何时细分的问题不仅适用于类,而且还适用于方法:是否有时最好将现有方法分为多个较小的方法?还是应该将两种较小的方法合并为一种较大的方法?长方法比短方法更难于理解,因此许多人认为仅长度是分解方法的一个很好的理由。课堂上的学生通常会获得严格的标准,例如“拆分超过 20 行的任何方法!”
但是,长度本身很少是拆分方法的一个很好的理由。通常,开发人员倾向于过多地分解方法。拆分方法会引入其他接口,从而增加了复杂性。它还将原始方法的各个部分分开,如果这些部分实际上是相关的,则使代码更难阅读。您不应该分解一种方法,除非它使整个系统更加简单;我将在下面讨论这种情况。
长方法并不总是坏的。例如,假设一个方法包含按顺序执行的五个 20 行代码块。如果这些块是相对独立的,则可以一次读取并理解该方法的一个块。将每个块移动到单独的方法中并没有太大的好处。如果这些块具有复杂的交互作用,则将它们保持在一起就显得尤为重要,这样读者就可以一次看到所有代码。如果每个块使用单独的方法,则读者将不得不在这些扩展方法之间来回切换,以了解它们如何协同工作。如果方法具有简单的签名并且易于阅读,则包含数百行代码的方法就可以了。这些方法很深入(很多功能,简单的接口),很好。
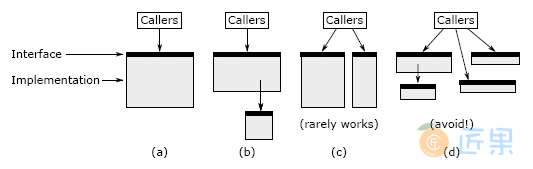
图 9.3:方法(a)可以通过提取子任务(b)或将其功能划分为两个单独的方法(c)进行拆分。如果方法导致浅层方法,则不应拆分该方法,如(d)所示。
设计方法时,最重要的目标是提供简洁的抽象。每种方法都应该做一件事并且完全做到这一点。该方法应该具有简洁的接口,以便用户无需费神就可以正确使用它。该方法应该很深:其接口应该比其实现简单得多。如果一个方法具有所有这些属性,那么它的长短与否可能无关紧要。
总体而言,拆分方法只有在其导致更抽象的抽象时才有意义。有两种方法可以做到这一点,如图 9.3 所示。最佳方法是将子任务分解为单独的方法,如图 9.3(b)所示。该细分产生一个包含该子任务的子方法和一个包含原始方法其余部分的父方法;父级调用子级。新的父方法的接口与原始方法的接口相同。如果存在一个与原始方法的其余部分完全可分离的子任务,则这种细分形式是有意义的,这意味着(a)读取子方法的某人不需要了解有关父方法的任何信息,以及(b)某人在阅读父方法不需要了解子方法的实现。通常,这意味着子方法是相对通用的:可以想象除父方法外,其他方法也可以使用它。如果您对这种形式进行拆分,然后发现自己在父母和孩子之间来回翻转以了解他们如何一起工作,那是一个红色标记(“联合方法”),表明拆分可能不是一个好主意。
分解方法的第二种方法是将其拆分为两个单独的方法,每个方法对原始方法的调用者可见,如图 9.3(c)所示。如果原始方法的接口过于复杂,这是有道理的,因为该接口试图执行不密切相关的多项操作。在这种情况下,可以将方法的功能划分为两个或更多个较小的方法,每个方法仅具有原始方法功能的一部分。如果进行这样的拆分,则每个结果方法的接口应该比原始方法的接口更简单。理想情况下,大多数调用者只需要调用两个新方法之一即可;如果调用者必须同时调用这两个新方法,则将增加复杂性,从而降低拆分是个好主意的可能性。新方法将更加专注于它们的工作。如果新方法比原始方法更具通用性,那么这是一个好兆头(例如,您可以想象在其他情况下单独使用它们)。
图 9.3(c)所示形式的拆分并不是很有意义,因为它们导致调用者不得不处理多个方法而不是一个方法。当您以这种方式拆分时,您可能会遇到几种浅层方法的风险,如图 9.3(d)所示。如果调用者必须调用每个单独的方法,并在它们之间来回传递状态,则拆分不是一个好主意。如果您正在考虑像图 9.3(c)所示的拆分,则应基于它是否简化了呼叫者的情况来进行判断。
在某些情况下,通过将方法结合在一起可以简化系统。例如,连接方法可以用一种更深的方法代替两种浅的方法。它可以消除重复的代码;它可以消除原始方法或中间数据结构之间的依赖关系;它可能导致更好的封装,从而使以前在多个位置存在的知识现在被隔离在一个位置;否则可能会导致接口更简单,如 9.2. 汇集在一起 是否可以简化接口 所述。
应该有可能独立地理解每种方法。如果您不能不理解另一种方法的实现而无法理解一种方法的实现,那就是一个危险信号。该危险信号也可以在其他情况下发生:如果两段代码在物理上是分开的,但是只有通过查看另一段代码才能理解它们,这就是危险信号。
拆分或加入模块的决定应基于复杂性。选择一种结构,它可以隐藏最佳的信息,最少的依赖关系和最深的接口。
The issue of when to subdivide applies not just to classes, but also to methods: are there times when it is better to divide an existing method into multiple smaller methods? Or, should two smaller methods be combined into one larger one? Long methods tend to be more difficult to understand than shorter ones, so many people argue that length alone is a good justification for breaking up a method. Students in classes are often given rigid criteria, such as “Split up any method longer than 20 lines!”
However, length by itself is rarely a good reason for splitting up a method. In general, developers tend to break up methods too much. Splitting up a method introduces additional interfaces, which add to complexity. It also separates the pieces of the original method, which makes the code harder to read if the pieces are actually related. You shouldn’t break up a method unless it makes the overall system simpler; I’ll discuss how this might happen below.
Long methods aren’t always bad. For example, suppose a method contains five 20-line blocks of code that are executed in order. If the blocks are relatively independent, then the method can be read and understood one block at a time; there’s not much benefit in moving each of the blocks into a separate method. If the blocks have complex interactions, it’s even more important to keep them together so readers can see all of the code at once; if each block is in a separate method, readers will have to flip back and forth between these spread-out methods in order to understand how they work together. Methods containing hundreds of lines of code are fine if they have a simple signature and are easy to read. These methods are deep (lots of functionality, simple interface), which is good.
Figure 9.3: A method (a) can be split either by by extracting a subtask (b) or by dividing its functionality into two separate methods (c). A method should not be split if it results in shallow methods, as in (d).
When designing methods, the most important goal is to provide clean and simple abstractions. Each method should do one thing and do it completely. The method should have a clean and simple interface, so that users don’t need to have much information in their heads in order to use it correctly. The method should be deep: its interface should be much simpler than its implementation. If a method has all of these properties, then it probably doesn’t matter whether it is long or not.
Splitting up a method only makes sense if it results in cleaner abstractions, overall. There are two ways to do this, which are diagrammed in Figure 9.3. The best way is by factoring out a subtask into a separate method, as shown in Figure 9.3(b). The subdivision results in a child method containing the subtask and a parent method containing the remainder of the original method; the parent invokes the child. The interface of the new parent method is the same as the original method. This form of subdivision makes sense if there is a subtask that is cleanly separable from the rest of the original method, which means (a) someone reading the child method doesn’t need to know anything about the parent method and (b) someone reading the parent method doesn’t need to understand the implementation of the child method. Typically this means that the child method is relatively general-purpose: it could conceivably be used by other methods besides the parent. If you make a split of this form and then find yourself flipping back and forth between the parent and child to understand how they work together, that is a red flag (“Conjoined Methods”) indicating that the split was probably a bad idea.
The second way to break up a method is to split it into two separate methods, each visible to callers of the original method, as in Figure 9.3(c). This makes sense if the original method had an overly complex interface because it tried to do multiple things that were not closely related. If this is the case, it may be possible to divide the method’s functionality into two or more smaller methods, each of which has only a part of the original method’s functionality. If you make a split like this, the interface for each of the resulting methods should be simpler than the interface of the original method. Ideally, most callers should only need to invoke one of the two new methods; if callers must invoke both of the new methods, then that adds complexity, which makes it less likely that the split is a good idea. The new methods will be more focused in what they do. It is a good sign if the new methods are more general-purpose than the original method (i.e., you can imagine using them separately in other situations).
Splits of the form shown in Figure 9.3(c) don’t make sense very often, because they result in callers having to deal with multiple methods instead of one. When you split this way, you run the risk of ending up with several shallow methods, as in Figure 9.3(d). If the caller has to invoke each of the separate methods, passing state back and forth between them, then splitting is not a good idea. If you’re considering a split like the one in Figure 9.3(c), you should judge it based on whether it simplifies things for callers.
There are also situations where a system can be made simpler by joining methods together. For example, joining methods might replace two shallow methods with one deeper method; it might eliminate duplication of code; it might eliminate dependencies between the original methods, or intermediate data structures; it might result in better encapsulation, so that knowledge that was previously present in multiple places is now isolated in a single place; or it might result in a simpler interface, as discussed in Section 9.2.
It should be possible to understand each method independently. If you can’t understand the implementation of one method without also understanding the implementation of another, that’s a red flag. This red flag can occur in other contexts as well: if two pieces of code are physically separated, but each can only be understood by looking at the other, that is a red flag.
The decision to split or join modules should be based on complexity. Pick the structure that results in the best information hiding, the fewest dependencies, and the deepest interfaces.