早在 Java 2 中之前,Java 就提供了特设类。比如:Dictionary, Vector, Stack, 和 Properties 这些类用来存储和操作对象组。譬如在 Java 中的数据结构主要包括以下几种接口和类:
- 枚举(Enumeration):枚举(Enumeration)接口虽然它本身不属于数据结构,但它在其他数据结构的范畴里应用很广。枚举(The Enumeration)接口定义了一种从数据结构中取回连续元素的方式。例如,枚举定义了一个叫 nextElement 的方法,该方法用来得到一个包含多元素的数据结构的下一个元素。
- 位集合(BitSet):位集合类实现了一组可以单独设置和清除的位或标志。该类在处理一组布尔值的时候非常有用,你只需要给每个值赋值一"位",然后对位进行适当的设置或清除,就可以对布尔值进行操作了。
- 向量(Vector):向量(Vector)类和传统数组非常相似,但是 Vector 的大小能根据需要动态的变化。和数组一样,Vector 对象的元素也能通过索引访问。使用 Vector 类最主要的好处就是在创建对象的时候不必给对象指定大小,它的大小会根据需要动态的变化。
- 栈(Stack):栈(Stack)实现了一个后进先出(LIFO)的数据结构。你可以把栈理解为对象的垂直分布的栈,当你添加一个新元素时,就将新元素放在其他元素的顶部。当你从栈中取元素的时候,就从栈顶取一个元素。换句话说,最后进栈的元素最先被取出。
- 字典(Dictionary):字典(Dictionary)类是一个抽象类,它定义了键映射到值的数据结构。当你想要通过特定的键而不是整数索引来访问数据的时候,这时候应该使用 Dictionary。由于 Dictionary 类是抽象类,所以它只提供了键映射到值的数据结构,而没有提供特定的实现。
- 哈希表(Hashtable):Hashtable 类提供了一种在用户定义键结构的基础上来组织数据的手段。例如,在地址列表的哈希表中,你可以根据邮政编码作为键来存储和排序数据,而不是通过人名。哈希表键的具体含义完全取决于哈希表的使用情景和它包含的数据。
- 属性(Properties):Properties 继承于 Hashtable.Properties 类表示了一个持久的属性集.属性列表中每个键及其对应值都是一个字符串。Properties 类被许多 Java 类使用。例如,在获取环境变量时它就作为 System.getProperties()方法的返回值。
虽然这些类都非常有用,但是它们缺少一个核心的,统一的主题。由于这个原因,使用 Vector 类的方式和使用 Properties 类的方式有着很大不同。
集合框架
集合框架是一个用来代表和操纵集合的统一架构。所有的集合框架都包含如下内容:
- 接口 :是代表集合的抽象数据类型。例如 Collection、List、Set、Map 等。之所以定义多个接口,是为了以不同的方式操作集合对象
- 实现(类) :是集合接口的具体实现。从本质上讲,它们是可重复使用的数据结构,例如:ArrayList、LinkedList、HashSet、HashMap。
- 算法 :是实现集合接口的对象里的方法执行的一些有用的计算,例如:搜索和排序。这些算法被称为多态,那是因为相同的方法可以在相似的接口上有着不同的实现。
集合框架被设计成要满足以下几个目标。
- 该框架必须是高性能的。基本集合(动态数组,链表,树,哈希表)的实现也必须是高效的。
- 该框架允许不同类型的集合,以类似的方式工作,具有高度的互操作性。
- 对一个集合的扩展和适应必须是简单的。
为此,整个集合框架就围绕一组标准接口而设计。你可以直接使用这些接口的标准实现,诸如:LinkedList,HashSet,和 TreeSet 等,除此之外你也可以通过这些接口实现自己的集合。
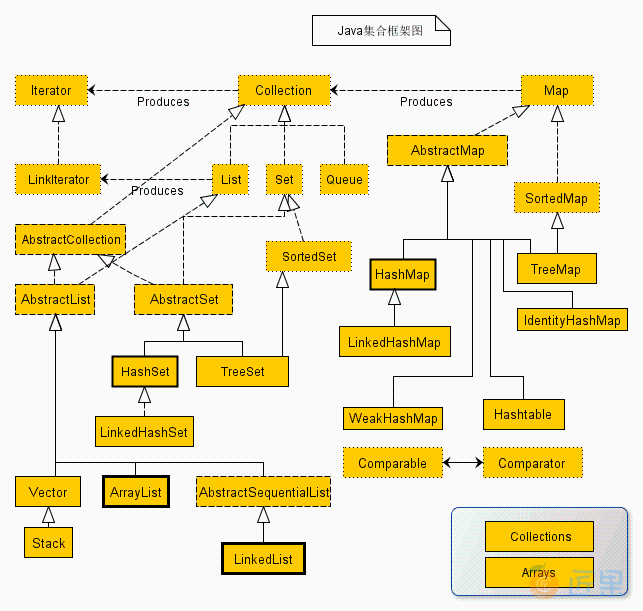
从上面的集合框架图可以看到,Java 集合框架主要包括两种类型的容器,一种是集合(Collection),存储一个元素集合,另一种是映射(Map),存储键/值对映射。Collection 接口又有 3 种子类型,List、Set 和 Queue,再下面是一些抽象类,最后是具体实现类,常用的有 ArrayList、LinkedList、HashSet、LinkedHashSet、HashMap、LinkedHashMap 等等。
- Collection 接口:Collection 是最基本的集合接口,一个 Collection 代表一组 Object,即 Collection 的元素, Java 不提供直接继承自 Collection 的类,只提供继承于的子接口(如 List 和 Set)。Collection 接口存储一组不唯一,无序的对象。
- List 接口:List 接口是一个有序的 Collection,使用此接口能够精确的控制每个元素插入的位置,能够通过索引(元素在 List 中位置,类似于数组的下标)来访问 List 中的元素,第一个元素的索引为 0,而且允许有相同的元素。List 接口存储一组不唯一,有序(插入顺序)的对象。
- Set:Set 具有与 Collection 完全一样的接口,只是行为上不同,Set 不保存重复的元素。Set 接口存储一组唯一,无序的对象。
- SortedSet:继承于 Set 保存有序的集合。
- Map:Map 接口存储一组键值对象,提供 key(键)到 value(值)的映射。
- Map.Entry:描述在一个 Map 中的一个元素(键/值对)。是一个 Map 的内部类。
- SortedMap:继承于 Map,使 Key 保持在升序排列。
- Enumeration:这是一个传统的接口和定义的方法,通过它可以枚举(一次获得一个)对象集合中的元素。这个传统接口已被迭代器取代。
其中,实线边框的是实现类,比如 ArrayList,LinkedList,HashMap 等,折线边框的是抽象类,比如 AbstractCollection,AbstractList,AbstractMap 等,而点线边框的是接口,比如 Collection,Iterator,List 等。发现一个特点,上述所有的集合类,都实现了 Iterator 接口,这是一个用于遍历集合中元素的接口,主要包含 hashNext(),next(),remove() 三种方法。它的一个子接口 LinkedIterator 在它的基础上又添加了三种方法,分别是 add(),previous(),hasPrevious()。也就是说如果是先 Iterator 接口,那么在遍历集合中元素的时候,只能往后遍历,被遍历后的元素不会在遍历到,通常无序集合实现的都是这个接口,比如 HashSet,HashMap;而那些元素有序的集合,实现的一般都是 LinkedIterator 接口,实现这个接口的集合可以双向遍历,既可以通过 next()访问下一个元素,又可以通过 previous()访问前一个元素,比如 ArrayList。
迭代器
通常情况下,你会希望遍历一个集合中的元素。例如,显示集合中的每个元素。一般遍历数组都是采用 for 循环或者增强 for,这两个方法也可以用在集合框架,但是还有一种方法是采用迭代器遍历集合框架,它是一个对象,实现了 Iterator 接口或 ListIterator 接口。
迭代器,使你能够通过循环来得到或删除集合的元素。ListIterator 继承了 Iterator,以允许双向遍历列表和修改元素。
遍历 ArrayList
import java.util.*;
public class Test{
public static void main(String[] args) {
List<String> list=new ArrayList<String>();
list.add("Hello");
list.add("World");
list.add("HAHAHAHA");
//第一种遍历方法使用 For-Each 遍历 List
for (String str : list) { //也可以改写 for(int i=0;i<list.size();i++) 这种形式
System.out.println(str);
}
//第二种遍历,把链表变为数组相关的内容进行遍历
String[] strArray=new String[list.size()];
list.toArray(strArray);
for(int i=0;i<strArray.length;i++) //这里也可以改写为 for(String str:strArray) 这种形式
{
System.out.println(strArray[i]);
}
//第三种遍历 使用迭代器进行相关遍历
Iterator<String> ite=list.iterator();
while(ite.hasNext())//判断下一个元素之后有值
{
System.out.println(ite.next());
}
}
}
三种方法都是用来遍历 ArrayList 集合,第三种方法是采用迭代器的方法,该方法可以不用担心在遍历的过程中会超出集合的长度。
遍历 Map
import java.util.*;
public class Test{
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
map.put("1", "value1");
map.put("2", "value2");
map.put("3", "value3");
// 第一种:普遍使用,二次取值
System.out.println("通过Map.keySet遍历key和value:");
for (String key : map.keySet()) {
System.out.println("key= "+ key + " and value= " + map.get(key));
}
// 第二种
System.out.println("通过Map.entrySet使用iterator遍历key和value:");
Iterator<Map.Entry<String, String>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<String, String> entry = it.next();
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
// 第三种:推荐,尤其是容量大时
System.out.println("通过Map.entrySet遍历key和value");
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
//第四种
System.out.println("通过Map.values()遍历所有的value,但不能遍历key");
for (String v : map.values()) {
System.out.println("value= " + v);
}
}
}
如果遍历 hashMap() 时 entrySet() 方法是将 key 和 value 全部取出来,所以性能开销是可以预计的, 而 keySet() 方法进行遍历的时候是根据取出的 key 值去查询对应的 value 值, 所以如果 key 值是比较简单的结构(如 1,2,3...)的话性能消耗上是比 entrySet() 方法低, 但随着 key 值得复杂度提高 entrySet() 的优势就会显露出来。
综合比较在只遍历 key 的时候使用 keySet(), 在只遍历 value 的是使用 values() 方法, 在遍历 key-value 的时候使用 entrySet() 是比较合理的选择。如果遍历 TreeMap 的时候, 不同于 HashMap 在遍历 ThreeMap 的 key-value 时候务必使用 entrySet() 它要远远高于其他两个的性能, 同样只遍历 key 的时候使用 keySet(), 在只遍历 value 的是使用 values() 方法对于 TreeMap 也同样适用。
Comparator
TreeSet 和 TreeMap 的按照排序顺序来存储元素. 然而,这是通过比较器来精确定义按照什么样的排序顺序。这个接口可以让我们以不同的方式来排序一个集合。
Comparator<Developer> byName = new Comparator<Developer>() {
@Override
public int compare(Developer o1, Developer o2) {
return o1.getName().compareTo(o2.getName());
}
};
Comparator<Developer> byName =
(Developer o1, Developer o2)->o1.getName().compareTo(o2.getName());
List<Developer> listDevs = getDevelopers();
//sort by age
Collections.sort(listDevs, new Comparator<Developer>() {
@Override
public int compare(Developer o1, Developer o2) {
return o1.getAge() - o2.getAge();
}
});
public class NewClass2 implements Comparator<Point> {
public int compare(Point p1, Point p2) {
if (p1.getY() < p2.getY()) return -1;
if (p1.getY() > p2.getY()) return 1;
return 0;
}
}
List 与 Array 转换
List 接口提供了 toArray() 方法来返回包含列表元素的 Object 数组:
List<String> list = Arrays.asList("C", "C++", "Java");
Collections.singletonList("test");
Object[] array = list.toArray();
System.out.println(Arrays.toString(array));Copy to clipboardErrorCopied
不过该函数并不了解元素的类型,可以通过 toArray(T[] a) 来返回指定类型的数组:
List<String> list = Arrays.asList("C", "C++", "Java");
String[] array = list.toArray(new String[list.size()]);
System.out.println(Arrays.toString(array));
// 我们还可以传入空数组来让 JVM 自动分配内存
List<String> list = Arrays.asList("C", "C++", "Java");
String[] array = list.toArray(new String[0]);
System.out.println(Arrays.toString(array));Copy to clipboardErrorCopied
在 Java 8 中我们可以使用 Stream API 来将列表转化为数组:
List<String> list = Arrays.asList("C", "C++", "Java");
String[] array = list.stream().toArray(String[]::new);
System.out.println(Arrays.toString(array));
List<String> list = Arrays.asList("C", "C++", "Java");
String[] array = list.stream().toArray(n -> new String[n]);
System.out.println(Arrays.toString(array));Copy to clipboardErrorCopied
可以使用 asList 等方法将数组转化为列表:
ArrayList<String> arrayList = new ArrayList<String>(Arrays.asList(arrays));
List<String> list = Arrays.asList(arrays);
List<String> list2 = new ArrayList<String>(arrays.length);
Collections.addAll(list2, arrays);Copy to clipboardErrorCopied
List 与 Map
Map 转化为 List
Map<String, String> map = new HashMap<>();
// Convert all Map keys to a List
List<String> result = new ArrayList(map.keySet());
// Convert all Map values to a List
List<String> result2 = new ArrayList(map.values());
// Java 8, Convert all Map keys to a List
List<String> result3 = map.keySet().stream()
.collect(Collectors.toList());
// Java 8, Convert all Map values to a List
List<String> result4 = map.values().stream()
.collect(Collectors.toList());
// Java 8, seem a bit long, but you can enjoy the Stream features like filter and etc.
List<String> result5 = map.values().stream()
.filter(x -> !"apple".equalsIgnoreCase(x))
.collect(Collectors.toList());
// Java 8, split a map into 2 List, it works!
// refer example 3 belowCopy to clipboardErrorCopied
我们也可以在转化过程中引入流变换操作:
// split a map into 2 List
List<Integer> resultSortedKey = new ArrayList<>();
List<String> resultValues = map.entrySet().stream()
//sort a Map by key and stored in resultSortedKey
.sorted(Map.Entry.<Integer, String>comparingByKey().reversed())
.peek(e -> resultSortedKey.add(e.getKey()))
.map(x -> x.getValue())
// filter banana and return it to resultValues
.filter(x -> !"banana".equalsIgnoreCase(x))
.collect(Collectors.toList());
resultSortedKey.forEach(System.out::println);
resultValues.forEach(System.out::println);Copy to clipboardErrorCopied
List 转化为 Map
可以使用 Collectors.toMap 来将某个列表转化为 Map:
// key = id, value - websites
Map<Integer, String> result1 = list.stream().collect(
Collectors.toMap(Hosting::getId, Hosting::getName));
System.out.println("Result 1 : " + result1);
// key = name, value - websites
Map<String, Long> result2 = list.stream().collect(
Collectors.toMap(Hosting::getName, Hosting::getWebsites));
System.out.println("Result 2 : " + result2);
// Same with result1, just different syntax
// key = id, value = name
Map<Integer, String> result3 = list.stream().collect(
Collectors.toMap(x -> x.getId(), x -> x.getName()));
System.out.println("Result 3 : " + result3);Copy to clipboardErrorCopied
对于可能的键值重复,可以传入第三个 mergeFunction 参数来进行处理:
Map<String, Long> result1 = list.stream().collect(
Collectors.toMap(Hosting::getName, Hosting::getWebsites,
(oldValue, newValue) -> oldValue
)
);Copy to clipboardErrorCopied
如果需要对列表进行排序等操作,则可以使用中间操作符:
Map result1 = list.stream()
.sorted(Comparator.comparingLong(Hosting::getWebsites).reversed())
.collect(
Collectors.toMap(
Hosting::getName, Hosting::getWebsites, // key = name, value = websites
(oldValue, newValue) -> oldValue, // if same key, take the old key
LinkedHashMap::new // returns a LinkedHashMap, keep order
));Copy to clipboardErrorCopied
下一节:在 Grade 中,我们常见的几个关键术语有 Project、Plugin 以及 Task。和 Maven 一样,Gradle 只是提供了构建项目的一个框架,真正起作用的是 Plugin。Gradle 在默认情况下为我们提供了许多常用的 Plugin,其中包括有构建 Java 项目的 Plugin,还有 War,Ear 等。与 Maven 不同的是,Gradle 不提供内建的项目生命周期管理,只是 Java Plugin 向 Project 中添加了许多 Task,这些 Task 依次执行,为我们营造了一种如同 Maven 般项目构建周期。换言之,Project 为 Task 提供了执行上下文,所有的 Plugin 要么向 Project 中添加用于配置的 Property,要么向 Project 中添加不同的 Task。一个 Task 表示一个逻辑上较为独立的执行过程,比如编译 Java 源代码,拷贝文件,打包 Jar 文件,甚至可以是执行一个系统命令或者调用 Ant。另外,一个 Task 可以读取和设置 Project 的 Property 以完成特定的操作。