开源监控告警解决方案,推荐文章
当然一时半会你可能没那么快的去理解,那就跟我们先做下去你就会慢慢理解什么是时间序列数据
Prometheus的特点:
- 多维数据模型:由度量名称和键值对标识的时间序列数据
- 内置时间序列数据库:TSDB
- promQL:一种灵活的查询语言,可以利用多维数据完成复杂查询
- 基于HTTP的pull(拉取)方式采集时间序列数据
- 同时支持PushGateway组件收集数据
- 通过服务发现或静态配置发现目标
- 支持作为数据源接入Grafana
我们将使用的官方架构图
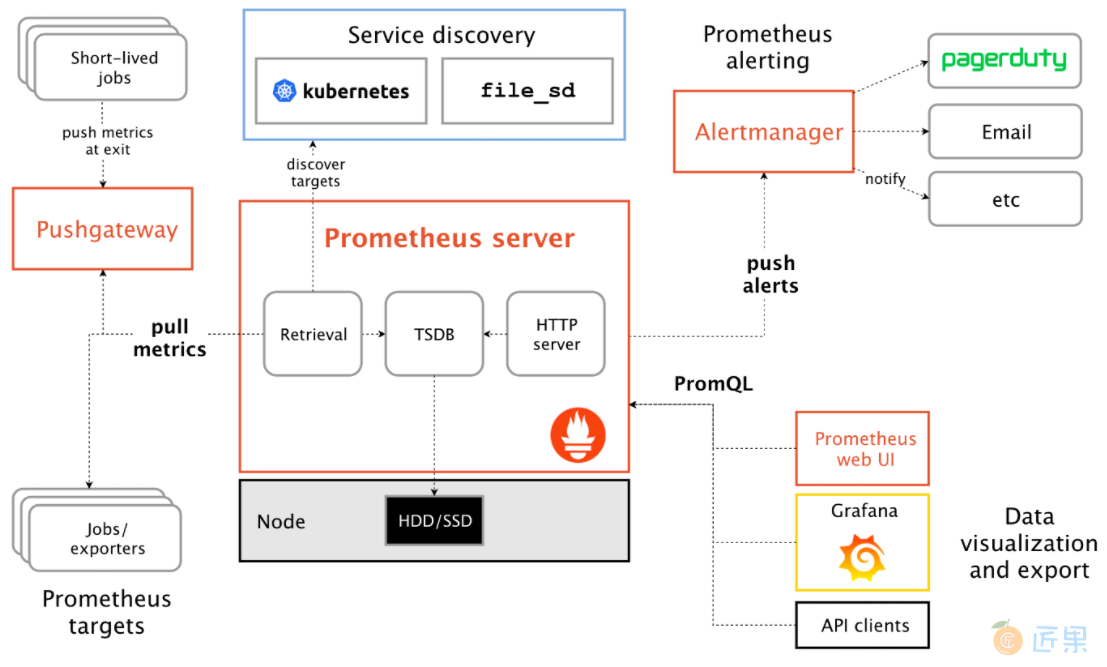
Prometheus Server :服务核心组件,通过pull metrics从 Exporter 拉取和存储监控数据,并提供一套灵活的查询语言(PromQL)。
pushgateway :类似一个中转站,Prometheus的server端只会使用pull方式拉取数据,但是某些节点因为某些原因只能使用push方式推送数据,那么它就是用来接收push而来的数据并暴露给Prometheus的server拉取的中转站,这里我们不做它。
Exporters/Jobs :负责收集目标对象(host, container…)的性能数据,并通过 HTTP 接口供 Prometheus Server 获取。
Service Discovery :服务发现,Prometheus支持多种服务发现机制:文件,DNS,Consul,Kubernetes,OpenStack,EC2等等。基于服务发现的过程并不复杂,通过第三方提供的接口,Prometheus查询到需要监控的Target列表,然后轮训这些Target获取监控数据。
Alertmanager :从 Prometheus server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对方的接受方式,发出报警。常见的接收方式有:电子邮件,pagerduty 等。
UI页面的三种方法 :
- Prometheus Web UI:自带的(不怎么好用)
- Grafana:美观、强大的可视化监控指标展示工具
- API clients:自己开发的监控展示工具
工作流程 :Prometheus Server定期从配置好的Exporters/Jobs中拉metrics,或者来着pushgateway发过来的metrics,或者其它的metrics,收集完后运行定义好的alert.rules(这个文件后面会讲到),记录时间序列或者向Alertmanager推送警报。更多了解Prometheus、Metrics Server与Kubernetes监控体系
和zabbixc对比
| Prometheus | Zabbix |
|---|---|
| 后端用golang开发,K8S也是go开发 | 后端用C开发,界面用PHP开发 |
| 更适合云环境的监控,尤其是对K8S有着更好的支持 | 更适合监控物理机,虚拟机环境 |
| 监控数据存储在基于时间序列的数据库内,便于对已有数据进行新的聚合 | 监控数据存储在关系型数据库内,如MySQL,很难从现有数据中扩展维度 |
| 自身界面相对较弱,很多配置需要修改配置文件,但可以借由Grafana出图 | 图形化界面相对比较成熟 |
| 支持更大的集群规模,速度也更快 | 集群规模上线为10000个节点 |
| 2015年后开始快速发展,社区活跃,使用场景越来越多 | 发展实际更长,对于很多监控场景,都有现成的解决方案 |
由于资源问题,我已经把不用的服务关掉了
下一节:WHAT:为prometheus采集k8s资源数据的exporter,能够采集绝大多数k8s内置资源的相关数据,例如pod、deploy、service等等。同时它也提供自己的数据,主要是资源采集个数和采集发生的异常次数统计