一、集群规划
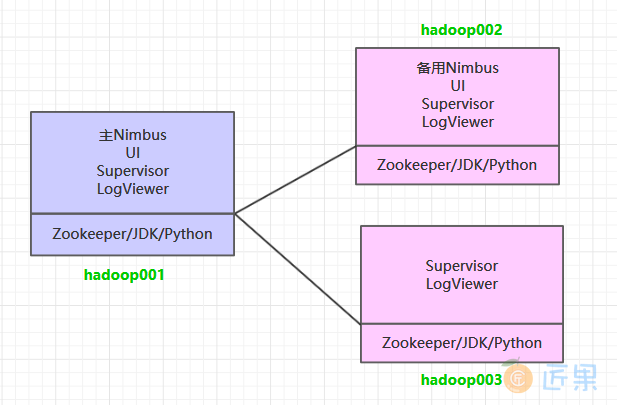
这里搭建一个 3 节点的 Storm 集群:三台主机上均部署 Supervisor 和 LogViewer 服务。同时为了保证高可用,除了在 hadoop001 上部署主 Nimbus 服务外,还在 hadoop002 上部署备用的 Nimbus 服务。Nimbus 服务由 Zookeeper 集群进行协调管理,如果主 Nimbus 不可用,则备用 Nimbus 会成为新的主 Nimbus。
二、前置条件
Storm 运行依赖于 Java 7+ 和 Python 2.6.6 +,所以需要预先安装这两个软件。同时为了保证高可用,这里我们不采用 Storm 内置的 Zookeeper,而采用外置的 Zookeeper 集群。由于这三个软件在多个框架中都有依赖,其安装步骤单独整理至 :
三、集群搭建
1. 下载并解压
下载安装包,之后进行解压。官方下载地址:http://storm.apache.org/downloads.html
# 解压
tar -zxvf apache-storm-1.2.2.tar.gz
2. 配置环境变量
# vim /etc/profile
添加环境变量:
export STORM_HOME=/usr/app/apache-storm-1.2.2
export PATH=$STORM_HOME/bin:$PATH
使得配置的环境变量生效:
# source /etc/profile
3. 集群配置
修改 ${STORM_HOME}/conf/storm.yaml 文件,配置如下:
# Zookeeper集群的主机列表
storm.zookeeper.servers:
- "hadoop001"
- "hadoop002"
- "hadoop003"
# Nimbus的节点列表
nimbus.seeds: ["hadoop001","hadoop002"]
# Nimbus和Supervisor需要使用本地磁盘上来存储少量状态(如jar包,配置文件等)
storm.local.dir: "/home/storm"
# workers进程的端口,每个worker进程会使用一个端口来接收消息
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
supervisor.slots.ports 参数用来配置 workers 进程接收消息的端口,默认每个 supervisor 节点上会启动 4 个 worker,当然你也可以按照自己的需要和服务器性能进行设置,假设只想启动 2 个 worker 的话,此处配置 2 个端口即可。
4. 安装包分发
将 Storm 的安装包分发到其他服务器,分发后建议在这两台服务器上也配置一下 Storm 的环境变量。
scp -r /usr/app/apache-storm-1.2.2/ root@hadoop002:/usr/app/
scp -r /usr/app/apache-storm-1.2.2/ root@hadoop003:/usr/app/
四. 启动集群
4.1 启动ZooKeeper集群
分别到三台服务器上启动 ZooKeeper 服务:
zkServer.sh start
4.2 启动Storm集群
因为要启动多个进程,所以统一采用后台进程的方式启动。进入到 ${STORM_HOME}/bin 目录下,执行下面的命令:
hadoop001 & hadoop002 :
# 启动主节点 nimbus
nohup sh storm nimbus &
# 启动从节点 supervisor
nohup sh storm supervisor &
# 启动UI界面 ui
nohup sh storm ui &
# 启动日志查看服务 logviewer
nohup sh storm logviewer &
hadoop003 : hadoop003 上只需要启动 supervisor 服务和 logviewer 服务:
# 启动从节点 supervisor
nohup sh storm supervisor &
# 启动日志查看服务 logviewer
nohup sh storm logviewer &
4.3 查看集群
使用 jps 查看进程,三台服务器的进程应该分别如下:

访问 hadoop001 或 hadoop002 的 8080 端口,界面如下。可以看到有一主一备 2 个 Nimbus 和 3 个 Supervisor,并且每个 Supervisor 有四个 slots,即四个可用的 worker 进程,此时代表集群已经搭建成功。
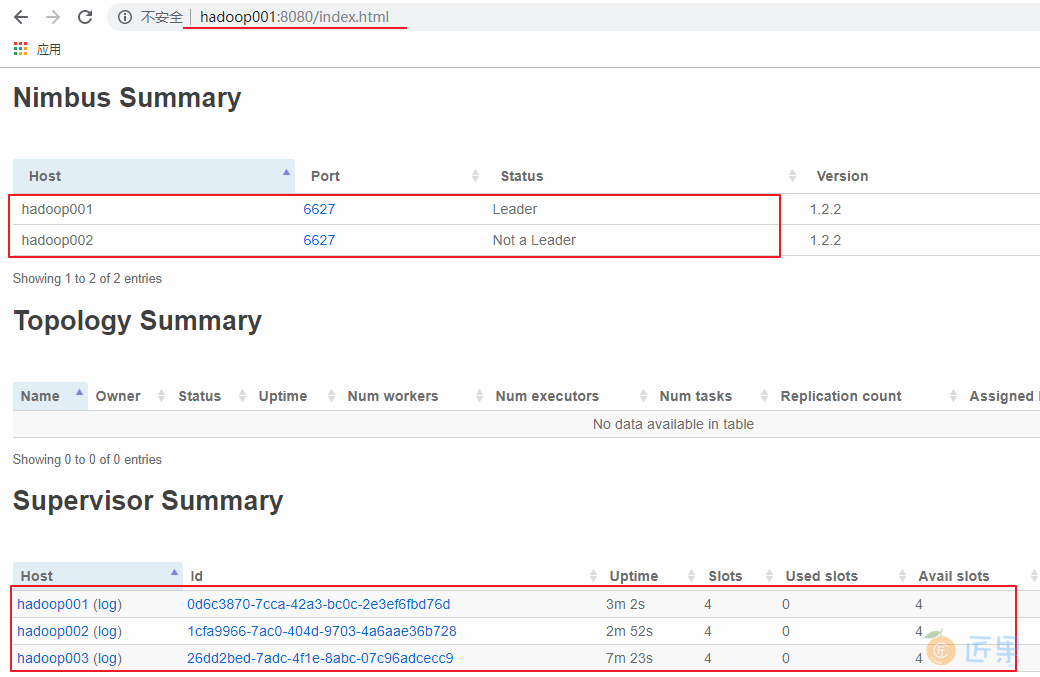
五、高可用验证
这里手动模拟主 Nimbus 异常的情况,在 hadoop001 上使用 kill 命令杀死 Nimbus 的线程,此时可以看到 hadoop001 上的 Nimbus 已经处于 offline 状态,而 hadoop002 上的 Nimbus 则成为新的 Leader。