与全局事务里讨论的单个服务使用多个数据源正好相反,共享事务(Share Transaction)是指多个服务共用同一个数据源。这里有必要再强调一次“数据源”与“数据库”的区别:数据源是指提供数据的逻辑设备,不必与物理设备一一对应。在部署应用集群时最常采用的模式是将同一套程序部署到多个中间件服务器上,构成多个副本实例来分担流量压力。它们虽然连接了同一个数据库,但每个节点配有自己的专属的数据源,通常是中间件以 JNDI 的形式开放给程序代码使用。这种情况下,所有副本实例的数据访问都是完全独立的,并没有任何交集,每个节点使用的仍是最简单的本地事务。而本节讨论的是多个服务之间会产生业务交集的场景,举个具体例子,在 Fenix's Bookstore 的 事务处理 中,假设用户账户、商家账户和商品仓库都存储于同一个数据库之中,但用户、商户和仓库每个领域都部署了独立的微服务,此时一次购书的业务操作将贯穿三个微服务,它们都要在数据库中修改数据。如果我们直接将不同数据源就视为是不同数据库,那上一节所讲的全局事务和下一节要讲的分布式事务都是可行的,不过,针对这种每个数据源连接的都是同一个物理数据库的特例,共享事务则有机会成为另一条可能提高性能、降低复杂度的途径,当然,也很有可能是一个伪需求。
一种理论可行 的方案是直接让各个服务共享数据库连接,同一个应用进程中的不同持久化工具(JDBC、ORM、JMS 等)中共享数据库连接并不困难,某些中间件服务器,譬如 WebSphere 会内置有“可共享连接”功能来专门给予这方面的支持。但这种共享的前提是数据源的使用者都在同一个进程内,由于数据库连接的基础是网络连接,它是与 IP 地址和端口号绑定的,字面意义上的“不同服务节点共享数据库连接”很难做到,所以为了实现共享事务,就必须新增一个“交易服务器”的中间角色,无论是用户服务、商家服务还是仓库服务,它们都通过同一台交易服务器来与数据库打交道。如果将交易服务器的对外接口按照 JDBC 规范来实现的话,那它完全可以视为是一个独立于各个服务的远程数据库连接池,或者直接作为数据库代理来看待。此时三个服务所发出的交易请求就有可能做到交由交易服务器上的同一个数据库连接,通过本地事务的方式完成。譬如,交易服务器根据不同服务节点传来的同一个事务 ID,使用同一个数据库连接来处理跨越多个服务的交易事务,如图 3-4 所示。
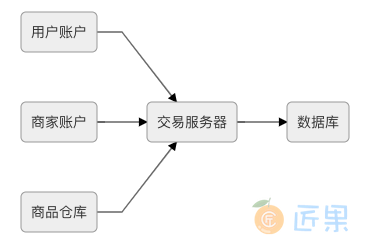
之所以强调理论可行,是因为该方案是与实际生产系统中的压力方向相悖的,一个服务集群里数据库才是压力最大而又最不容易伸缩拓展的重灾区,所以现实中只有类似ProxySQL、MaxScale这样用于对多个数据库实例做负载均衡的数据库代理(其实用 ProxySQL 代理单个数据库,再启用 Connection Multiplexing,已经接近于前面所提及的交易服务器方案了),而几乎没有反过来代理一个数据库为多个应用提供事务协调的交易服务代理。这也是说它更有可能是个伪需求的原因,如果你有充足理由让多个微服务去共享数据库,就必须找到更加站得住脚的理由来向团队解释拆分微服务的目的是什么才行。
在日常开发中,上述方案还存在一类更为常见的变种形式:使用消息队列服务器的来代替交易服务器,用户、商家、仓库的服务操作业务时,通过消息将所有对数据库的改动传送到消息队列服务器,通过消息的消费者来统一处理,实现由本地事务保障的持久化操作。这被称作“单个数据库的消息驱动更新”(Message-Driven Update of a Single Database)。
“共享事务”的提法和这里所列的两种处理方式在实际应用中并不值得提倡,鲜有采用这种方式的成功案例,能够查询到的资料几乎都发源于十余年前 Spring 的核心开发者Dave Syer撰写的文章《Distributed Transactions in Spring, with and without XA》。笔者把共享事务列为本章四种事务类型之一只是为了叙述逻辑的完备,尽管拆分微服务后仍然共享数据库的情况在现实中并不少见,但笔者个人不赞同将共享事务作为一种常规的解决方案来考量。