减少与异常相关的复杂性的第三种技术是异常聚合。异常聚合的思想是用一个代码段处理许多异常。与其为多个单独的异常编写不同的处理程序,不如用一个处理程序将它们全部处理在一个地方。
考虑如何处理 Web 服务器中缺少的参数。Web 服务器实现 URL 的集合。服务器收到传入的 URL 时,将分派到特定于 URL 的服务方法来处理该 URL 并生成响应。该 URL 包含用于生成响应的各种参数。每个服务方法都将调用一个较低层的方法(将其称为 getParameter)以从 URL 中提取所需的参数。如果 URL 不包含所需的参数,则 getParameter 会引发异常。
当参加软件设计课程的学生实现这样的服务器时,他们中的许多人将对 getParameter 的每个不同调用包装在单独的异常处理程序中以捕获 NoSuchParameter 异常,如图 10.1 所示。这导致大量的处理程序,所有这些处理程序基本上都执行相同的操作(生成错误响应)。
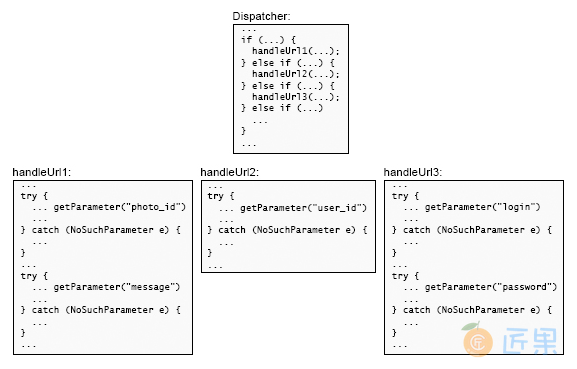
图 10.1:顶部的代码将分派给 Web 服务器中的几种方法之一,每种方法都处理一个特定的 URL。每个方法(底部)都使用传入 HTTP 请求中的参数。在此图中,每个对 getParameter 的调用都有一个单独的异常处理程序。这导致重复的代码。
更好的方法是汇总异常。让它们传播到 Web 服务器的顶级调度方法,而不是在单个服务方法中捕获异常,如图 10.2 所示。此方法中的单个处理程序可以捕获所有异常,并为丢失的参数生成适当的错误响应。
在 Web 示例中甚至可以采用聚合方法。处理网页时,除了缺少参数外,还有许多其他错误;例如,参数可能没有正确的语法(服务方法应为整数,但值为“ xyz”),或者用户可能无权执行所请求的操作。在每种情况下,错误都应导致错误响应。错误仅在响应中包含的错误消息中有所不同(“ URL 中不存在参数’数量’”或“’数量’参数的错误值’xyz’;必须为正整数”)。因此,所有导致错误响应的条件都可以使用单个顶级异常处理程序进行处理。错误消息可以在引发异常时生成,并作为变量包含在异常记录中。例如,getParameter 将生成“ URL 中不存在的参数’数量’”消息。顶级处理程序从异常中提取消息,并将其合并到错误响应中。

图 10.2:此代码在功能上等效于图 10.1,但是异常处理已聚合:分派器中的单个异常处理程序从所有特定于 URL 的方法中捕获所有 NoSuchParameter 异常。
从封装和信息隐藏的角度来看,上一段中描述的聚合具有良好的属性。顶级异常处理程序封装了有关如何生成错误响应的知识,但对特定错误一无所知。它仅使用异常中提供的错误消息。getParameter 方法封装了有关如何从 URL 提取参数的知识,并且还知道如何以人类可读的形式描述提取错误。这两个信息密切相关,因此将它们放在同一位置是很有意义的。但是,getParameter 对 HTTP 错误响应的语法一无所知。随着向 Web 服务器中添加了新功能,可能会创建具有类似自身错误的新方法,如 getParameter。
此示例说明了用于异常处理的通用设计模式。如果系统处理一系列请求,则定义一个异常以中止当前请求,清除系统状态并继续下一个请求非常有用。异常被捕获在系统请求处理循环顶部附近的单个位置。在处理中止请求的任何时候都可以抛出该异常。可以为不同的条件定义异常的不同子类。应该将这种类型的异常与对整个系统致命的异常区分开来。
如果异常在处理之前在堆栈中传播了多个级别,则异常聚集最有效。这样可以在同一位置处理更多方法的更多异常。这与异常屏蔽相反:如果使用低级方法处理异常,则屏蔽通常效果最好。对于屏蔽,低级方法通常是许多其他方法使用的库方法,因此,允许传播异常会增加处理该异常的位置数。掩码和聚合的相似之处在于,这两种方法都将异常处理程序置于可以捕获最多异常的位置,从而消除了许多本来需要创建的处理程序。
RAMCloud 存储系统中发生异常聚集的另一个示例是崩溃恢复。RAMCloud 系统由一组存储服务器组成,这些存储服务器保留每个对象的多个副本,因此系统可以从各种故障中恢复。例如,如果服务器崩溃并丢失其所有数据,RAMCloud 会使用存储在其他服务器上的副本来重建丢失的数据。错误也可能在较小的范围内发生。例如,服务器可能发现单个对象已损坏。
对于每种不同类型的错误,RAMCloud 没有单独的恢复机制。相反,RAMCloud 将许多较小的错误“提升”为较大的错误。原则上,RAMCloud 可以通过从备份副本中恢复一个损坏的对象来处理这个损坏的对象。然而,它并不这样做。相反,如果它发现一个损坏的对象,它会使包含该对象的服务器崩溃。RAMCloud 使用这种方法是因为崩溃恢复非常复杂,而且这种方法最小化了必须创建的不同恢复机制的数量。为崩溃的服务器创建恢复机制是不可避免的,因此 RAMCloud 对其他类型的恢复也使用相同的机制。这减少了必须编写的代码量,而且这还意味着服务器崩溃恢复将更频繁地被调用。因此,恢复中的 bug 更有可能被发现和修复。
将损坏的对象升级为服务器崩溃的一个缺点是,它大大增加了恢复成本。这在 RAMCloud 中不是问题,因为对象损坏非常罕见。但是,错误升级对于经常发生的错误可能没有意义。举一个例子,在服务器的任何网络数据包丢失时使服务器崩溃是不切实际的。
考虑异常聚合的一种方法是,它用可以处理多种情况的单个通用机制替换了几种针对特定情况而量身定制的特殊用途的机制。这再次说明了通用机制的好处。
The third technique for reducing complexity related to exceptions is exception aggregation. The idea behind exception aggregation is to handle many exceptions with a single piece of code; rather than writing distinct handlers for many individual exceptions, handle them all in one place with a single handler.
Consider how to handle missing parameters in a Web server. A Web server implements a collection of URLs. When the server receives an incoming URL, it dispatches to a URL-specific service method to process that URL and generate a response. The URL contains various parameters that are used to generate the response. Each service method will call a lower-level method (let’s call it getParameter) to extract the parameters that it needs from the URL. If the URL does not contain the desired parameter, getParameter throws an exception.
When students in a software design class implemented such a server, many of them wrapped each distinct call to getParameter in a separate exception handler to catch NoSuchParameter exceptions, as in Figure 10.1. This resulted in a large number of handlers, all of which did essentially the same thing (generate an error response).
Figure 10.1: The code at the top dispatches to one of several methods in a Web server, each of which handles a particular URL. Each of those methods (bottom) uses parameters from the incoming HTTP request. In this figure, there is a separate exception handler for each call to getParameter; this results in duplicated code.
A better approach is to aggregate the exceptions. Instead of catching the exceptions in the individual service methods, let them propagate up to the top-level dispatch method for the Web server, as in Figure 10.2. A single handler in this method can catch all of the exceptions and generate an appropriate error response for missing parameters.
The aggregation approach can be taken even further in the Web example. There are many other errors besides missing parameters that can occur while processing a Web page; for example, a parameter might not have the right syntax (the service method expected an integer, but the value was “xyz”), or the user might not have permission for the requested operation. In each case, the error should result in an error response; the errors differ only in the error message to include in the response (“parameter ‘quantity’ not present in URL” or “bad value ‘xyz’ for ‘quantity’ parameter; must be positive integer”). Thus, all conditions resulting in an error response can be handled with a single top-level exception handler. The error message can be generated at the time the exception is thrown and included as a variable in the exception record; for example, getParameter will generate the “parameter ‘quantity’ not present in URL” message. The top-level handler extracts the message from the exception and incorporates it into the error response.
Figure 10.2: This code is functionally equivalent to Figure 10.1, but exception handling has been aggregated: a single exception handler in the dispatcher catches all of the NoSuchParameter exceptions from all of the URL-specific methods.
The aggregation described in the preceding paragraph has good properties from the standpoint of encapsulation and information hiding. The top-level exception handler encapsulates knowledge about how to generate error responses, but it knows nothing about specific errors; it just uses the error message provided in the exception. The getParameter method encapsulates knowledge about how to extract a parameter from a URL, and it also knows how to describe extraction errors in a human-readable form. These two pieces of information are closely related, so it makes sense for them to be in the same place. However, getParameter knows nothing about the syntax of an HTTP error response. As new functionality is added to the Web server, new methods like getParameter may be created with their own errors. If the new methods throw exceptions in the same way as getParameter (by generating exceptions that inherit from the same superclass and including an error message in each exception), they can plug into the existing system with no other changes: the top-level handler will automatically generate error responses for them.
This example illustrates a generally-useful design pattern for exception handling. If a system processes a series of requests, it’s useful to define an exception that aborts the current request, cleans up the system’s state, and continues with the next request. The exception is caught in a single place near the top of the system’s request-handling loop. This exception can be thrown at any point in the processing of a request to abort the request; different subclasses of the exception can be defined for different conditions. Exceptions of this type should be clearly distinguished from exceptions that are fatal to the entire system.
Exception aggregation works best if an exception propagates several levels up the stack before it is handled; this allows more exceptions from more methods to be handled in the same place. This is the opposite of exception masking: masking usually works best if an exception is handled in a low-level method. For masking, the low-level method is typically a library method used by many other methods, so allowing the exception to propagate would increase the number of places where it is handled. Masking and aggregation are similar in that both approaches position an exception handler where it can catch the most exceptions, eliminating many handlers that would otherwise need to be created.
Another example of exception aggregation occurs in the RAMCloud storage system for crash recovery. A RAMCloud system consists of a collection of storage servers that keep multiple copies of each object, so the system can recover from a variety of failures. For example, if a server crashes and loses all of its data, RAMCloud reconstructs the lost data using copies stored on other servers. Errors can also happen on a smaller scale; for example, a server may discover that an individual object is corrupted.
RAMCloud does not have separate recovery mechanisms for each different kind of error. Instead, RAMCloud “promotes” many smaller errors into larger ones. RAMCloud could, in principle, handle a corrupted object by restoring that one object from a backup copy. However, it doesn’t do this. Instead, if it discovers a corrupted object it crashes the server containing the object. RAMCloud uses this approach because crash recovery is quite complex and this approach minimized the number of different recovery mechanisms that had to be created. Creating a recovery mechanism for crashed servers was unavoidable, so RAMCloud uses the same mechanism for other kinds of recovery as well. This reduced the amount of code that had to be written, and it also meant that server crash recovery gets invoked more often. As a result, bugs in recovery are more likely to be discovered and fixed.
One disadvantage of promoting a corrupted object into a server crash is that it increases the cost of recovery considerably. This is not a problem in RAMCloud, since object corruption is quite rare. However, error promotion may not make sense for errors that happen frequently. As one example, it would not be practical to crash a server anytime one of its network packets is lost.
One way of thinking about exception aggregation is that it replaces several special-purpose mechanisms, each tailored for a particular situation, with a single general-purpose mechanism that can handle multiple situations. This provides another illustration of the benefits of general-purpose mechanisms.