WHAT: 用来监控容器内部使用资源的信息
# 200机器,下载镜像:
~]# docker pull google/cadvisor:v0.28.3
~]# docker images|grep cadvisor
~]# docker tag 75f88e3ec33 harbor.od.com/public/cadvisor:v0.28.3
~]# docker push harbor.od.com/public/cadvisor:v0.28.3
~]# mkdir /data/k8s-yaml/cadvisor/
~]# cd /data/k8s-yaml/cadvisor/
cadvisor]# vi ds.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: cadvisor
namespace: kube-system
labels:
app: cadvisor
spec:
selector:
matchLabels:
name: cadvisor
template:
metadata:
labels:
name: cadvisor
spec:
hostNetwork: true
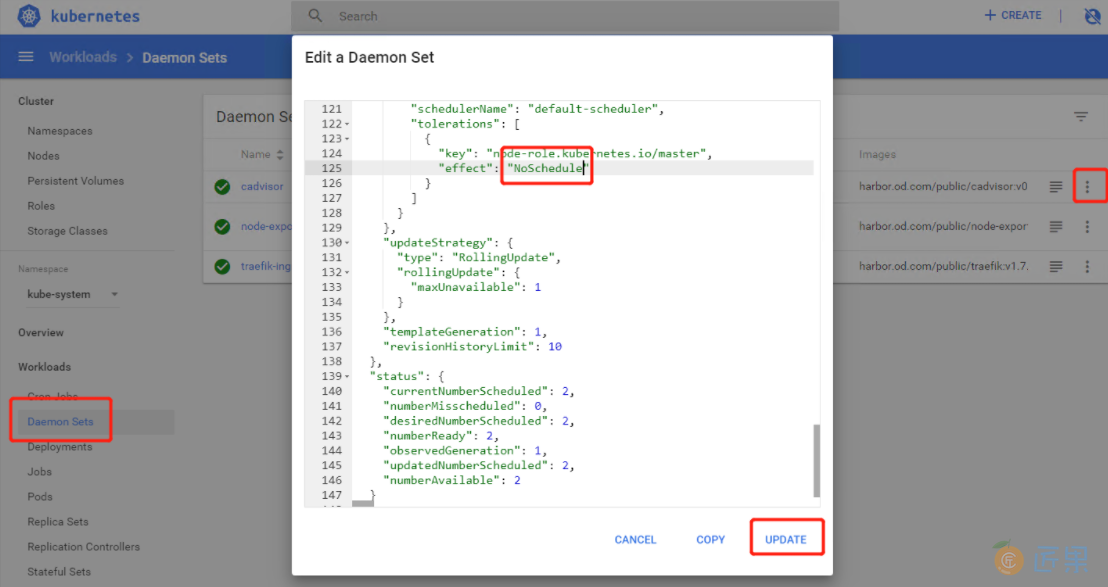
tolerations:
- key: node-role.kubernetes.io/master
effect: NoExecute
containers:
- name: cadvisor
image: harbor.od.com/public/cadvisor:v0.28.3
imagePullPolicy: IfNotPresent
volumeMounts:
- name: rootfs
mountPath: /rootfs
readOnly: true
- name: var-run
mountPath: /var/run
- name: sys
mountPath: /sys
readOnly: true
- name: docker
mountPath: /var/lib/docker
readOnly: true
ports:
- name: http
containerPort: 4194
protocol: TCP
readinessProbe:
tcpSocket:
port: 4194
initialDelaySeconds: 5
periodSeconds: 10
args:
- --housekeeping_interval=10s
- --port=4194
terminationGracePeriodSeconds: 30
volumes:
- name: rootfs
hostPath:
path: /
- name: var-run
hostPath:
path: /var/run
- name: sys
hostPath:
path: /sys
- name: docker
hostPath:
path: /data/docker
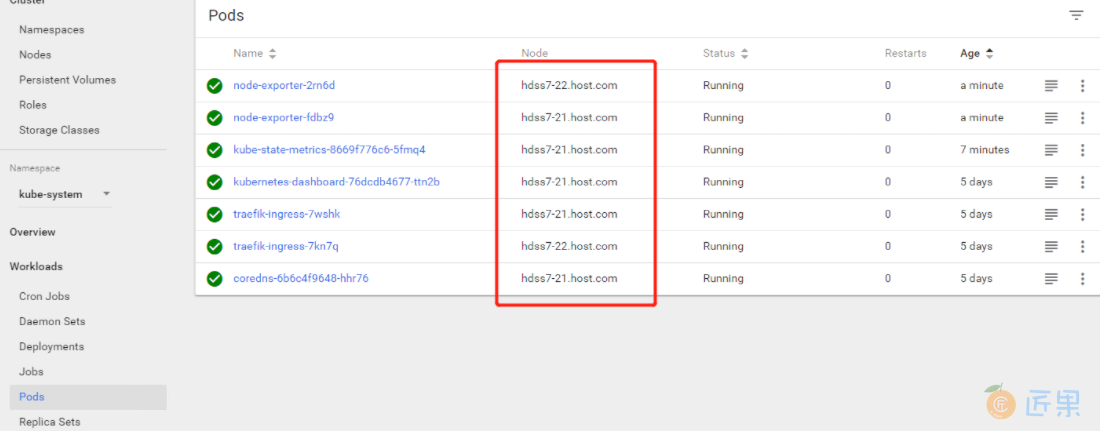
此时我们看到大多数节点都运行在21机器上,我们人为的让pod调度到22机器(当然即使你的大多数节点都运行在22机器上也没关系) 可人为影响K8S调度策略的三种方法:
- 污点、容忍方法:
- 污点:运算节点node上的污点(先在运算节点上打标签等 kubectl taint nodes node1 key1=value1:NoSchedule),污点可以有多个
- 容忍度:pod是否能够容忍污点
- 参考kubernetes官网
- nodeName:让Pod运行再指定的node上
- nodeSelector:通过标签选择器,让Pod运行再指定的一类node上
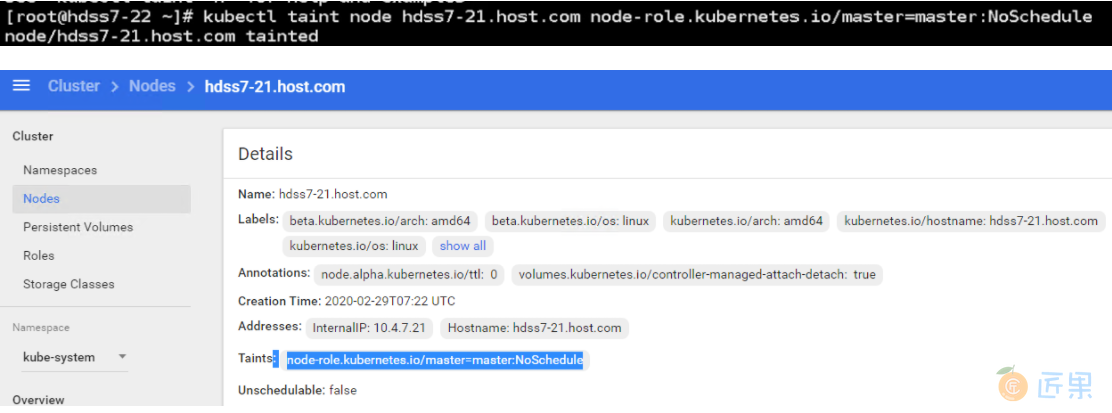
# 给21机器打个污点,22机器:
~]# kubectl taint node hdss7-21.host.com node-role.kubernetes.io/master=master:NoSchedule
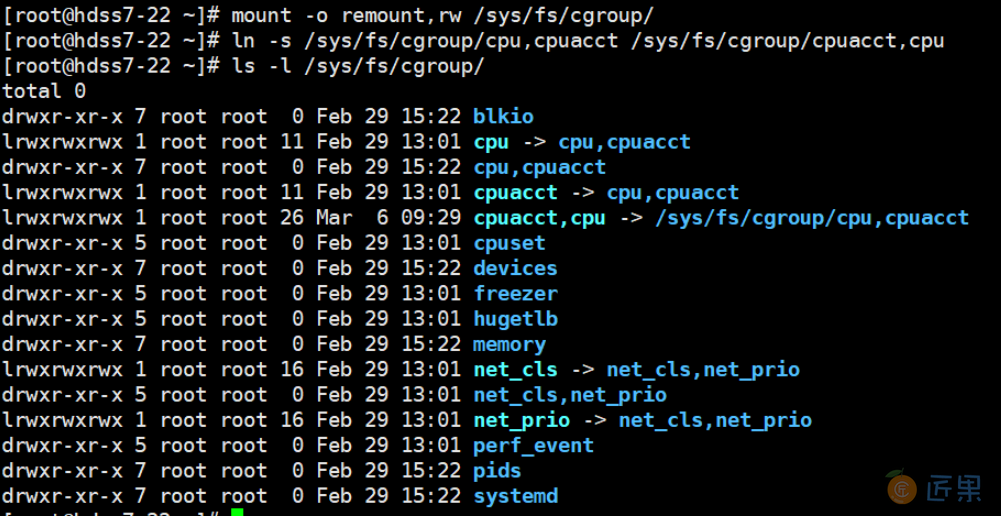
# 21/22两个机器,修改软连接:
~]# mount -o remount,rw /sys/fs/cgroup/
~]# ln -s /sys/fs/cgroup/cpu,cpuacct /sys/fs/cgroup/cpuacct,cpu
~]# ls -l /sys/fs/cgroup/
mount -o remount, rw /sys/fs/cgroup :重新以可读可写的方式挂载为已经挂载/sys/fs/cgroup
ln -s :创建对应的软链接
ls -l :显示不隐藏的文件与文件夹的详细信息
# 22机器,应用资源清单:
~]# kubectl apply -f http://k8s-yaml.od.com/cadvisor/ds.yaml
~]# kubectl get pods -n kube-system -o wide
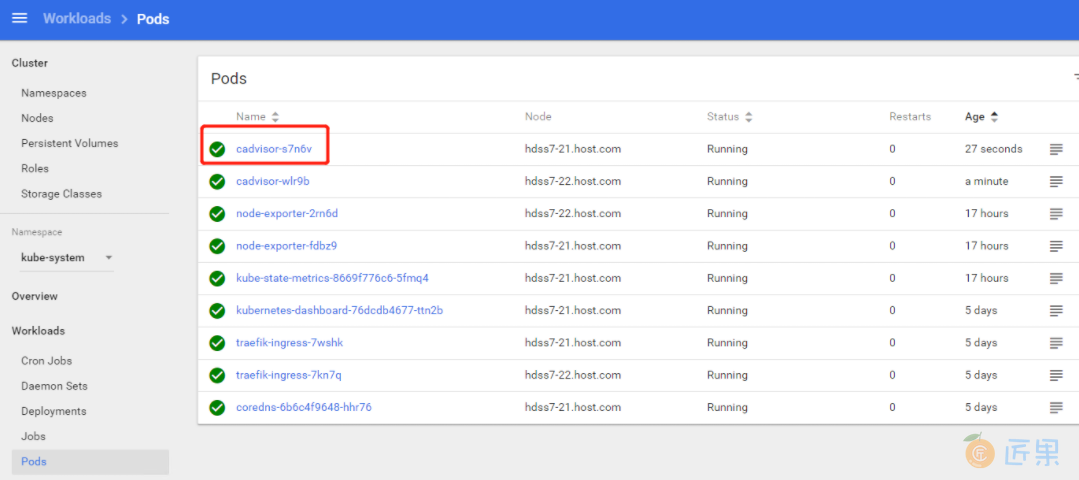
只有22机器上有,跟我们预期一样

# 21机器,我们删掉污点:
~]# kubectl taint node hdss7-21.host.com node-role.kubernetes.io/master-
# out: node/hdss7-21.host.com untainted
看dashboard,污点已经没了
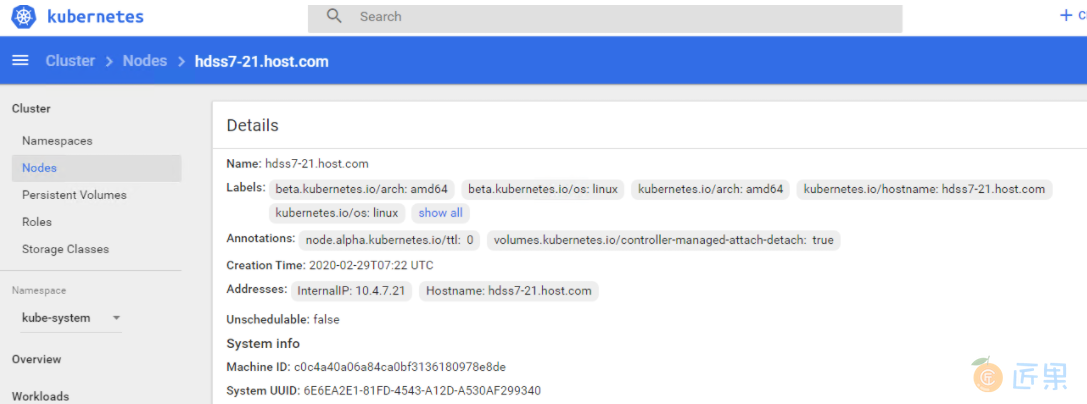
在去Pods看,污点没了,pod就自动起来了
下一节:WHAT:监控业务容器存活性