JIT
JIT 是 Just-In-Time Compiliation 的缩写,中文为即时编译。就是 Java 在运行过程中,如果有些动态极度频繁的被执行或者不被执行,就会被自动编译成机器码,跳过其中的部分环节。Java 源码通过编译器转为平台无关的字节码(Bytecode)或 Java class 文件。在启动 Java 应用程序后,JVM 会在运行时加载编译后的类并通过 Java 解释器执行适当的语义计算。当开启 JIT 时,JVM 会分析 Java 应用程序的函数调用并且(达到内部一些阀值后)编译字节码为本地更高效的机器码,编译出的原生机器码被存储在非堆内存的代码缓存中。
JIT 流程通常为最繁忙的函数调用提供更高的优先级。一旦函数调用被转为机器码,JVM 会直接执行而不是解释执行,上述过程会在程序运行过程中不断提高性能。通过这种方法,Hotspot 虚拟机将权衡下面两种时间消耗:将字节码编译成本地代码需要的额外时间和解释执行字节码消耗更多的时间。
分层编译
随着代码的执行,JVM 的 JIT 编译器会将部分热点代码编译为目标机器代码;JVM 提供了一个参数 -Xcomp ,这个参数可以使 JVM 运行在纯编译的模式,所有的方法在第一次调用的时候就会编成机器代码,但是设置了这个参数之后系统启动负载的确没有上升,但是启动的时间是原来的两倍多。
除了纯编译和默认的 mixed 之外,JVM 从 jdk6u25 之后,引入了分层编译(-XX:+TieredCompilation)。HotSpot 内置两种编译器,分别是 client 启动时的 c1 编译器和 server 启动时的 c2 编译器,c2 在将代码编译成机器代码的时候需要搜集大量的统计信息以便在编译的时候进行优化,因此编译出来的代码执行效率比较高,代价是程序启动时间比较长,而且需要执行比较长的时间,才能达到最高性能;与之相反,c1 的目标是使程序尽快进入编译执行的阶段,所以在编译前需要搜集的信息比 c2 要少,编译速度因此提高很多,但是付出的代价是编译之后的代码执行效率比较低,但尽管如此,c1 编译出来的代码在性能上比解释执行的性能已经有很大的提升,所以所谓的分层编译,就是一种折中方式,在系统执行初期,执行频率比较高的代码先被 c1 编译器编译,以便尽快进入编译执行,然后随着时间的推移,执行频率较高的代码再被 c2 编译器编译,以达到最高的性能。
// globalDefinitions.hpp
enum CompLevel {
CompLevel_any = -1,
CompLevel_all = -1,
CompLevel_none = 0, // Interpreter
CompLevel_simple = 1, // C1
CompLevel_limited_profile = 2, // C1, invocation & backedge counters
CompLevel_full_profile = 3, // C1, invocation & backedge counters + mdo
CompLevel_full_optimization = 4, // C2 or Shark
... ...
};Copy to clipboardErrorCopied
目前分层编译包括五个编译层次:Level 0 - Level 4。大家可以在启动参数中加入-XX:+PrintCompilation 来查看被编译的方法及其层次:
- Level0 即解释执行,由解释器负责执行 Java 方法。这种方式无编译开销,但速度很慢;解释器并不开启性能监控功能,可触发第一层编译。
- Level1 程序由 C1 编译器编译为本地机器指令执行,C1 编译器会对字节码进行简单和可靠的优化,以达到更快的编译速度。编译方法受限,编译开销比较低,性能比 Level4 差,但强于其他层次。
- Level2 程序由 C1 编译器编译为本地机器指令执行,但 C2 编译器会启动一些编译耗时更长的优化(代码将有可能被重复编译多次),甚至有可能根据性能监控信息进行一些不可靠的激进优化。编译开销比较低,性能差于 Level4 和 Level1。
- Level3 由 C1 负责编译,除了方法执行次数和回边次数的统计外,还加入了对方法内部执行信息的统计,如一个分枝是否执行跳转,一个虚函数调用最终调用到哪个方法等信息。Level3 性能较差,仅比 Level0 快,但是 Level3 是 Level4 编译的必要步骤。程序由 C1 编译器编译为本地机器指令执行,采集性能数据进行优化措施;
- Level4 由 C2 负责编译,它利用 level3 收集的信息,对方法进行完全的优化,性能最好,但是编译开销也最大。程序由 C2 编译器编译为本地机器指令执行,进行完全优化。
下述列举了判断一个方法是否需要触发编译的及编译到哪个层次的具体公式:
| 参数 | 说明 | 默认值 |
|---|---|---|
| Tier3InvocationThreshold | 一个方法被调用多少次之后会进行 level3 编译 | 200 |
| Tier4InvocationThreshold | 一个方法被调用多少次之后会进行 level4 编译 | 5000 |
| Tier3CompileThreshold | 考虑回边的情况下,一个方法执行多少次之后会进行 level3 编译 | 2000 |
| Tier4CompileThreshold | 考虑回边的情况下,一个方法执行多少次之后会进行 level4 编译 | 15000 |
| Tier3BackEdgeThreshold | 一个方法中回边执行多少次会进行 OSR level3 编译 | 60000 |
| Tier4BackEdgeThreshold | 一个方法中回边执行多少次会进行 OSR level4 编译 | 40000 |
| CICompilerCount | 编译线程数目 | 无 |
| Tier3LoadFeedback | 用来动态调整 level3 编译阈值的值 | 5 |
| Tier4LoadFeedback | 用来动态调整 level4 编译阈值的值 | 3 |
| Tier3DelayOn | 平均每个 C2 编译线程排队个数达到多少个时停止 level3 编译 | 5 |
| Tier3DelayOff | 平均每个 C2 编译线程排队个数降低到多少个时恢复 level3 编译 | 2 |
最常见的 0 -> 3 -> 4 编译,高 C2 编译压力下的 0 -> 2 -> 3 -> 4 编译;level2 的性能比 level3 好。当 C2 的编译压力很大的情况下,新编译的 level3 方法可能方法会长时间的运行在效率相对比较低的代码上而不能及时晋升到 level4。在这种情况下,将待编译的方法编译成 level2 而不是 level3 会是一个更好的方法。总体上,C2 编译压力比较大的情况下是先解释执行,达到一定次数编译成 level2,然后等 C2 编译压力变小的时候会晋升成 level3,最后如果执行次数足够多的话会晋升成 level4。
Level1 与 level2 和 level3 不同,它是一个不收集运行数据的最终编译状态。 当一个方法需要进行编译的时候,我们会首先判断它是否符合以下条件:
- 这个方法只是用来获取类中的某个域的值的
- 这个方法只是用来获取常量的
- 这个方法很小
满足这三个条件其中之一的方法会直接被编译成 level1 并且不会晋升为其他 level。由于 C2 编译耗时较多,往往要达到几百毫秒甚至超过一秒,因此在高峰期行 Level4 编译通常并不划算,因此 JVM 参数的调整的思路是增大 level4 阈值,减少 level4 编译。具体的,可以通过增大 Tier4InvocationThreshold 和 Tier4CompileThreshold 来增大阈值。编译开销主要在于 C2 的编译线程,因此通过一定的手段限制 C2 编译线程的 CPU 使用可以减少高峰期编译开销。在本次测试中,使用在每编译完成一个方法后,sleep 200ms 的方法来限制 C2 编译线程 CPU 使用率。
字节码
如下简单的 Java 代码:
public static void main(String[] args) {
int a = 1;
int b = 2;
int c = a + b;
}
// javac Test.java
// javap -v Test.classCopy to clipboardErrorCopied
编译而来的字节码如下所示:
// main 方法的签名
public static void main(java.lang.String[]);
// 第二部分的 descriptor 表示方法拥有一个类型为 [Ljava/lang/String; 的参数,返回值类型是 V
descriptor: ([Ljava/lang/String;)V
// 一系列指示符,ACC_PUBLIC 表明方法是 public 类型,ACC_STATIC 表明方法是 static 类型
flags: (0x0009) ACC_PUBLIC, ACC_STATIC
// 代码区
Code:
// stack 表示操作栈的最大深度,locals 表示本地变量数组的长度,args_size 表示参数的个数。在指令执行过程中,所有局部变量会陆续被操作,但 args 除外,它固定放在本地变量数组索引等于 0 的位置。
stack=2, locals=4, args_size=1
// 常量 1 推入操作栈
0: iconst_1
// 从操作栈弹出一个 int 值,存入索引为 1 的本地变量中,对应源码中的变量 a
1: istore_1
// 将常量 2 推入操作栈
2: iconst_2
// 从操作栈弹出一个 int 值,存入索引为 2 的本地变量中,对应源码中的变量 b
3: istore_2
// 从索引为 1 的本地变量中取出 int 值,推入操作栈
4: iload_1
// 从索引为 2 的本地变量中取出 int 值,推入操作栈
5: iload_2
// 从操作栈弹出两个 int 值,然后相加,并将结果推入操作栈
6: iadd
// 从操作栈弹出 int 值,存入索引为 3 的本地变量中,对应源码中的变量c
7: istore_3
8: return
...
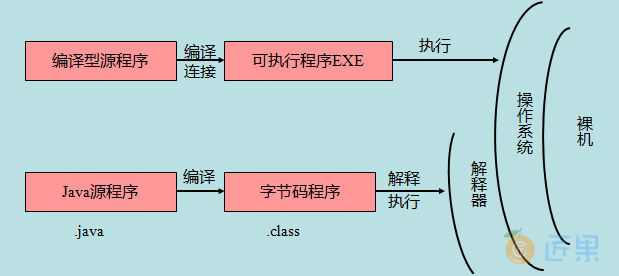
下一节:JVM 是虚拟机的一种,它的指令集语言是字节码,字节码构成的文件是 class 文件。平常我们写的 Java 文件,需要编译为 class 文件才能交给 JVM 运行。可以这么说:C 语言代码——>二进制文件——>计算机硬件,就相当于 Java 代码——>字节码文件——>JVM。JVM 将指定的 class 文件读取到内存里,并运行该 class 文件里的 Java 程序的过程,就称之为类的加载;反之,将某个 class 文件的运行时数据从 JVM 中移除的过程,就称之为类的卸载。