WHAT :ELK是三个开源软件的缩写,分别是:
- E——Elasticsearch:分布式搜索引擎,提供搜集、分析、存储数据三大功能。
- L——LogStash:对日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。
- K——Kibana:为 Logstash 和 Elasticsearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
- 还有新增的FileBeat(流式日志收集器):轻量级的日志收集处理工具,占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具,用来替代部分原本Logstash的工作。收集日志的多种方式及原理
WHY : 随着容器编排的进行,业务容器在不断的被创建、摧毁、迁移、扩容缩容等,面对如此海量的数据,又分布在各个不同的地方,我们不可能用传统的方法登录到每台机器看,所以我们需要建立一套集中的方法。我们需要这样一套日志手机、分析的系统:
- 收集——采集多种来源的日志数据(流式日志收集器)
- 传输——稳定的把日志数据传输到中央系统(消息队列)
- 存储——将日志以结构化数据的形式存储起来(搜索引擎)
- 分析——支持方便的分析、检索等,有GUI管理系统(前端)
- 警告——提供错误报告,监控机制(监控工具)
这就是ELK
ELK Stack概述
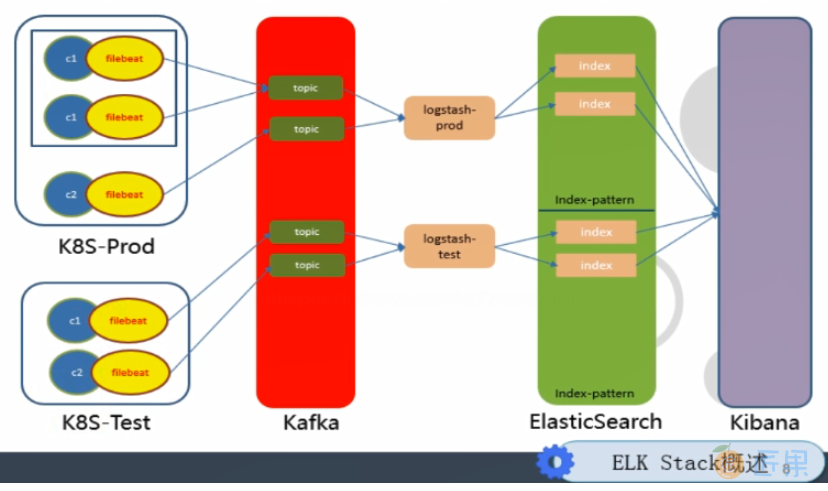
c1/c2 :container(容器)的缩写
filebeat :收集业务容器的日志,把c和filebeat放在一个pod里让他们一起跑,这样耦合就紧了
kafka :高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。filebeat收集数据以Topic形式发布到kafka。
Topic :Kafka数据写入操作的基本单元
logstash :取kafka里的topic,然后再往Elasticsearch上传(异步过程,即又取又传)
index-pattern :把数据按环境分(按prod和test分),并传到kibana
kibana :展示数据