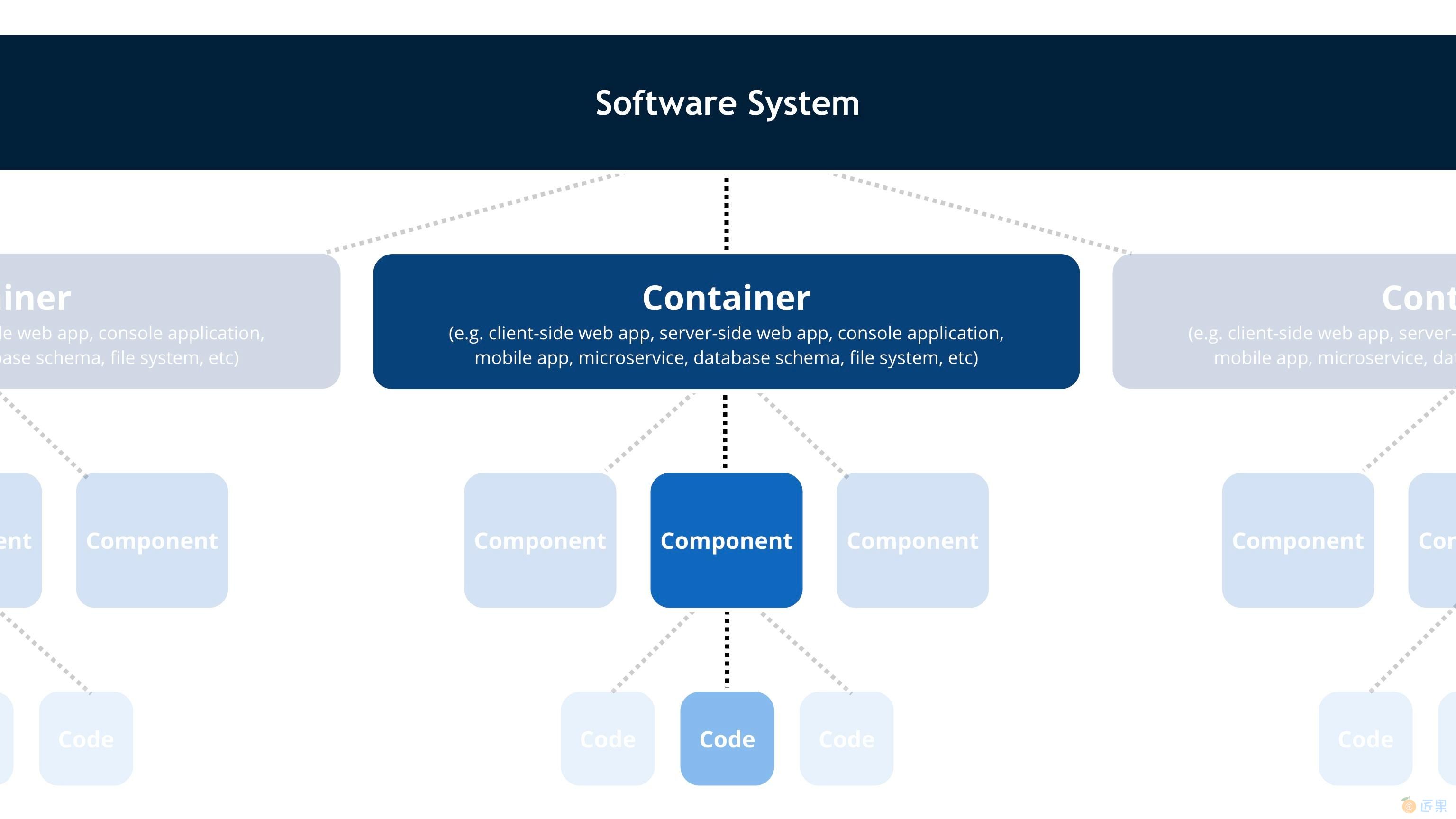
所以,我们可以根据 C4 模型的思路来查看整个应用的架构设计和代码情况。
探索模式
1. 从分层架构到具体代码
- 代码库间关系
- 代码库内模块化结构
- 模块化包结构
- 包内代码结构
2. 从外部适配器到内部适配器
举个例子,从 API 入手:
- Controller
- Service
- Model
- DAO
3. 查看测试情况
- 是否包含单元测试
- 是否包含集成测试
- 测试覆盖率情况
- 测试编写情况
4. 针对于最复杂的情形和最简单的情形
- 从最简单的场景出发,对常规流程、包间关系有一定的了解
- 从复杂的场景收尾,看最复杂的场景下会有什么问题
- 根据需要寻找一个适合的场景,
工具:API 列表和调用关系
针对于那些使用 Spring 框架的后端项目来说,可以尝试使用 coca api 来生成项目 API 调用图。
构建领域知识
作为一个碳基生物,我们要承认我们并非是全知的。我们所能做的事,来到一个新的领域时,能快速学习相关的知识。
了解业务架构
高水平的软件架构师不仅要懂技术,还要掌握问题空间对应的业务领域知识。—— 《软件架构师应该知道的 97 件事》
架构全景
简单来说,就是你知道对系统有一个初步的认知,它包含了:业务架构、技术架构、开发组成等等。
领域名词表
根据开发人员介绍的各种概念,抽象出一份系统的领域名词表。它的来源是:
- 项目的相关开发文档
- 项目中的架构资源
- 项目的代码
- ……
也因此,当你需要到一个新的项目实施重构计划时,一定需要有一个能与你结对编程的人。一个领域专家,一个代码专家,双方的无间配合,才能快速落地完成重构工作。
我们所要做的一个努力是,让文档、架构、元模型概念与代码实现一一对齐。这并不是一件容易的事情。从大多数项目的实践来看,架构师的设计和模型的实现往往是脱离的。因为设计架构的人和实现模型的人,往往不是同一些人。
我正在尝试根据它来编写这样的一个功能,但是它不是一件容易的事。只是呢,已经有一个小的雏形,通过 coca concept 从函数名称中抽取出部分的对应模式
| WORDS | COUNTS |
|---|---|
| blog | 15 |
| publish | 7 |
| entity | 6 |
| domain | 5 |
| published | 5 |
| resource | 4 |
| criteria | 4 |
但是,这只能是构建领域名词表的一个 hello, world,并不足以承担起真正的领域名词活动,也无法构建真正的领域名词表体系。
除此,我还在寻找一种更高效的构建领域特定语言方式,它用于帮助我们高效地进行软件开发,这种社会学活动。
寻找高引用 + 高修改
经常修改的代码,并不是见得是件好事。我们可以从中看到一些代码的坏味道,把它朝合适的方便引进,如类库,如包内聚等等
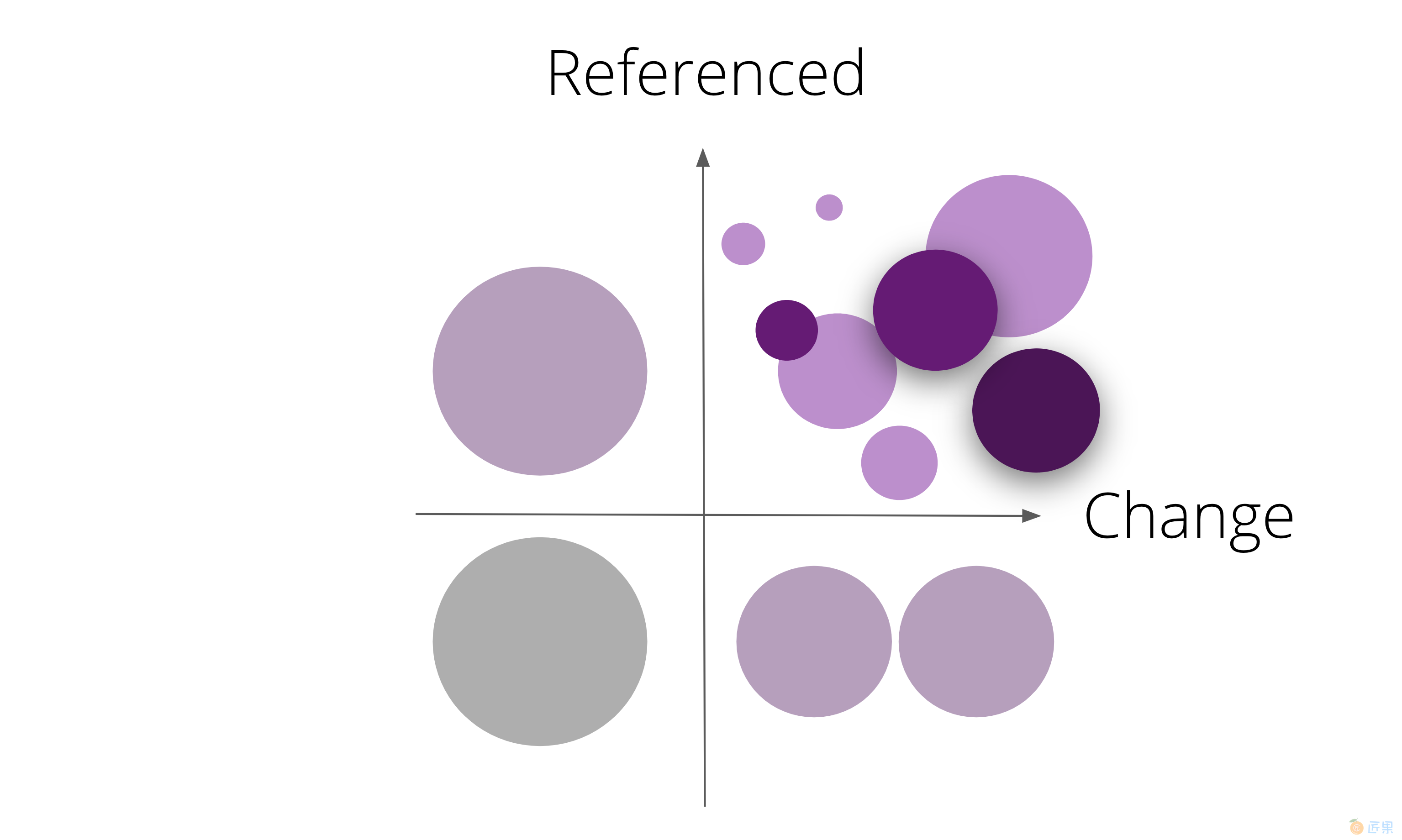
如果你使用的是 Git,可以通过 coca git -t 识别到高修改的文件:
| ENTITYNAME | REVSCOUNT | AUTHORCOUNT |
|---|---|---|
| build.gradle | 1326 | 36 |
| src/asciidoc/index.adoc | 239 | 20 |
| build-spring-framework/resources/changelog.txt | 187 | 10 |
| spring-core/src/main/java/org/springframework/core/annotation/AnnotationUtils.java | 170 | 10 |
| spring-beans/src/main/java/org/springframework/beans/factory/support/DefaultListableBeanFactory.java | 159 | 15 |
| src/docs/asciidoc/web/webmvc.adoc | 121 | 24 |
| spring-context/src/main/java/org/springframework/context/annotation/ConfigurationClassParser.java | 118 | 9 |
| src/dist/changelog.txt | 118 | 9 |
| spring-webmvc/src/main/java/org/springframework/web/servlet/config/annotation/WebMvcConfigurationSupport.java | 116 | 15 |
上述的代码是 Spring Framework 中最常修改的文件,前面三个文件看上去是合理的,但是 AnnotationUtils.java 显然有问题。
对应的 DefaultListableBeanFactory.java 也有 2000+ 行左右的规模。
从代码的行数和修改次数来看,它们都是上帝类,并且经常出现 Bug。
下表是 Spring 源码中引用最多的方法:
| REFS COUNT | METHOD |
|---|---|
| 2086 | org.springframework.util.Assert.notNull |
| 952 | org.apache.commons.logging.Log.debug |
| 773 | org.springframework.util.Assert.state |
| 666 | org.apache.commons.logging.Log.isDebugEnabled |
| 482 | org.apache.commons.logging.Log.trace |
| 425 | org.springframework.util.StringUtils.hasText |
| 398 | org.apache.commons.logging.LogFactory.getLog |
| 392 | org.apache.commons.logging.Log.isTraceEnabled |
| 268 | org.springframework.util.StringUtils.hasLength |
| 213 | org.springframework.util.Assert.isTrue |
从代码上来看,还是 Util 方法被引用得最多。似乎我们仍然需要一个更可靠的算法,来保证被引用的正常度。
下一节:尽管对于某些部分的重构来说,我们只是移动一下代码的位置 —— 如分层架构的调整,它不需要我们编写对应的测试。但是呢,出于流程完整性的考虑,这一步步往往流程比较长,毕竟它可以减少系统中 bug 的出现,降低重构的风险。与此同时,这是可以由团队一起协作完成的工作,特别适合于多人的协同重构方式。