分布式搜索的执行方式
在继续之前,我们将绕道讲一下搜索是如何在分布式环境中执行的。 它比我们之前讲的基础的增删改查 (create-read-update-delete ,CRUD)请求要复杂一些。
注意:
本章的信息只是出于兴趣阅读,使用Elasticsearch并不需要理解和记住这里的所有细节。
阅读这一章只是增加对系统如何工作的了解,并让你知道这些信息以备以后参考,所以别淹没在细节里。
一个CRUD操作只处理一个单独的文档。文档的唯一性由_index, _type和routing-value(通常默认是该文档的_id)的组合来确定。这意味着我们可以准确知道集群中的哪个分片持有这个文档。由于不知道哪个文档会匹配查询(文档可能存放在集群中的任意分片上),所以搜索需要一个更复杂的模型。一个搜索不得不通过查询每一个我们感兴趣的索引的分片副本,来看是否含有任何匹配的文档。但是,找到所有匹配的文档只完成了这件事的一半。在搜索(search)API返回一页结果前,来自多个分片的结果必须被组合放到一个有序列表中。因此,搜索的执行过程分两个阶段,称为查询然后取回 (query then fetch )。
查询阶段
在初始化查询阶段 (query phase ),查询被向索引中的每个分片副本(原本或副本)广播。每个分片在本地执行搜索并且建立了匹配document的优先队列 (priority queue )。
优先队列
一个优先队列 (priority queue is)只是一个存有前n个 (top-n )匹配document的有序列表。这个优先队列的大小由分页参数from和size决定。例如,下面这个例子中的搜索请求要求优先队列要能够容纳100个document
GET /_search
{
"from": 90,
"size": 10
}
这个查询的过程被描述在图分布式搜索查询阶段中。
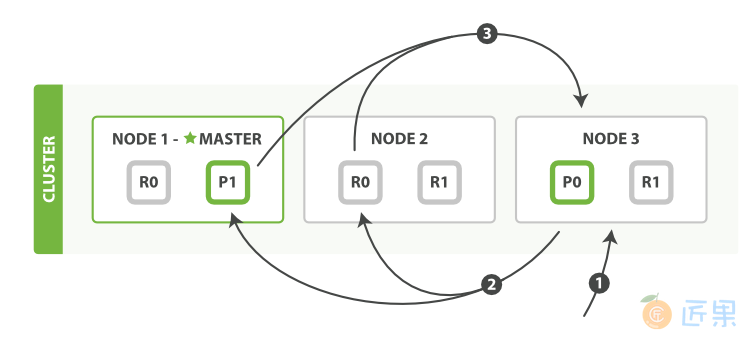
查询阶段包含以下三步:
- 客户端发送一个
search(搜索)请求给Node 3,Node 3创建了一个长度为from+size的空优先级队列。 Node 3转发这个搜索请求到索引中每个分片的原本或副本。每个分片在本地执行这个查询并且结果将结果到一个大小为from+size的有序本地优先队列里去。- 每个分片返回document的ID和它优先队列里的所有document的排序值给协调节点
Node 3。Node 3把这些值合并到自己的优先队列里产生全局排序结果。
当一个搜索请求被发送到一个节点Node,这个节点就变成了协调节点。这个节点的工作是向所有相关的分片广播搜索请求并且把它们的响应整合成一个全局的有序结果集。这个结果集会被返回给客户端。第一步是向索引里的每个节点的分片副本广播请求。就像document的GET请求一样,搜索请求可以被每个分片的原本或任意副本处理。这就是更多的副本(当结合更多的硬件时)如何提高搜索的吞吐量的方法。对于后续请求,协调节点会轮询所有的分片副本以分摊负载。
每一个分片在本地执行查询和建立一个长度为from+size的有序优先队列——这个长度意味着它自己的结果数量就足够满足全局的请求要求。分片返回一个轻量级的结果列表给协调节点。只包含documentID值和排序需要用到的值,例如_score。协调节点将这些分片级的结果合并到自己的有序优先队列里。这个就代表了最终的全局有序结果集。到这里,查询阶段结束。整个过程类似于归并排序算法,先分组排序再归并到一起,对于这种分布式场景非常适用。
注意
一个索引可以由一个或多个原始分片组成,所以一个对于单个索引的搜索请求也需要能够把来自多个分片的结果组合起来。一个对于 多(multiple) 或全部(all) 索引的搜索的工作机制和这完全一致——仅仅是多了一些分片而已。
取回阶段
查询阶段辨别出那些满足搜索请求的document,但我们仍然需要取回那些document本身。这就是取回阶段的工作,如图分布式搜索的取回阶段所示。
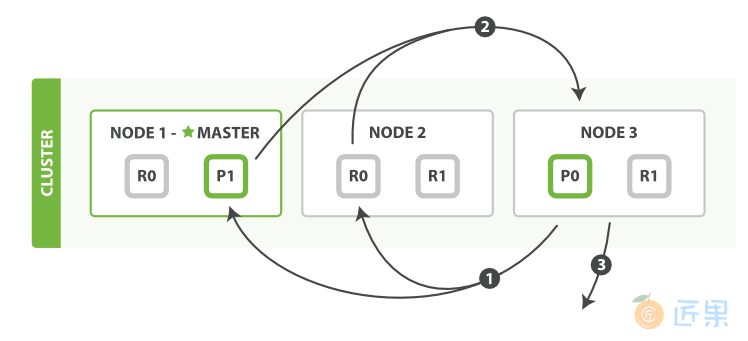
分发阶段由以下步骤构成:
- 协调节点辨别出哪个document需要取回,并且向相关分片发出
GET请求。 - 每个分片加载document并且根据需要丰富(enrich) 它们,然后再将document返回协调节点。
- 一旦所有的document都被取回,协调节点会将结果返回给客户端。
协调节点先决定哪些document是实际(actually) 需要取回的。例如,我们指定查询{ "from": 90, "size": 10 },那么前90条将会被丢弃,只有之后的10条会需要取回。这些document可能来自与原始查询请求相关的某个、某些或者全部分片。
协调节点为每个持有相关document的分片建立多点get请求然后发送请求到处理查询阶段的分片副本。分片加载document主体——_source field。如果需要,还会根据元数据丰富结果和高亮搜索片断。一旦协调节点收到所有结果,会将它们汇集到单一的回答响应里,这个响应将会返回给客户端。
深分页
查询然后取回过程虽然支持通过使用from和size参数进行分页,但是要在有限范围内(within limited) 。还记得每个分片必须构造一个长度为from+size的优先队列吧,所有这些都要传回协调节点。这意味着协调节点要通过对分片数量 * (from + size)个document进行排序来找到正确的size个document。
根据document的数量,分片的数量以及所使用的硬件,对10,000到50,000条结果(1,000到5,000页)深分页是可行的。但是对于足够大的from值,排序过程将会变得非常繁重,会使用巨大量的CPU,内存和带宽。因此,强烈不建议使用深分页。
在实际中,“深分页者”也是很少的一部人。一般人会在翻了两三页后就停止翻页,并会更改搜索标准。那些不正常情况通常是机器人或者网络爬虫的行为。它们会持续不断地一页接着一页地获取页面直到服务器到崩溃的边缘。
如果你确实需要从集群里获取大量documents,你可以通过设置搜索类型scan禁用排序,来高效地做这件事。这一点将在后面的章节讨论。
搜索选项
一些查询字符串(query-string)可选参数能够影响搜索过程。
preference(偏爱)
preference参数允许你控制使用哪个分片或节点来处理搜索请求。她接受如下一些参数 _primary, _primary_first, _local, _only_node:xyz, _prefer_node:xyz和_shards:2,3。然而通常最有用的值是一些随机字符串,它们可以避免结果震荡问题(the bouncing results problem)。
结果震荡(Bouncing Results)
- 想像一下,你正在按照
timestamp字段来对你的结果排序,并且有两个document有相同的timestamp。由于搜索请求是在所有有效的分片副本间轮询的,这两个document可能在原始分片里是一种顺序,在副本分片里是另一种顺序。 - 这就是被称为结果震荡(bouncing results) 的问题:用户每次刷新页面,结果顺序会发生变化。避免这个问题方法是对于同一个用户总是使用同一个分片。方法就是使用一个随机字符串例如用户的会话ID(session ID)来设置
preference参数。
timeout(超时)
通常,协调节点会等待接收所有分片的回答。如果有一个节点遇到问题,它会拖慢整个搜索请求。timeout参数告诉协调节点最多等待多久,就可以放弃等待而将已有结果返回。返回部分结果总比什么都没有好。搜索请求的返回将会指出这个搜索是否超时,以及有多少分片成功答复了:
...
"timed_out": true, (1)
"_shards": {
"total": 5,
"successful": 4,
"failed": 1 (2)
},
...
- 搜索请求超时。
- 五个分片中有一个没在超时时间内答复。
如果一个分片的所有副本都因为其他原因失败了——也许是因为硬件故障——这个也同样会反映在该答复的_shards部分里。
routing(路由选择)
- 在路由值那节里,我们解释了如何在建立索引时提供一个自定义的
routing参数来保证所有相关的document(如属于单个用户的document)被存放在一个单独的分片中。在搜索时,你可以指定一个或多个routing值来限制只搜索那些分片而不是搜索index里的全部分片:GET /_search?routing=user_1,user2 - 这个技术在设计非常大的搜索系统时就会派上用场了。我们在规模(scale)那一章里详细讨论它。
search_type(搜索类型)
- 虽然
query_then_fetch是默认的搜索类型,但也可以根据特定目的指定其它的搜索类型,例如:GET /_search?search_type=count - count(计数):
count(计数)搜索类型只有一个query(查询)的阶段。当不需要搜索结果只需要知道满足查询的document的数量时,可以使用这个查询类型。 - query_and_fetch(查询并且取回):
query_and_fetch(查询并且取回)搜索类型将查询和取回阶段合并成一个步骤。这是一个内部优化选项,当搜索请求的目标只是一个分片时可以使用,例如指定了routing(路由选择)值时。虽然你可以手动选择使用这个搜索类型,但是这么做基本上不会有什么效果。 - dfs_query_then_fetch 和 dfs_query_and_fetch:
dfs搜索类型有一个预查询的阶段,它会从全部相关的分片里取回项目频数来计算全局的项目频数。我们将在relevance-is-broken(相关性被破坏)里进一步讨论这个。 - scan(扫描):
scan(扫描)搜索类型是和scroll(滚屏)API连在一起使用的,可以高效地取回巨大数量的结果。它是通过禁用排序来实现的。我们将在下一节scan-and-scroll(扫描和滚屏) 里讨论它。
扫描和滚屏
scan(扫描)搜索类型是和scroll(滚屏)API一起使用来从Elasticsearch里高效地取回巨大数量的结果而不需要付出深分页的代价。
- scroll(滚屏)
- 一个滚屏搜索允许我们做一个初始阶段搜索并且持续批量从Elasticsearch里拉取结果直到没有结果剩下。这有点像传统数据库里的cursors(游标) 。
- 滚屏搜索会及时制作快照。这个快照不会包含任何在初始阶段搜索请求后对index做的修改。它通过将旧的数据文件保存在手边,所以可以保护index的样子看起来像搜索开始时的样子。
- scan(扫描)
- 深度分页代价最高的部分是对结果的全局排序,但如果禁用排序,就能以很低的代价获得全部返回结果。为达成这个目的,可以采用
scan(扫描)搜索模式。扫描模式让Elasticsearch不排序,只要分片里还有结果可以返回,就返回一批结果。
- 深度分页代价最高的部分是对结果的全局排序,但如果禁用排序,就能以很低的代价获得全部返回结果。为达成这个目的,可以采用
为了使用scan-and-scroll(扫描和滚屏) ,需要执行一个搜索请求,将search_type 设置成scan,并且传递一个scroll参数来告诉Elasticsearch滚屏应该持续多长时间。
GET /old_index/_search?search_type=scan&scroll=1m (1)
{
"query": { "match_all": {}},
"size": 1000
}
- 保持滚屏开启1分钟。
- 这个请求的应答没有包含任何命中的结果,但是包含了一个Base-64编码的
_scroll_id(滚屏id)字符串。现在我们可以将_scroll_id传递给_search/scroll末端来获取第一批结果:GET /_search/scroll?scroll=1m (1) c2Nhbjs1OzExODpRNV9aY1VyUVM4U0NMd2pjWlJ3YWlBOzExOTpRNV9aY1VyUVM4U0 <2> NMd2pjWlJ3YWlBOzExNjpRNV9aY1VyUVM4U0NMd2pjWlJ3YWlBOzExNzpRNV9aY1Vy UVM4U0NMd2pjWlJ3YWlBOzEyMDpRNV9aY1VyUVM4U0NMd2pjWlJ3YWlBOzE7dG90YW xfaGl0czoxOw==
- 这个请求的应答没有包含任何命中的结果,但是包含了一个Base-64编码的
- 保持滚屏开启另一分钟。
_scroll_id可以在body或者URL里传递,也可以被当做查询参数传递。
注意,要再次指定?scroll=1m。滚屏的终止时间会在我们每次执行滚屏请求时刷新,所以他只需要给我们足够的时间来处理当前批次的结果而不是所有的匹配查询的document。
这个滚屏请求的应答包含了第一批次的结果。虽然指定了一个1000的size ,但是获得了更多的document。当扫描时,size被应用到每一个分片上,所以我们在每个批次里最多或获得size * number_of_primary_shards(size*主分片数)个document。
注意:
滚屏请求也会返回一个新 的
_scroll_id。每次做下一个滚屏请求时,必须传递前一次请求返回的_scroll_id。
如果没有更多的命中结果返回,就处理完了所有的命中匹配的document。