随着分布式架构渐成主流,可观测性(Observability)一词也日益频繁地被人提起。最初,它与可控制性(Controllability)一起,是由匈牙利数学家 Rudolf E. Kálmán 针对线性动态控制系统提出的一组对偶属性,原本的含义是“可以由其外部输出推断其内部状态的程度”。
在学术界,虽然“可观测性”这个名词是近几年才从控制理论中借用的舶来概念,不过其内容实际在计算机科学中已有多年的实践积累。学术界一般会将可观测性分解为三个更具体方向进行研究,分别是: 事件日志 、 链路追踪 和 聚合度量 ,这三个方向各有侧重,又不是完全独立,它们天然就有重合或者可以结合之处,2017 年的分布式追踪峰会(2017 Distributed Tracing Summit)结束后,Peter Bourgon 撰写了总结文章《Metrics, Tracing, and Logging》系统地阐述了这三者的定义、特征,以及它们之间的关系与差异,受到了业界的广泛认可。
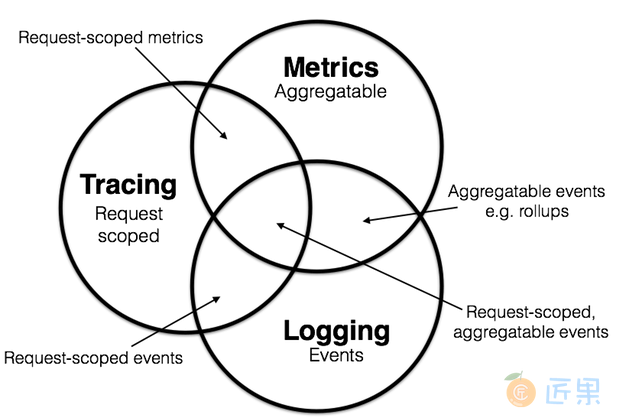
假如你平时只开发单体系统,从未接触过分布式系统的观测工作,那看到日志、追踪和度量,很有可能只会对日志这一项感到熟悉,其他两项会相对陌生。然而按照 Peter Bourgon 给出的定义来看,尽管分布式系统中追踪和度量必要性和复杂程度确实比单体系统时要更高,但是在单体时代,你肯定也已经接触过以上全部三项的工作,只是并未意识到而已,笔者将它们的特征转述如下:
- 日志 (Logging):日志的职责是记录离散事件,通过这些记录事后分析出程序的行为,譬如曾经调用过什么方法,曾经操作过哪些数据,等等。打印日志被认为是程序中最简单的工作之一,调试问题时常有人会说“当初这里记得打点日志就好了”,可见这就是一项举手之劳的任务。输出日志的确很容易,但收集和分析日志却可能会很复杂,面对成千上万的集群节点,面对迅速滚动的事件信息,面对数以 TB 计算的文本,传输与归集都并不简单。对大多数程序员来说,分析日志也许就是最常遇见也最有实践可行性的“大数据系统”了。
- 追踪 (Tracing):单体系统时代追踪的范畴基本只局限于栈追踪(Stack Tracing),调试程序时,在 IDE 打个断点,看到的 Call Stack 视图上的内容便是追踪;编写代码时,处理异常调用了
Exception::printStackTrace()方法,它输出的堆栈信息也是追踪。微服务时代,追踪就不只局限于调用栈了,一个外部请求需要内部若干服务的联动响应,这时候完整的调用轨迹将跨越多个服务,同时包括服务间的网络传输信息与各个服务内部的调用堆栈信息,因此,分布式系统中的追踪在国内常被称为“全链路追踪”(后文就直接称“链路追踪”了),许多资料中也称它为“分布式追踪”(Distributed Tracing)。追踪的主要目的是排查故障,如分析调用链的哪一部分、哪个方法出现错误或阻塞,输入输出是否符合预期,等等。 - 度量 (Metrics):度量是指对系统中某一类信息的统计聚合。譬如,证券市场的每一只股票都会定期公布财务报表,通过财报上的营收、净利、毛利、资产、负载等等一系列数据来体现过去一个财务周期中公司的经营状况,这便是一种信息聚合。Java 天生自带有一种基本的度量,就是由虚拟机直接提供的 JMX(Java Management eXtensions)度量,诸如内存大小、各分代的用量、峰值的线程数、垃圾收集的吞吐量、频率,等等都可以从 JMX 中获得。度量的主要目的是监控(Monitoring)和预警(Alert),如某些度量指标达到风险阈值时触发事件,以便自动处理或者提醒管理员介入。
在工业界,目前针对可观测性的产品已经是一片红海,经过多年的角逐,日志、度量两个领域的胜利者算是基本尘埃落定。日志收集和分析大多被统一到 Elastic Stack(ELK)技术栈上,如果说未来还能出现什么变化的话,也就是其中的 Logstash 能看到有被 Fluentd 取代的趋势,让 ELK 变成 EFK,但整套 Elastic Stack 技术栈的地位已是相当稳固。度量方面,跟随着 Kubernetes 统一容器编排的步伐,Prometheus 也击败了度量领域里以 Zabbix 为代表的众多前辈,即将成为云原生时代度量监控的事实标准,虽然从市场角度来说 Prometheus 还没有达到 Kubernetes 那种“拔剑四顾,举世无敌”的程度,但是从社区活跃度上看,Prometheus 已占有绝对的优势,在 Google 和 CNCF 的推动下,未来前途可期。
额外知识:Kubernetes 与 Prometheus 的关系
Kubernetes 是 CNCF 第一个孵化成功的项目,Prometheus 是 CNCF 第二个孵化成功的项目。
Kubernetes 起源于 Google 的编排系统 Borg,Prometheus 起源于 Google 为 Borg 做的度量监控系统 BorgMon。
追踪方面的情况与日志、度量有所不同,追踪是与具体网络协议、程序语言密切相关的,收集日志不必关心这段日志是由 Java 程序输出的还是由 Golang 程序输出的,对程序来说它们就只是一段非结构化文本而已,同理,度量对程序来说也只是一个个聚合的数据指标而已。但链路追踪就不一样,各个服务之间是使用 HTTP 还是 gRPC 来进行通信会直接影响追踪的实现,各个服务是使用 Java、Golang 还是 Node.js 来编写,也会直接影响到进程内调用栈的追踪方式。这决定了追踪工具本身有较强的侵入性,通常是以插件式的探针来实现;也决定了追踪领域很难出现一家独大的情况,通常要有多种产品来针对不同的语言和网络。近年来各种链路追踪产品层出不穷,市面上主流的工具既有像 Datadog 这样的一揽子商业方案,也有 AWS X-Ray 和 Google Stackdriver Trace 这样的云计算厂商产品,还有像 SkyWalking、Zipkin、Jaeger 这样来自开源社区的优秀产品。

图 10-2 是CNCF Interactive Landscape中列出的日志、追踪、度量领域的著名产品,其实这里很多不同领域的产品是跨界的,譬如 ELK 可以通过 Metricbeat 来实现度量的功能,Apache SkyWalking 的探针就有同时支持度量和追踪两方面的数据来源,由OpenTracing进化而来OpenTelemetry更是融合了日志、追踪、度量三者所长,有望成为三者兼备的统一可观测性解决方案。本章后面的讲解,也会扣紧每个领域中最具有统治性产品来进行介绍。